

Chinese Tiny LLM:从头开始训练 专注于中文的大语言模型
CT-LLM是针对中文设计的首个大语言模型,拥有20亿参数,并在12000亿中文语料库上进行预训练。
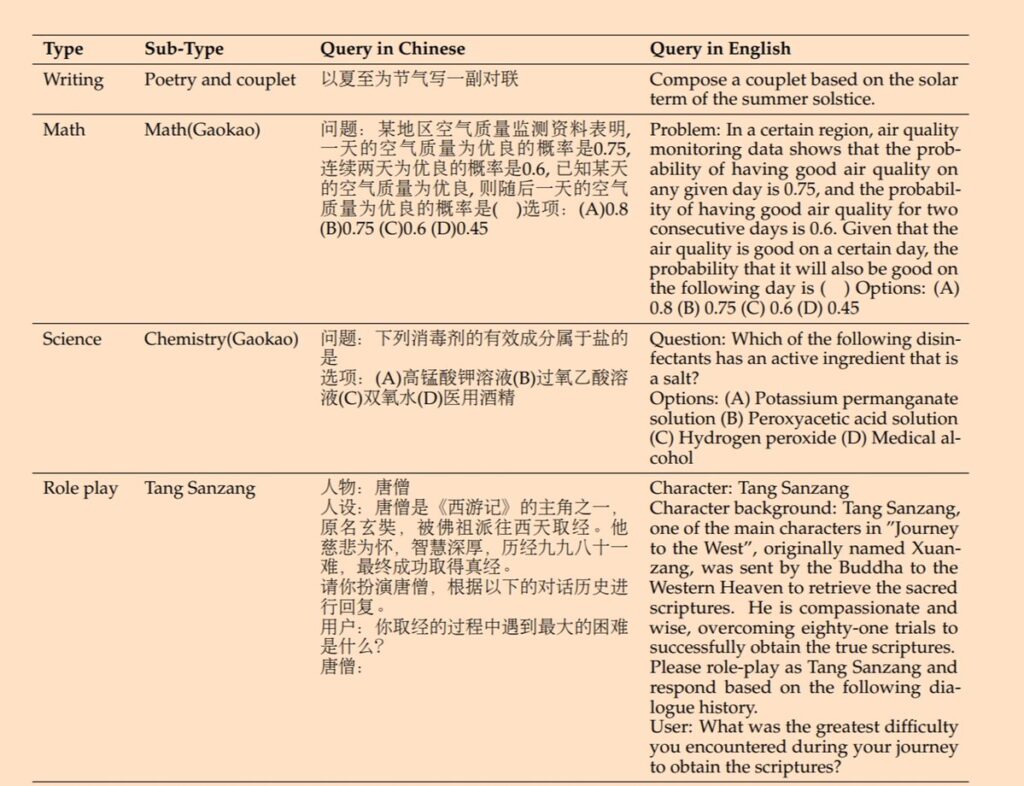
他们还弄了了新的中文对齐基准测试:CHC-Bench,测试LLMs对中文文化、历史、传统、人文、地理和STEM的深入理解。
测试结果与一些同参数模型性能相当。
他们开放了整个数据过滤过程、训练动态、训练和评估数据,以及模型的中间检查点等所有相关信息。这样的做法使得其他研究者、开发者能够访问这些资源,利用这些资料进行自己的研究或进一步改进模型。
主要功能特点
