NVIDIA 发布了 Nemotron-4 340B 开源模型家族,该模型主要用于生成高质量的合成数据,从而提高自定义大语言模型的性能和准确性。帮助训练大语言模型(LLMs)。
开发者可以用它来生成合成数据,以训练适用于各种行业(如医疗、金融、制造和零售等)的大型语言模型(LLMs)。
模型家族
Nemotron-4 340B 包括 Nemotron-4-340B-Base、Nemotron-4-340B-Instruct 和 Nemotron-4-340B-Reward。
- Nemotron-4-340B-Base:基础模型,用于广泛的通用任务。
- Nemotron-4-340B-Instruct:指令模型,优化了对指令的遵循和对话能力,主要用于合成数据。
- Nemotron-4-340B-Reward:奖励模型,专门用于评估和提高合成数据质量。
 Nemotron-4 340B Instruct模型
Nemotron-4 340B Instruct模型
用途:
- 生成多样化的合成数据,这些数据模仿现实世界的数据特征。
- 提高定制大型语言模型(LLMs)的数据质量,使其在各个领域的性能和鲁棒性得到提升。
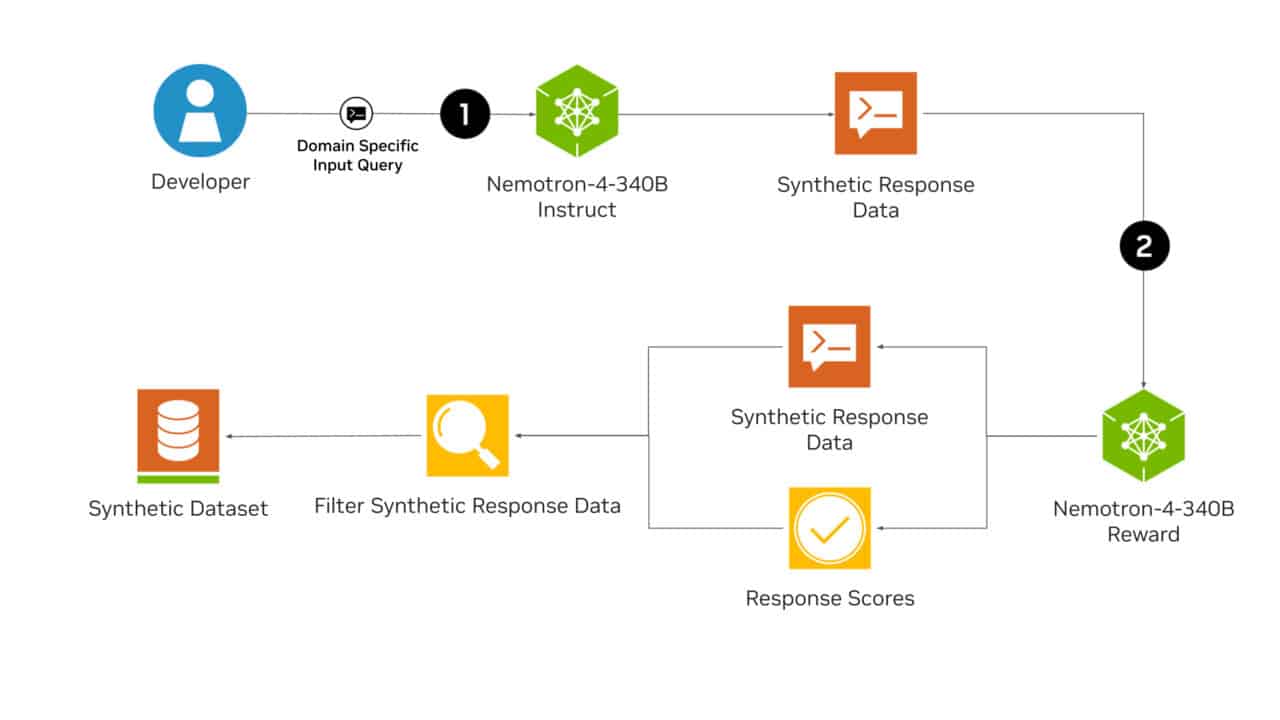
工作流程:
- 首先生成合成文本输出,这些输出尽可能与真实数据相似。
- 这些生成的数据可以用于在访问大量多样化标记数据有限的情况下进行LLM训练。
Nemotron-4 340B Reward模型
用途:
- 对由Instruct模型生成的合成数据进行评估和筛选。
- 提升AI生成数据的质量,确保输出符合特定要求并具有较高的可靠性。
工作流程:
- 评估Instruct模型生成的文本,提供反馈以指导后续改进。
- 根据五个属性对生成的数据进行评分:有用性、正确性、一致性、复杂性和冗长性。
- 帮助过滤并保留高质量的响应数据,从而优化合成数据的整体质量。
