

LivePortrait是一个用于生成逼真肖像动画的框架,只需一张静态肖像图像就能生成动态视频。其主要目标是实现高效且精确控制的肖像动画,使得生成的动画在视觉效果和细节控制上都达到较高水平。
它能够从单一图像生成生动的动画视频,并能精确控制眼睛和嘴唇的动作,确保动画的自然流畅。
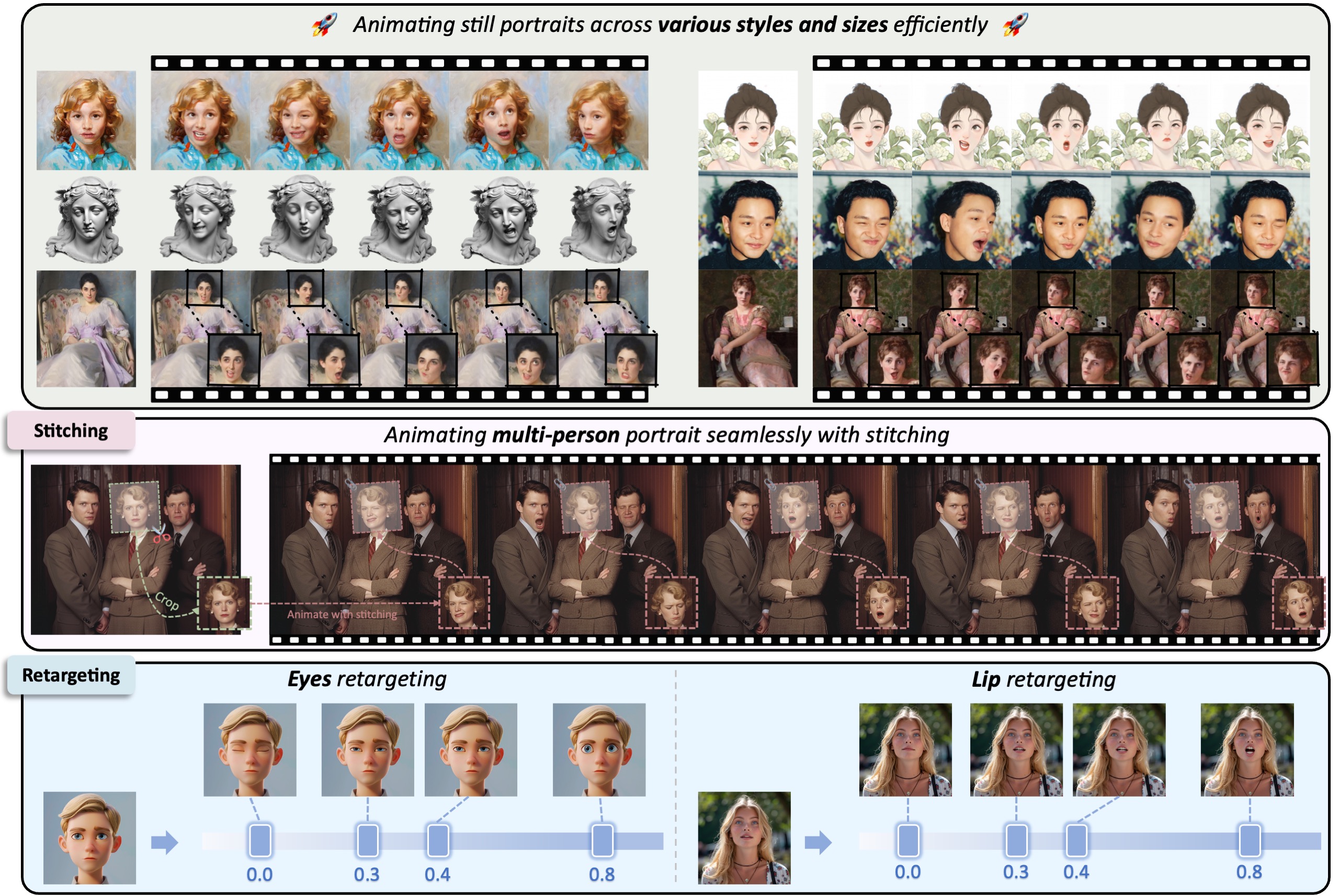
还可以处理多个人物肖像的无缝拼接,确保在多个动态人物之间过渡平滑,不会产生突兀的边界效果。
解决了什么问题:
- 生成质量和效率:
- 传统的扩散模型方法虽然生成质量高,但计算开销巨大,难以实现实时处理。LivePortrait通过隐式关键点方法,在保证高质量的同时,大幅提高了计算效率。
- 可控性不足:
- 现有的许多方法缺乏对细节的精细控制,如眼睛和嘴唇的独立动作控制。LivePortrait通过专门设计的重定向模块,解决了这一问题,使得动画在微表情和细节动作上更加逼真。
实际效果
- LivePortrait在生成的动画中,面部表情和头部运动自然逼真,与实际人物动作高度相似。
- 在眼睛和嘴唇的细节控制方面,LivePortrait表现出色,能够精确控制眼睛的注视方向和嘴唇的开合动作。
- 对比实验显示,LivePortrait生成的动画质量优于现有的非扩散模型和扩散模型方法。
- 在RTX 4090 GPU上,LivePortrait的生成速度达到了每帧12.8毫秒,显著高于现有的扩散模型方法。
- 通过优化网络架构和使用高效的隐式关键点方法,LivePortrait在保证生成质量的同时,大幅降低了计算开销。

- 从单一图像生成生动动画:
- 功能描述: LivePortrait能够从单一静态肖像图像生成生动、逼真的动画。通过利用源图像的外观特征和驱动视频的运动信息,该功能可以生成包含丰富面部表情和头部姿态变化的动态视频。
- 使用高质量数据集进行训练,包括69百万高质量的图像和视频帧,确保模型能够泛化到各种场景。