- 中文处理能力强大:CT-LLM专注于提高对中文语言的理解和生成能力,利用大规模的中文数据预训练,实现对中文文本的高效处理。
- 跨语言适应性:虽然重点优化了中文处理,CT-LLM也展示了对英文和编程代码的良好处理能力,体现了模型的多语言适应性。
- 高性能的中文任务表现:在中文语言任务的基准测试CHC-Bench上,CT-LLM展现了出色的性能,证明了其在理解和应用中文方面的高效能力。
- 从零开始的预训练:不同于以英文为主的预训练方法,CT-LLM从头开始,主要使用中文数据进行预训练,这让模型在理解中文方面有了质的飞跃。
- 细致的数据处理:通过精细的数据处理过程,创建了专门的中文预训练语料库MAP-CC,确保了数据的高质量和适用性。
- 开放资源:研究团队开源了模型训练的完整过程和所用的数据处理细节,包括MAP-CC语料库和CHC-Bench基准测试,促进了学术界和工业界的进一步研究和应用。


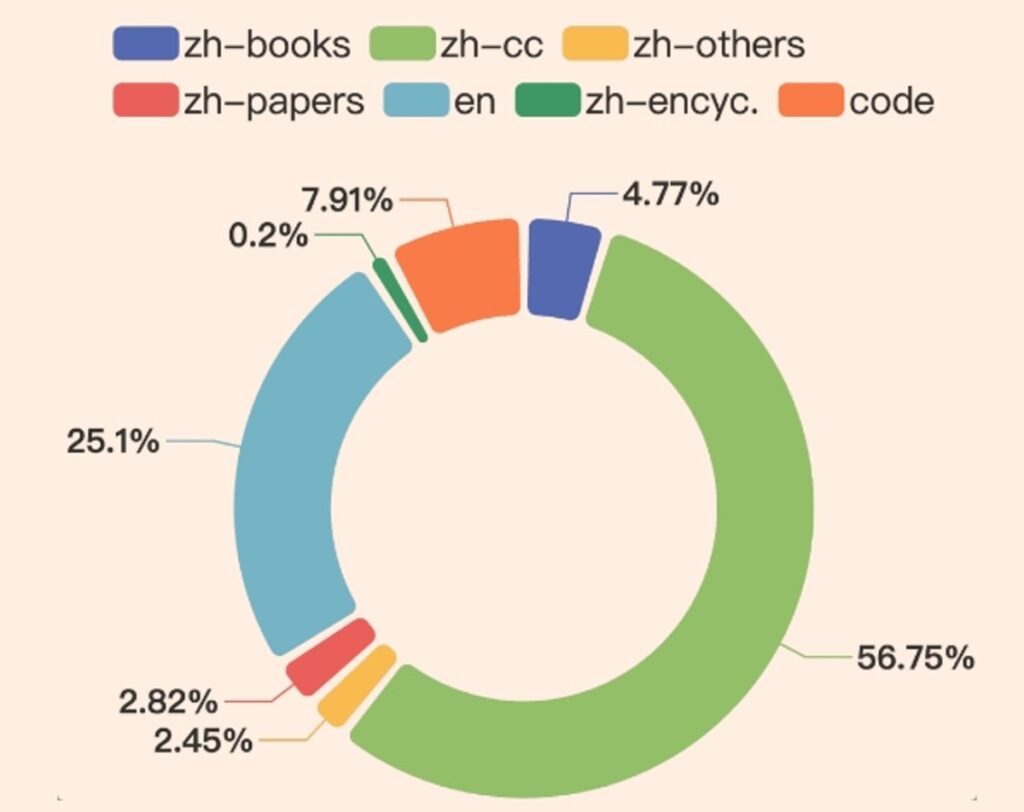
CT-LLM从零开始,与传统方法不同,主要集成了12000亿中文文本数据,利用了包含8000亿中文令牌、3000亿英文令牌和1000亿代码令牌的广泛语料库。这种策略构成使模型在理解和处理中文方面表现出色,并通过对齐技术进一步增强了这一能力。CT-LLM在CHC-Bench上表现出色,在中文语言任务上表现出色,并通过SFT在英语中展现了其熟练程度。

数据去重策略
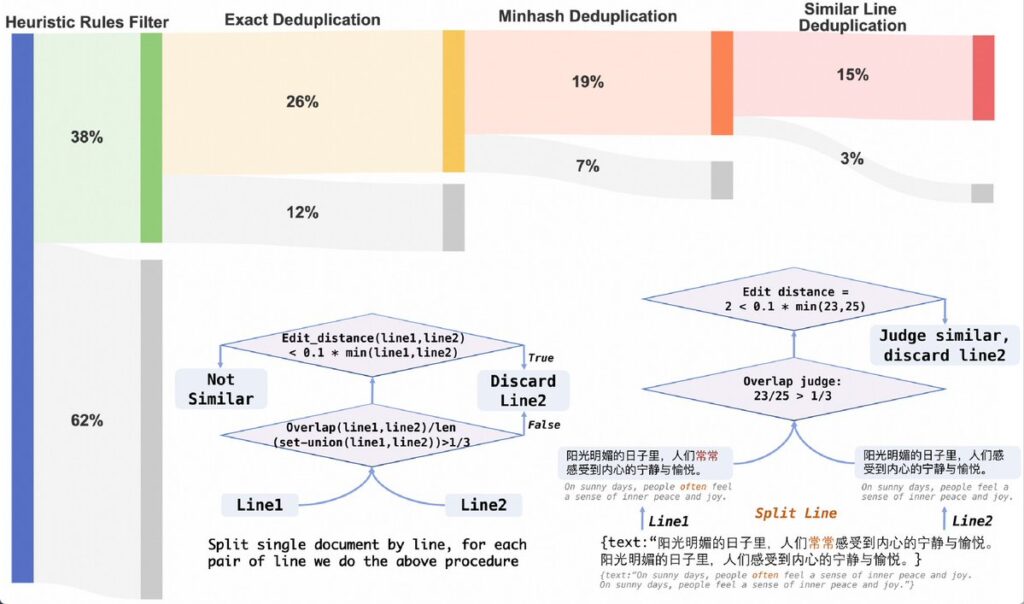