技术细节
Nemotron-4 340B Instruct Model
主要功能:
- 生成合成数据:用于创建多样化的合成数据,模拟真实世界数据的特征,提高自定义大语言模型(LLMs)的性能和鲁棒性。
- 优化和对齐:通过多轮对话和偏好优化,使生成的数据更符合人类偏好,提高模型的对话质量、指令跟随能力和数学推理能力。
技术细节:
- 架构:标准仅解码Transformer架构,支持最长4096个token的上下文长度。
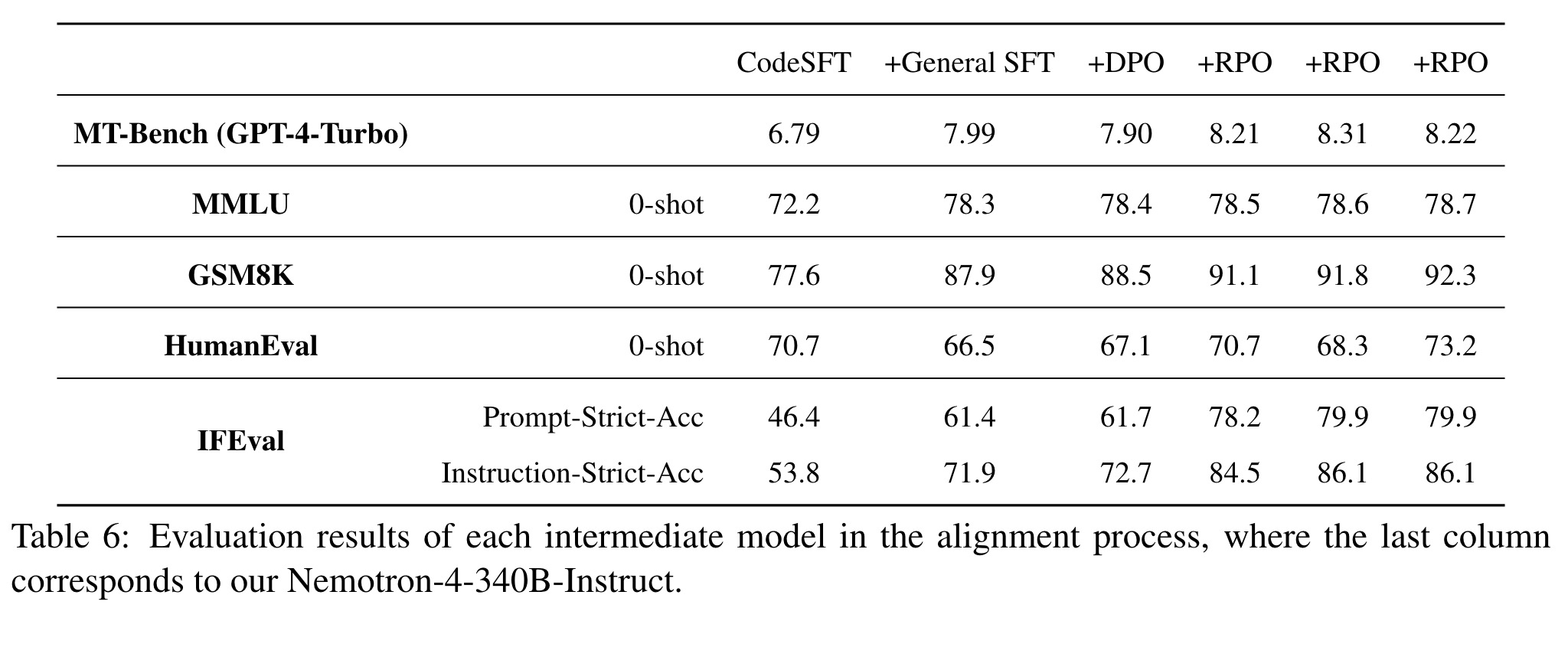
- 训练数据:预训练在9万亿token上,包含多种语言和编程语言的多样化文本。微调使用了监督微调(SFT)、直接偏好优化(DPO)和奖励感知偏好优化(RPO)。
- 硬件要求:推理时需要8个H200节点、16个H100节点或16个A100 80GB节点。
评估结果:
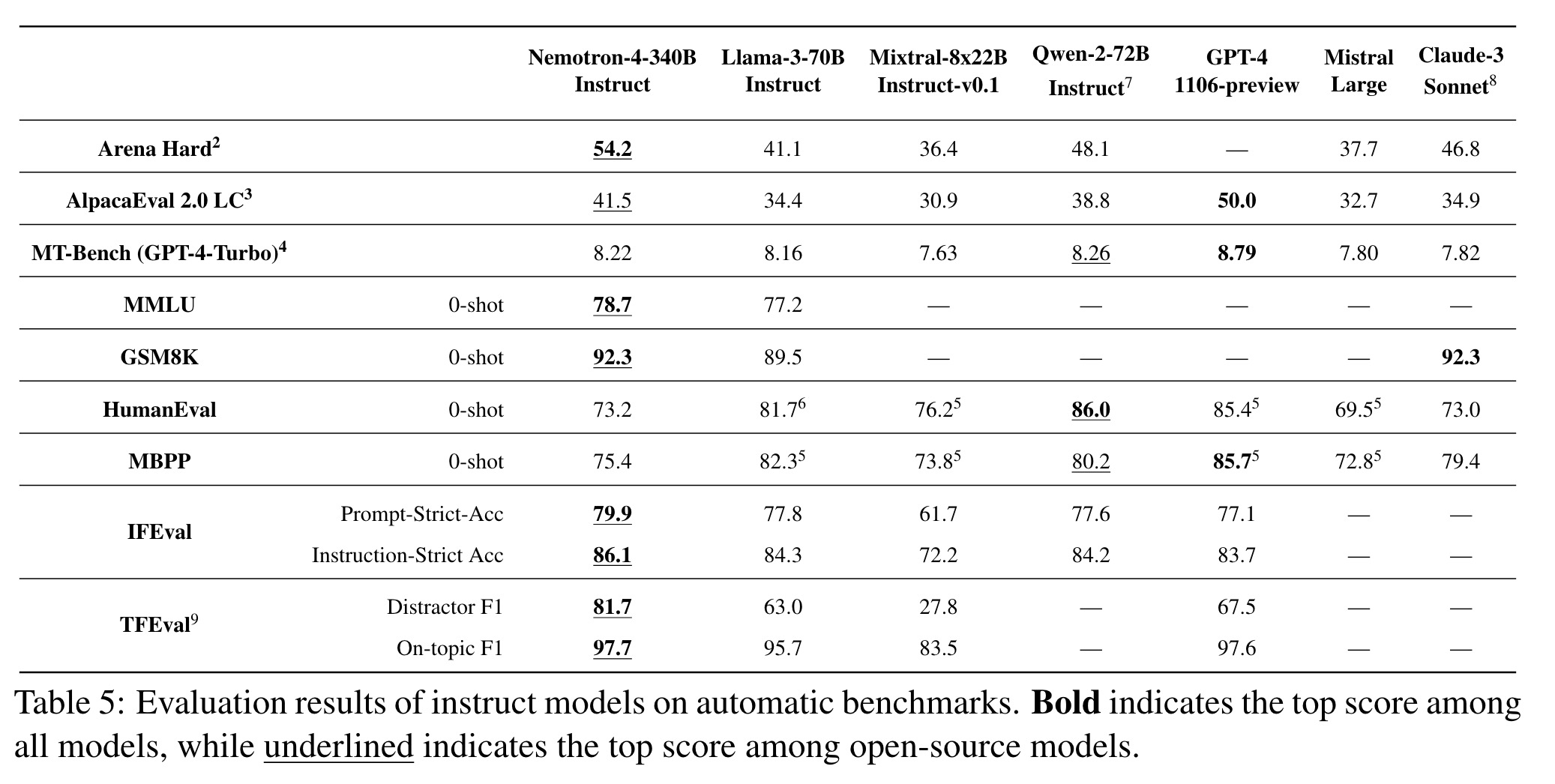
- MT-Bench(GPT-4-Turbo):总分8.22,具体评分包括写作8.70、角色扮演8.70、提取9.20、STEM 8.75等。
- Instruction Following Eval (IFEval):Prompt-Strict准确率79.9%,Instruction-Strict准确率86.1%。指令跟随评估(IFEval):Prompt-Strict 准确率 79.9%,Instruction-Strict 准确率 86.1%。
- Multi-task Language Understanding (MMLU):零样本(0-shot)表现为78.7%。多任务语言理解(MMLU):零样本(0-shot)表现为 78.7%。
- GSM8K:零样本表现为92.3%。
- HumanEval:零样本表现为73.2%。
- MBPP:零样本表现为75.4%。
