
V-Express 是由南京大学和腾讯AI实验室共同开发的一项可以把单张照片变成视频的技术,并且它能够根据不同的信号,如声音、姿势、图像参考等来控制视频内容。它确保了弱信号也能有效地影响最终生成的视频,让视频生成更加逼真和多样化。
V-Express 功能特点
- 平衡控制信号:
- V-Express 能够同时处理多种控制信号,比如声音、图像参考、姿势等,确保弱信号(如音频)不被强信号(如姿势和图像)掩盖。
- 生成肖像视频:
- 它可以根据一张人物照片,结合音频等控制信号,生成一段人像视频。比如你有一张你的照片和一段你说话的音频,V-Express 可以生成一段你说话的视频。
- 渐进式训练:
- 通过逐步增强弱信号的影响力,V-Express 能够让这些弱信号在生成视频时起到更大的作用。
这里的“信号”指的是能够影响视频生成的各种数据类型,比如声音、姿势、图像参考等。具体来说:
- 声音信号:
- 理解:当你提供一段声音(例如你说话的音频),V-Express 能够分析这个声音信号,并将其转换成视频中的嘴部动作和表情,使生成的视频与你的声音同步。
- 应用:比如你有一张自己的照片和一段你说话的音频,V-Express 能够生成一个视频,视频中的你在说话,嘴型和表情与音频完全匹配。
- 姿势信号:
- 理解:如果你提供的是一段描述姿势的信号(例如骨架动画或姿势数据),V-Express 能够根据这些姿势信号生成相应的身体动作和头部姿态,使视频中的人物按照这些姿势动作。
- 应用:比如在虚拟会议中,系统可以根据你的动作生成一个虚拟形象,跟随你的实际动作进行演示。
- 图像参考信号:
- 理解:当你提供参考图像(例如目标人物的照片),V-Express 能够根据这个参考图像生成相应的肖像视频,确保生成的人物在视频中与参考图像相似。
- 应用:比如在电影制作中,使用演员的照片生成虚拟角色的视频,使其外观与真实演员一致。
举例解释
例如你正在使用一个视频制作应用,你有以下素材:
- 一张你的照片
- 一段你说话的录音
- 一段描述你手势的骨架数据
你希望生成一个视频,视频中的你正在说话,同时做出某些手势动作。V-Express 可以根据这些不同的信号,生成一个视频:
- 声音信号:你的声音录音会被用来控制视频中的嘴部动作和面部表情,使得视频中的人物看起来像在说你录音中的话。
- 姿势信号:骨架数据会被用来控制视频中的身体和手部动作,使得视频中的人物做出与你描述的手势相同的动作。
- 图像参考信号:你的照片会被用来生成视频中的人物外观,使得视频中的人物看起来像你。
最终,V-Express 生成的视频会综合这些信号,创建一个看起来非常逼真且符合你期望的视频内容。
一些组合场景
场景1:使用 A 的图片和 A 的说话视频
例子解释: 这个场景是当你有一个人的照片(比如你的朋友A)和这个人说话的视频时,可以用V-Express生成一个新的视频,这个视频中的A会在另一个场景下说话。生成的视频会确保A的嘴型和表情与原始视频中的说话内容一致。

场景2:使用 A 的图片和任意说话音频