- 编辑距离去重:为了减少数据中的重复内容,研究团队使用编辑距离来判断两行文本是否相似。如果两行文本之间的编辑距离小于较短行长度的十分之一,则认为这两行是相似的。此外,通过计算两行文本字符重叠的比例,如果重叠比例小于三分之一,则认为这两行不相似。这些方法帮助去除或减少数据集中的重复内容。

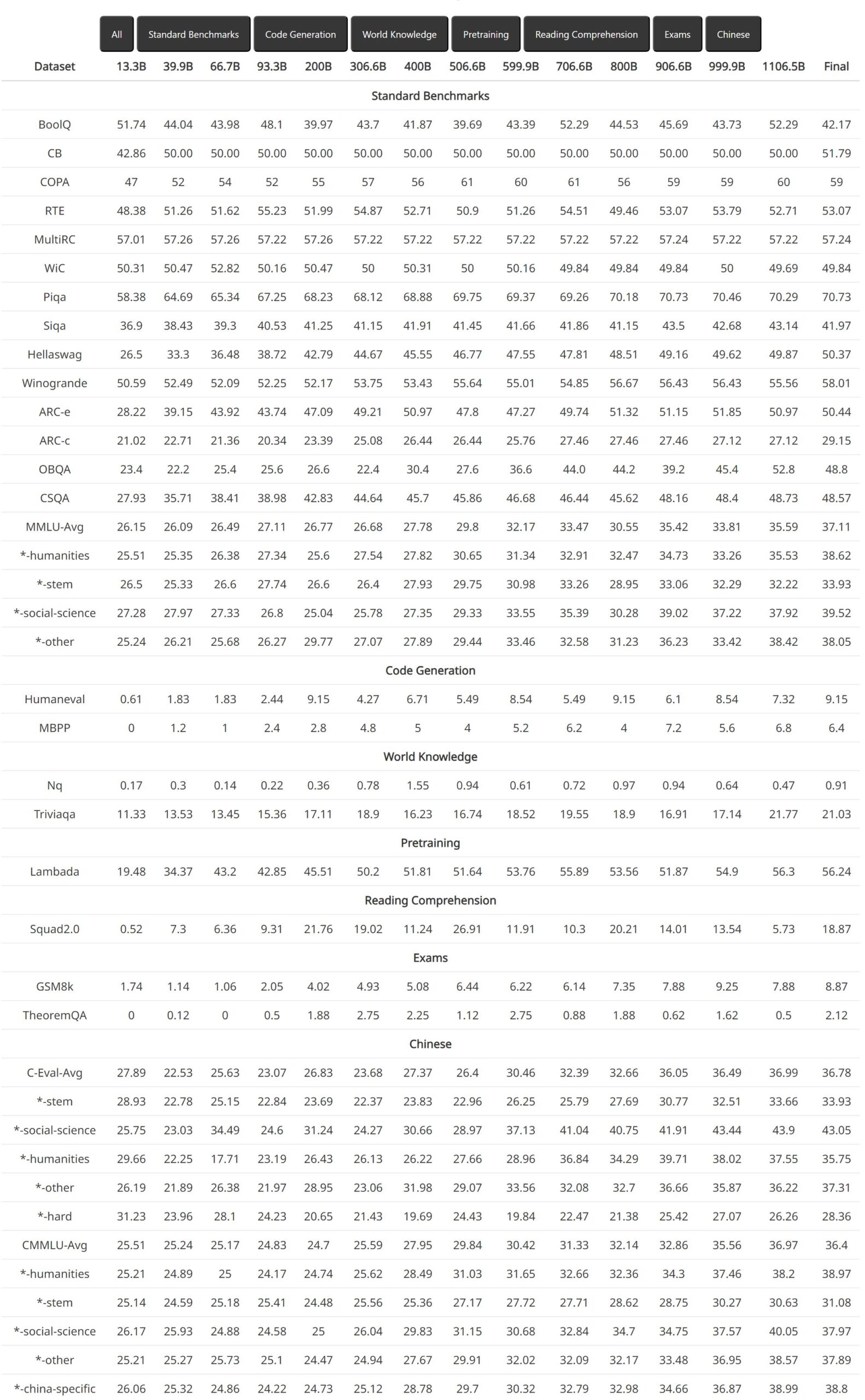
中间检查点的详细评估动态

以 2B 左右模型的综合基准评估对齐模式

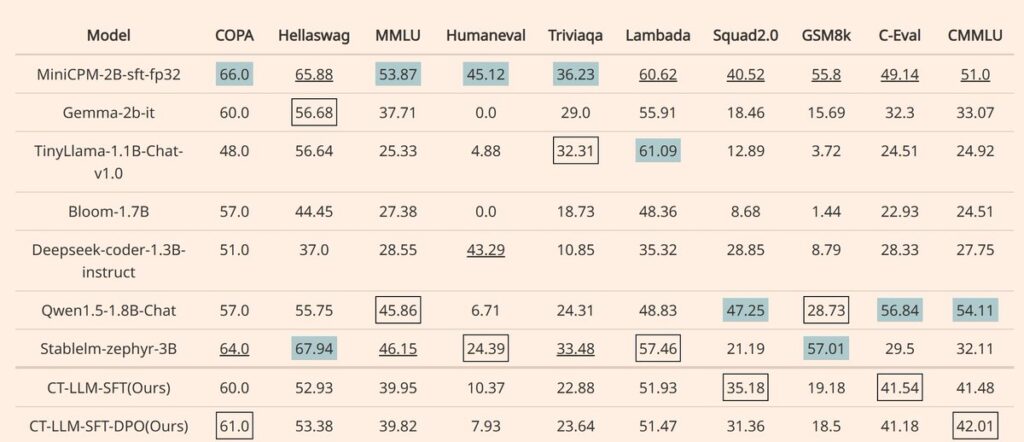
使用 GPT4 评分器对 CHC-BENCH 的中文能力进行基准测试