- 引入隐式关键点作为中间的运动表示,平衡了生成质量和计算效率。
- 举例: 如果有一张静态的人物照片,LivePortrait可以生成该人物微笑、眨眼或转头的动画。
- 精确控制眼睛的动作:
- 功能描述: LivePortrait内置了眼睛重定向模块,可以独立控制眼睛的动作。这个功能使得生成的动画中,眼睛可以根据需要自由移动,表现出不同的注视方向和眨眼动作。
- 举例: 在生成动画时,可以让人物的眼睛从左到右扫视,或者根据需要表现人物的眨眼动作,增强动画的真实感。
- 精确控制嘴唇的动作:
- 功能描述: LivePortrait的嘴唇重定向模块可以精确控制嘴唇的开合动作,使得人物在动画中的嘴唇动作与说话或表情变化同步,表现更加自然。
- 举例: 在生成人物说话的动画时,嘴唇可以根据输入的语音或文本内容精确同步,模拟出自然的说话动作。
- 缝合模块:
- 功能描述: 缝合模块用于处理多个肖像之间的无缝拼接。该功能确保在多个动态人物之间过渡平滑,不会产生突兀的边界效果。
- 举例: 当需要生成一段包含多个人物的动画时,缝合模块可以使各个人物之间的过渡自然流畅,避免出现不协调的边界。
- 多风格肖像的支持:
- 功能描述: LivePortrait通过混合图像和视频训练策略,支持多种风格的肖像动画生成。无论是写实风格还是动漫风格的肖像,都能生成高质量的动画。
- 举例: 不论是照片中的真实人物还是动漫风格的肖像,LivePortrait都可以生成对应风格的动态视频,使动画适用于多种应用场景。
- 高分辨率动画生成:
- 功能描述: 采用SPADE解码器和PixelShuffle上采样层,LivePortrait能够生成高分辨率的动画,提升图像的清晰度和细节表现。
- 举例: 生成的动画可以达到512×512的分辨率,使得人物的面部细节更加清晰,适用于需要高画质的应用场景。
LivePortrait主要技术方法
- 隐式关键点方法:
- 方法描述: 使用隐式关键点作为中间的运动表示,这些关键点能够有效地捕捉并表示面部的主要运动特征,平衡了生成质量和计算效率。