- 其他:包括Arena Hard、AlpacaEval 2.0 LC、TFEval等基准测试,展示了模型在不同任务上的强大能力。
Nemotron-4 340B Reward Model
主要功能:
- 多维度评分:对生成的响应进行多维度评分,包括帮助性、正确性、连贯性、复杂性和冗长度,确保合成数据的质量。
- 模型对齐:用于对齐预训练模型与人类偏好,提高模型输出的相关性和准确性。
- 奖励模型的评估:作为评判标准,优化模型行为,特别是在AI反馈强化学习(RLAIF)场景中。
技术细节:
- 架构:基于Nemotron-4 340B-Base模型扩展,增加了一个线性层,将最终层的响应token表示转换为五个标量值。
- 训练数据:使用NVIDIA HelpSteer2数据集进行训练,该数据集包含一万对英文响应对话。模型经过2个epoch的训练。
- 硬件要求:推理时需要16个H100节点或16个A100 80GB节点。
评估结果:
- RewardBench基准测试:总体评分为92.0,具体评分包括聊天95.8、困难聊天87.1、安全性91.5、推理93.7。
- 局限性:模型主要针对英语数据进行训练,其他语言域需要进行微调。
合成数据生成步骤
1. 提示生成
首先,模型会生成各种各样的提示(问题或指令),以确保覆盖不同的场景和任务。提示的生成包括:
- 单一问题提示:生成单个问题或指令,如“什么是机器学习?”或“写一篇关于机器学习的文章。”
- 指令提示:生成明确要求输出格式的提示,比如“输出必须是JSON格式。”
- 对话提示:生成包含多个用户和助手互动的提示,以模拟真实对话。
2. 对话生成
为了让模型学会如何进行对话,系统会生成多个回合的对话:
- 模拟对话:模型会扮演用户和助手的角色,进行多轮对话。
- 质量控制:使用专门的模型来评估这些对话的质量,过滤掉低质量的对话。
3. 偏好数据生成