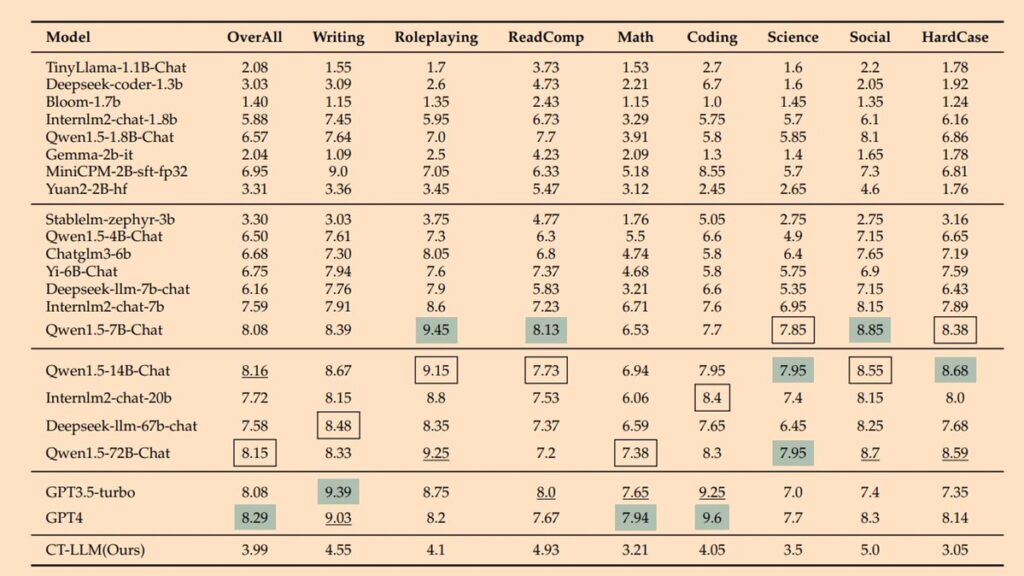
CHC-Bench基准测试: 一个类似于 MTbench 的基准,用于评估模型对中国文化、历史、传统、人文、地理和科学、技术和工程八大类的理解。


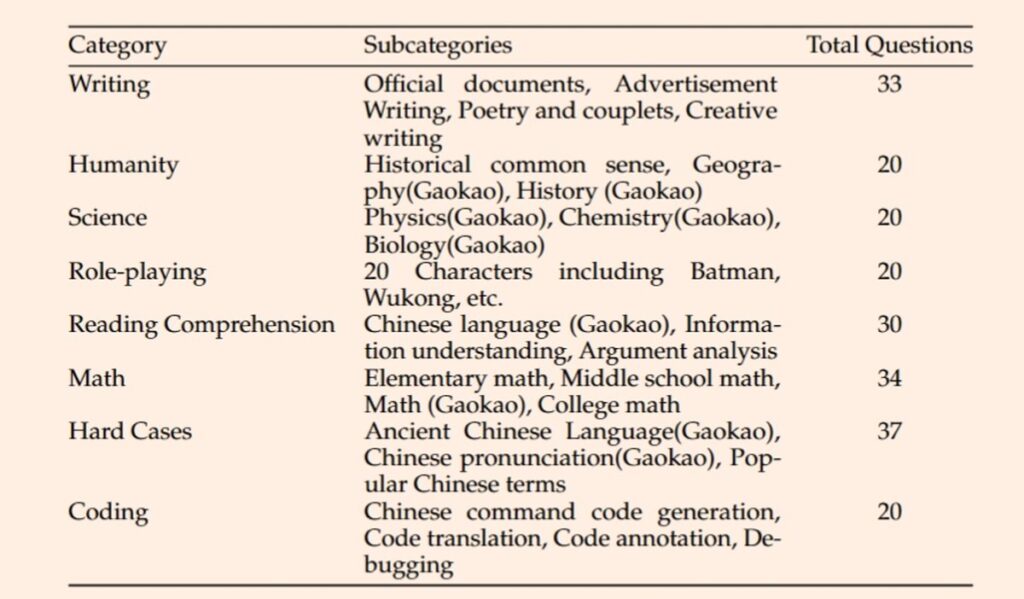
800B 中文预训练语料库(MAP-CC): huggingface.co/datasets/m-a-p
中级 CKPT: huggingface.co/m-a-p/CT-LLM-i
SFT 型号: huggingface.co/m-a-p/CT-LLM-S
DPO 型号: huggingface.co/m-a-p/CT-LLM-S