- 实现细节:
- 隐式关键点用于提取和表示面部的运动信息,并通过这些关键点的变换生成动画。
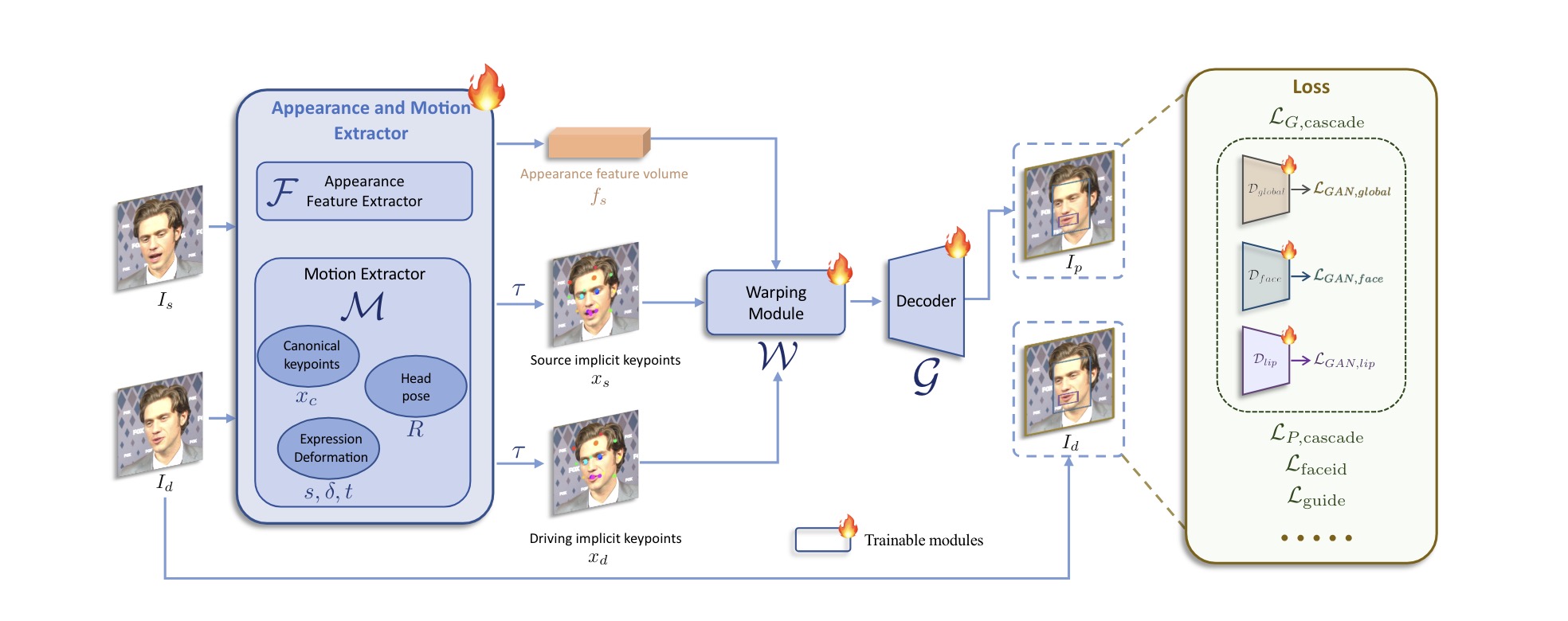
- 隐式关键点用于提取和表示面部的运动信息,并通过这些关键点的变换生成动画。
- 混合图像和视频训练策略:
- 方法描述: 结合高质量的静态肖像图像和动态视频进行训练,增强模型的泛化能力,使其能够处理各种风格的肖像。
- 实现细节:
- 将单帧图像视作一帧视频进行训练,使得模型不仅能够处理动态视频,还能生成风格多样的动画效果。
- 使用公开数据集和自有高质量视频数据进行训练,确保模型的多样性和鲁棒性。
- 升级的网络架构:
- 方法描述: 采用先进的网络架构,包括ConvNeXt-V2-Tiny作为主干网络和SPADE解码器,提升生成质量和计算效率。
- 实现细节:
- 将原始的隐式关键点检测器、头部姿态估计网络和表情变形估计网络统一到一个模型中,简化网络结构,提高性能。
- 使用SPADE解码器生成高质量动画,并结合PixelShuffle层进行分辨率上采样,生成的图像更加清晰。
- 标志导向的隐式关键点优化:
- 方法描述: 引入2D标志(如眼睛和嘴唇的关键点)作为指导,优化隐式关键点的学习过程,增强对细微面部表情的控制能力。
- 实现细节:
- 使用2D标志作为监督信号,优化隐式关键点的位置,使模型能够更好地捕捉微表情,如眨眼和眼球运动。
- 缝合和重定向模块:
- 方法描述: 提出缝合模块和两个重定向模块(眼睛和嘴唇重定向),增强动画的细节控制,使生成的动画更加自然流畅。
- 实现细节:
- 缝合模块:处理多个人物肖像的无缝拼接,确保过渡平滑。
- 眼睛重定向模块:独立控制眼睛的方向和动作,使得动画中的眼睛动作更加逼真。
- 嘴唇重定向模块:精确控制嘴唇的开合动作,使动画中的说话或表情变化更加自然。
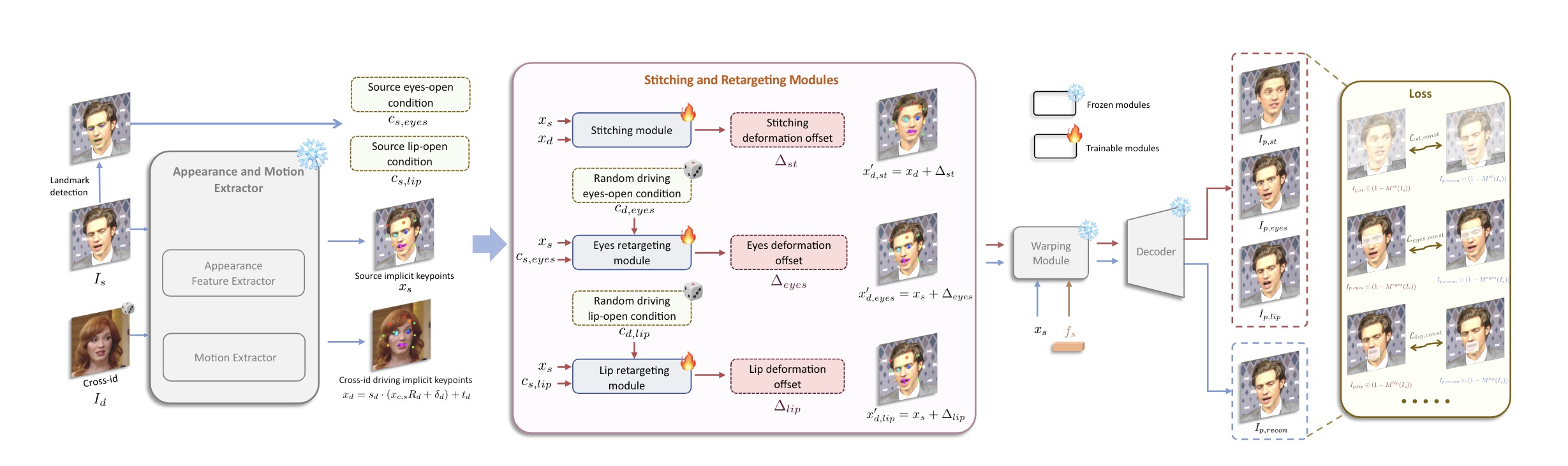
- 高效的生成速度:
- 方法描述: 优化计算过程,使得生成速度大幅提升,能够在高性能GPU上实现实时动画生成。
- 实现细节:
- 在RTX 4090 GPU上,LivePortrait的生成速度达到了每帧12.8毫秒,实现了高效的实时动画生成。


一些案例
使用单张静态图像通过拼接技术生成肖像动画,跨越各种风格(写实、油画、雕塑、3D 渲染)和不同尺寸
- 单图像动画: 将单一静态人物照片转变为视频,其中人物可以微笑、眨眼或转头。
- 家庭肖像动画: 动画处理包含多个家庭成员的肖像,每个成员的面部表情和动作均被无缝动画化,确保整体动画的自然流畅。
- 静态图像获取:从一张静态图像开始,这张图像提供了肖像的外观参考。
- 运动提取:从驱动视频、音频、文本或生成内容中提取运动信息(如面部表情和头部姿态)。
- 基于关键点的初步动画:利用隐式关键点方法,将提取的运动信息应用到静态图像上,生成初步的肖像动画。
- 拼接技术应用:通过拼接模块对初步生成的动画进行优化和增强,使得动画更加自然和连贯。拼接技术主要解决面部特征(如眼睛、嘴唇)的精细控制和衔接问题。
利用拼接技术对肖像视频进行编辑的过程
- 多段视频合成: 从多个短视频片段中提取素材,合成一个连贯的长视频,其中包含自然的面部表情和动作过渡。
- 表情调整: 在现有视频中调整人物的面部表情,如将一个严肃的表情改为微笑,或者调整说话时的嘴唇同步。
- 视频输入:首先输入一个或多个肖像视频。这些视频可以是从静态图像生成的动画,也可以是已有的视频片段。
- 运动和特征提取:从输入的视频中提取面部运动和特征信息,如面部表情、头部姿态等。
- 拼接技术应用:使用拼接模块对视频进行编辑和优化。拼接技术可以:
- 平滑不同视频片段之间的过渡,确保编辑后的视频自然连贯。
- 精确控制和调整面部特征,如眼睛、嘴唇的开合程度,使其符合预期的效果。
- 修复和增强视频中的细节,使最终输出的视频更加逼真和精细。
- 编辑和输出:根据用户的编辑需求,对视频进行进一步的处理和调整,然后输出最终编辑好的肖像视频。
眼睛和嘴唇重新定位