例子解释: 这个场景是当你有一个人的照片(比如你的朋友A)和任意一段说话的音频时,可以用V-Express生成一个新的视频,这个视频中的A会根据音频内容进行口型同步。比如,你有A的照片和一段讲故事的音频,生成的视频会显示A在讲这个故事。

场景3:使用 A 的图片和 B 的说话视频
例子解释: 这个场景是当你有一个人的照片(比如你的朋友A)和另一个人说话的视频(比如B的说话视频)时,可以用V-Express生成一个新的视频,这个视频中的A会表现出B的说话内容和一些面部动作。生成的视频会使A看起来像在说B的内容,同时有B的视频中的表情和姿势。

V-Express 与其他同类型方法的不同之处
V-Express 在肖像视频生成领域有几个显著的特点,使其与其他方法有所不同:
- 渐进式控制信号平衡:
- 其他方法:许多现有方法直接利用控制信号生成视频,较弱的控制信号(如音频)往往会被较强的信号(如姿势和图像)掩盖,导致视频生成时弱信号的影响力较弱。
- V-Express:通过一系列渐进丢弃操作,逐步增强弱信号的影响力,确保弱信号能够有效控制视频内容。这种渐进式的方法使得不同强度的信号能够更好地平衡和融合。
- 多种信号的融合:
- 其他方法:通常只能处理少量类型的控制信号,且在处理多个信号时效果不佳。
- V-Express:能够同时处理多种类型的控制信号(如文本、音频、图像参考、姿势、深度图等),并且通过渐进式训练方法确保每种信号都能有效地发挥作用。
- 专注于音频控制:
- 其他方法:大多侧重于图像和姿势等较强信号的控制,音频控制效果较差。
- V-Express:特别关注音频信号的控制,通过渐进丢弃的方法增强音频信号的影响力,使得音频信号在视频生成中能够起到重要作用,生成的肖像视频能够更好地与音频同步。
- 实验验证效果显著:
- 其他方法:在实验中通常存在弱信号控制效果不佳、视频生成质量不稳定的问题。
- V-Express:实验结果表明,其在处理弱信号(尤其是音频)方面表现优异,生成的肖像视频质量高且能够准确反映不同控制信号的要求。
技术方法
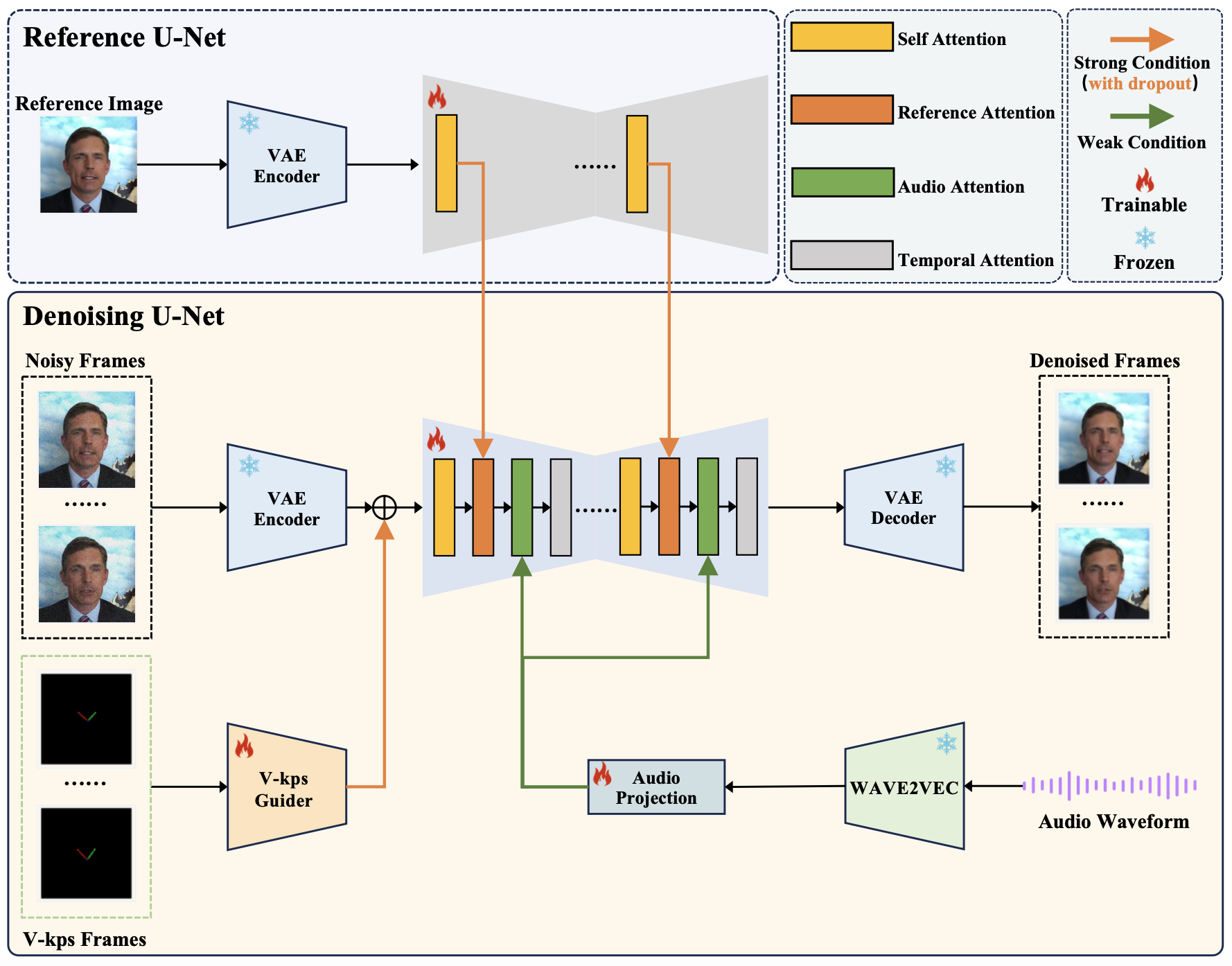 V-Express 是一种用于肖像视频生成的技术方法,主要通过渐进式训练和平衡不同强度的控制信号来实现。以下是V-Express的技术方法详细介绍:
V-Express 是一种用于肖像视频生成的技术方法,主要通过渐进式训练和平衡不同强度的控制信号来实现。以下是V-Express的技术方法详细介绍:
1. 条件丢弃(Conditional Dropout)
条件丢弃是一种技术,通过在训练过程中有选择地忽略一些控制信号来增强其他信号的影响力。具体步骤如下:
- 在每个训练阶段,随机忽略部分强信号(如姿势或图像),从而使模型更加关注弱信号(如音频)。
- 通过渐进式增加弱信号的权重,使其在视频生成中的影响力逐步增强。
2. 渐进式训练(Progressive Training)
渐进式训练是一种逐步引入复杂性的训练方法,使模型能够更好地适应多种信号的融合。具体过程如下:
- 初始阶段:仅使用最基本的控制信号(如图像)进行训练,确保模型能够生成基础的视频内容。
- 中间阶段:逐步引入其他控制信号(如姿势、文本),并逐步提高这些信号的权重。