偏好数据是用来帮助模型学会选择更好回答的例子。生成偏好数据的过程包括:
- 生成多个回答:针对每个提示,模型会生成多个不同的回答。
- 评判回答:通过已有的真实答案或验证器(如数学和编程任务)来评估回答的正确性。
- 选择优劣回答:使用大模型或奖励模型来比较回答的好坏,并选择最佳和最差的回答进行训练。
4. 迭代改进
通过反复生成数据和优化模型,不断提高模型的质量:
- 初始对齐模型:使用初始模型生成数据,进行训练。
- 数据增强:生成的新数据用于训练更好的模型,再用这些更好的模型生成更高质量的数据。
- 持续改进:通过多轮数据生成和优化,模型的能力不断提升。
5. 补充数据源
为了让模型在特定任务中表现更好,还会加入一些特殊的数据集:
- 主题跟随:生成一些对话数据,帮助模型在任务对话中保持主题一致。
- 不可完成任务:让模型学会拒绝无法完成的任务,避免胡乱回答。
- 科学和数学数据:加入科学和数学题目,增强模型在这些领域的能力。
- 文档理解:使用一些问答数据,提升模型理解和回答文档问题的能力。
- 函数调用:增强模型调用函数和处理编程任务的能力。
通过这些步骤,Nemotron-4 340B 模型能够生成大量高质量的数据,用于训练和优化更强大的模型。这不仅提高了模型的性能,还使其在各种应用场景中表现更好。
性能表现
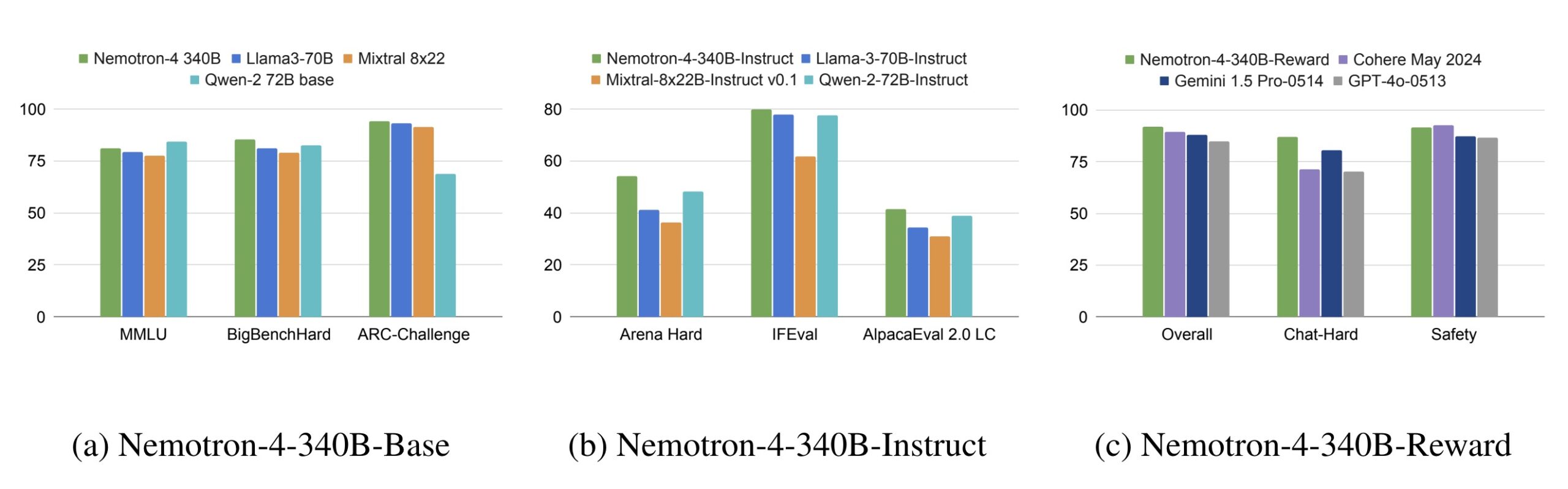
 与开源模型对比:
与开源模型对比:
- Nemotron-4-340B-Base 在常识推理任务(如 ARC-Challenge、MMLU、BigBench Hard)中超越了 Llama-3 70B、Mistral 8x22B 和 Qwen-2 72B 等模型。
- Nemotron-4-340B-Instruct 在指令遵循和对话能力方面超过了 Llama-3 70B-Instruct、Mixtral-8x22B-Instruct-v0.1 和 Qwen-2-72B-Instruct 等模型。
