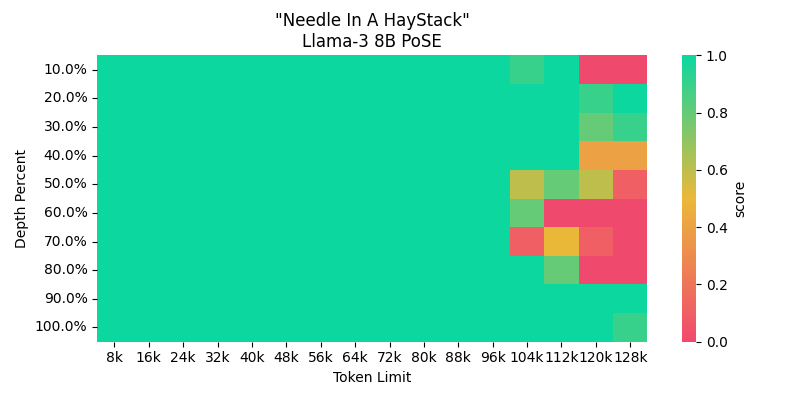
<p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">Llama 3-8B 64K 模型使用了位置指定扩展 (PoSE) 技术来扩展上下文长度。这一技术的应用允许模型处理更长的文本序列,从而提高了模型在理解和生成长文本时的效能和准确性。</p> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">具体来说,通过以下几个步骤实现上下文长度的扩展:</p> <ol data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">持续的预训练:</strong> 在已有的基础上,该模型在 RedPajama V1 数据集上继续进行预训练,这个数据集的特点是包含了长度在 6K 到 8K tokens 之间的文本数据。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">调整 PoSE 参数(rope_theta):</strong> 在预训练后,开发团队进一步将 rope_theta 参数设置为2M,目的是在保持模型性能的同时,进一步扩展上下文长度能力,超过原有的 64K tokens 限制。</li> </ol> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE(Positional Scaling for Transformers)是一种用于优化和增强Transformer模型的技术。这项技术主要针对处理更长的文本序列,特别是在自然语言处理(NLP)和其他需要长上下文理解的任务中。下面简要介绍一下PoSE的核心概念和它如何工作。</p> <h3 data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE的基本原理</h3> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">上下文扩展</strong>:PoSE的主要目标是扩大Transformer模型的上下文窗口,使模型能够在生成或理解文本时考虑更长的序列。这对于提高模型在处理长文章、对话或其他复杂文本时的准确性和连贯性非常重要。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">位置编码调整</strong>:在标准的Transformer模型中,位置编码(Positional Encoding)是一个关键组件,它为模型提供输入序列中各单元的位置信息。PoSE通过调整这些位置编码的规模来扩展模型处理的序列长度,而不是简单地线性扩展,这有助于模型更有效地利用位置信息,改善长序列的处理能力。</li> </ul> <h3><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE 方法:</strong></h3> PoSE 方法是为了有效地扩展大型语言模型(LLMs)的上下文窗口而设计的。该技术通过在固定的上下文窗口内操纵位置索引来模拟更长的输入,从而在不需要整个目标长度的上下文进行微调的情况下,实现上下文长度的扩展。 <ol data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong>核心机制</strong></p> <ol data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">分割语境窗口</strong>:</p> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE首先将原始的固定语境窗口分割成多个块(chunks)。这些块被分别赋予不同的“跳跃偏置”(skipping biases),这些偏置用于调整每个块的位置索引。</li> </ul> </li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">跳跃偏置的应用</strong>:</p> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">对于每一个训练样本,块的长度和跳跃偏置是变化的,允许模型适应目标长度内的所有位置。跳跃偏置通过增加特定的偏移量来“跳过”某些位置,模拟更长输入的效果。</li> </ul> </li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">保持连续性</strong>:</p> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">在每个块内部,保持连续的位置索引。这种设计模仿了预训练阶段的结构,有助于保持模型在语言建模和理解方面的能力。</li> </ul> </li> </ol> <h4 data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">训练策略</h4> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE在每次训练迭代中通过改变每个块的跳跃偏置和长度,调整每个训练样本的位置索引,从而使模型能够适应从原始语境窗口到目标语境窗口的扩展。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">这种方法使得在不直接扩展模型的语境窗口大小的情况下,模拟并适应更长的输入,从而解耦了训练长度和目标长度。</li> </ul> <h4 data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">实验验证</h4> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE方法在实验中表现出来显著的内存和时间效率。通过与全长度微调的比较,PoSE在多种任务和数据集上展示了相似或更佳的性能,同时显著降低了资源消耗。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE兼容所有基于RoPE的LLMs,并支持多种位置插值策略,验证了其广泛的应用潜力。</li> </ul> </li> </ol> <h3 data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE的应用</h3> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">扩展上下文长度</strong>:使用PoSE技术,开发人员可以有效地扩大模型的上下文理解能力,例如,从原先的8k令牌上下文长度扩展到64k。这使得模型能够在生成文本或回答问题时,考虑更广泛的上下文信息,从而提供更加相关和准确的输出。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">增强长距离依赖处理能力</strong>:在处理自然语言时,长距离依赖是一个常见问题,即文本中相隔很远的词之间的关系。通过优化位置编码,PoSE帮助模型更好地捕捉这种跨越长篇幅的词语关系。</li> </ul> <h3 data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE的优势</h3> <ul data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">提高处理效率</strong>:相比于简单地增加模型的大小,PoSE通过更智能的位置编码调整提供了一种资源效率更高的方法来处理更长的序列。</li> <li data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8"><strong data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">改善模型的灵活性和扩展性</strong>:使用PoSE,模型在不显著增加计算负担的情况下,能够适应不同长度的输入,使其更加灵活和适用于多种应用场景。</li> </ul> 模型下载:<a href="https://huggingface.co/winglian/Llama-3-8b-64k-PoSE" target="_blank" rel="noopener">https://huggingface.co/winglian/Llama-3-8b-64k-PoSE</a> <p data-immersive-translate-walked="7724c4c7-4542-4455-b5eb-53445b9d87f8">PoSE:<a href="https://github.com/OpenAccess-AI-Collective/axolotl/pull/1567" target="_blank" rel="noopener">https://github.com/OpenAccess-AI-Collective/axolotl/pull/1567</a></p>






{kind=link}