
Twitter-Insight-LLM 是一个开源项目,主要功能包括从Twitter抓取数据、基于嵌入的图像搜索,以及其他一些数据分析和处理功能。
同时利用LLM还能对Twitter数据进行深入分析,支持多种功能,包括数据可视化和图像标注。
主要功能
-
Twitter 数据抓取:
- 功能:使用Selenium自动化工具从Twitter用户的账户中抓取他们点赞的推文,并将数据保存为JSON和Excel文件。
- 实现方式:通过模拟浏览器操作,登录用户的Twitter账户,自动导航到用户的点赞页面,并抓取相关数据。
- 输出:抓取到的数据会被保存为JSON格式和Excel文件,便于后续的数据分析和记录。
-
基于嵌入的图像搜索:
- 功能:允许用户使用自然语言描述来搜索图库中未经标注的图像。功能支持多语言,但在英语中的效果更佳。
- 实现方式:利用图像嵌入技术,将图像和文本描述转换为高维空间中的点,通过计算点之间的距离来找到最匹配的图像。
- 应用:这项功能支持多语言查询,特别适用于需要快速找到特定图像的场合,如媒体行业和内容创作者使用。
例如,以下是搜索 “黑猫”(中文)的结果,但您也可以搜索 “照片中的一群人”、”工作流程图 “或 “悲伤 “等更抽象的概念。
-
数据分析和可视化:
- 功能:对抓取的Twitter数据进行初步的分析和可视化。
- 实现方式:使用Python的数据分析库(如Pandas和Matplotlib)来处理数据和生成图表,例如按时间和媒体类型分析点赞趋势,或生成喜欢的推文的日历热图。
- 应用:帮助用户洞察自己的Twitter活动模式,或用于市场分析和社交媒体策略制定。
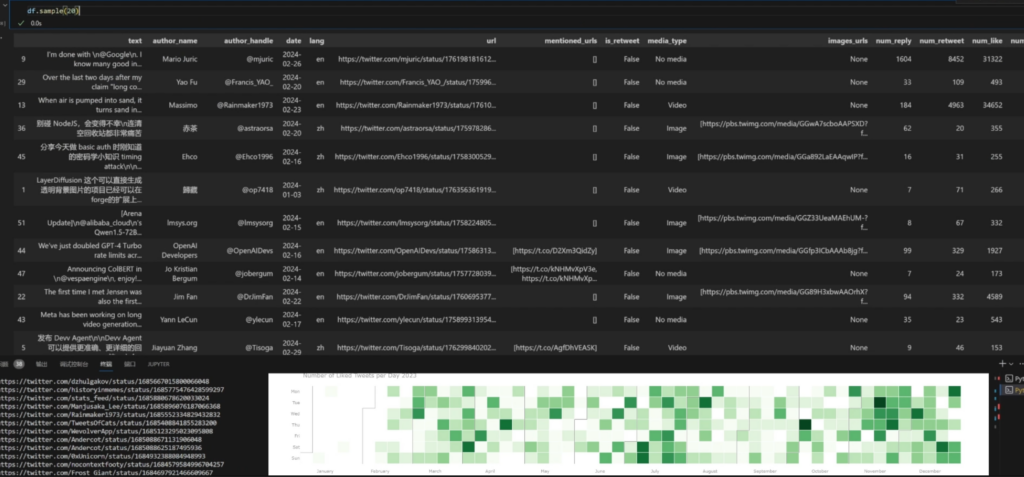
-
图像标注:
- 功能:为保存的Twitter图片自动生成描述性文字。
- 实现方式:使用OpenAI的API,结合大型语言模型来生成关于图片内容的描述,这些描述会根据图片的视觉内容自动产生。
- 应用:适用于需要快速生成大量图像标注的场景,如内容管理系统或自动化社交媒体管理。
1. 数据抓取
- 使用Selenium:项目首先使用Selenium,这是一个自动化测试工具,用于模拟用户在浏览器中的行为。通过Selenium自动登录Twitter账户,导航至特定的Twitter页面(如用户的“喜欢”列表),并抓取数据。
- 保存数据:抓取的数据包括推文内容、媒体(如图片和视频)链接等,这些数据随后被保存为JSON格式和Excel文件,方便后续的处理和分析。
2. 基于嵌入的图像搜索
- 图像和文本嵌入:项目使用预训练的深度学习模型来生成图像和文本的嵌入向量。这些嵌入向量是高维空间中的数值表示,能够捕捉图像的视觉内容和文本描述的语义内容。
- 搜索和匹配:当用户输入一个自然语言描述时,系统将这个描述转换为嵌入向量,并与数据库中的图像向量进行比较,找出最相似的图像。
3. 数据分析和可视化
- 分析脚本:项目包含Python脚本和Jupyter Notebook,用于加载抓取的数据,并进行初步的数据分析,如统计分析、趋势分析等。
- 可视化:使用图表库(如Matplotlib)在Notebook中生成可视化图表,帮助用户直观理解数据特征和趋势。
4. 图像标注
- 使用OpenAI API:对于Twitter数据中的图像,项目可以利用OpenAI提供的语言模型API生成图像的描述性标注。这一步骤通过分析图像内容,并生成相应的文本描述,增加了图像的信息价值。
技术和工具
- Python:项目的主要编程语言,用于写脚本和处理数据。
- Jupyter Notebook:用于交互式数据分析和展示结果。
- Selenium:用于网页数据的自动化抓取。
- OpenAI API:用于生成图像描述和其他语言模型相关的功能。













{kind=link}