- 最终阶段:引入最弱的信号(如音频),并通过条件丢弃的方法增强其影响力,确保模型能够有效利用所有信号生成高质量的视频。
3. 多信号融合(Multi-Signal Fusion)
多信号融合是将不同类型的控制信号(如文本、音频、图像参考、姿势、深度图等)综合起来,生成符合所有信号要求的视频。具体方法包括:
- 特征提取:对每种信号进行特征提取,将其转换为模型可以处理的向量形式。
- 特征融合:将所有信号的特征向量进行融合,形成一个综合特征向量。
- 生成网络:利用综合特征向量,通过生成网络生成最终的视频内容。
4. 实验验证(Experimental Validation)
实验验证是通过实际数据验证V-Express方法的有效性。具体步骤包括:
- 数据准备:准备包含多种控制信号的数据集,如包含音频、姿势、图像的肖像视频数据集。
- 训练与测试:使用准备好的数据集对模型进行训练,并在测试集上进行验证。
- 效果评估:通过定量指标(如生成视频的质量、信号控制的准确性)和定性评估(如专家评审)验证方法的有效性。
1. 数据准备
– 收集并预处理包含多种信号的肖像视频数据2. 特征提取
– 对每种信号进行特征提取,转换为向量形式3. 渐进式训练
– 初始阶段:使用基础信号训练模型
– 中间阶段:逐步引入其他信号,调整信号权重
– 最终阶段:引入弱信号,进行条件丢弃训练4. 多信号融合
– 将所有信号的特征向量进行融合,生成综合特征向量
– 利用生成网络生成视频5. 实验验证
– 在测试集上进行验证,评估生成视频的质量和信号控制的准确性
结果展示
- Naive Retargeting:
- 解释:这种方法是最简单的重定位方法,直接将参考图像应用于视频生成中,没有进行复杂的调整或优化。效果通常比较直接,但可能不够自然和精细。
- 应用:适用于需要快速生成初步视频效果的场景。
- Offset Retargeting:
- 解释:通过引入偏移重定位策略,这种方法能够在生成的视频中改善面部特征的匹配度,使得面部动作和表情更加自然和连贯。
- 应用:适用于需要较高面部特征匹配度的视频生成场景,比如动画制作和虚拟形象生成。
- Fix Face:
- 解释:采用固定面部策略,确保生成的视频中面部特征保持稳定,不会随控制信号(如音频)而变化。这对于弱信号(如音频)影响较大的情况非常有用,能够保持面部一致性。
- 应用:适用于生成需要稳定面部特征的视频,如虚拟主播和远程会议系统。
- Cases from EMO:
- 解释:展示了一些从 EMO 数据集生成的视频案例,证明 V-Express 方法在实际应用中的效果。EMO 数据集包含丰富的面部表情和动作数据,有助于测试和验证视频生成技术的效果。
- 应用:用于展示技术在实际数据集上的表现,增强用户对方法有效性的信心。
- Cases from VASA-1:
- 解释:展示了一些从 VASA-1 数据集生成的视频案例,进一步验证了 V-Express 方法的有效性。VASA-1 数据集通常包含多种姿势和动作的数据,有助于全面测试技术的适用性。
- 应用:用于展示技术在不同数据集和场景下的应用效果,确保方法的通用性和鲁棒性。













{kind=link}