- Nemotron-4-340B-Reward 在 RewardBench 中表现最佳,超过了 Cohere May 2024、Gemini 1.5 Pro-0514 和 GPT-4o-0513 等模型。
与专有模型对比:
- Nemotron-4-340B-Instruct 在多轮对话(MT-Bench)和指令遵循任务(IFEval)中表现接近 GPT-4-1106-preview 和 Mistral Large。
- Nemotron-4-340B-Reward 在 RewardBench 的主要数据集中表现优于 GPT-4-0125-preview 和 Claude-3-Opus-02292024 等模型。
 人类评估
人类评估
在一组训练有素的标注人员对 136 个提示的评估中,Nemotron-4-340B-Instruct 与 GPT-4-1106-preview 进行对比,结果显示:
- 总体胜率:Nemotron-4-340B-Instruct 的总体胜率为 28.19%,平局率为 46.57%,败率为 25.24%。
- 各类别胜率:在多轮对话、开放问答、分类、封闭问答等任务类别中表现出色。
详细介绍:https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
论文:https://research.nvidia.com/publication/2024-06_nemotron-4-340b
模型下载:
https://huggingface.co/nvidia/Nemotron-4-340B-Instruct
https://huggingface.co/nvidia/Nemotron-4-340B-Reward















{kind=link}