
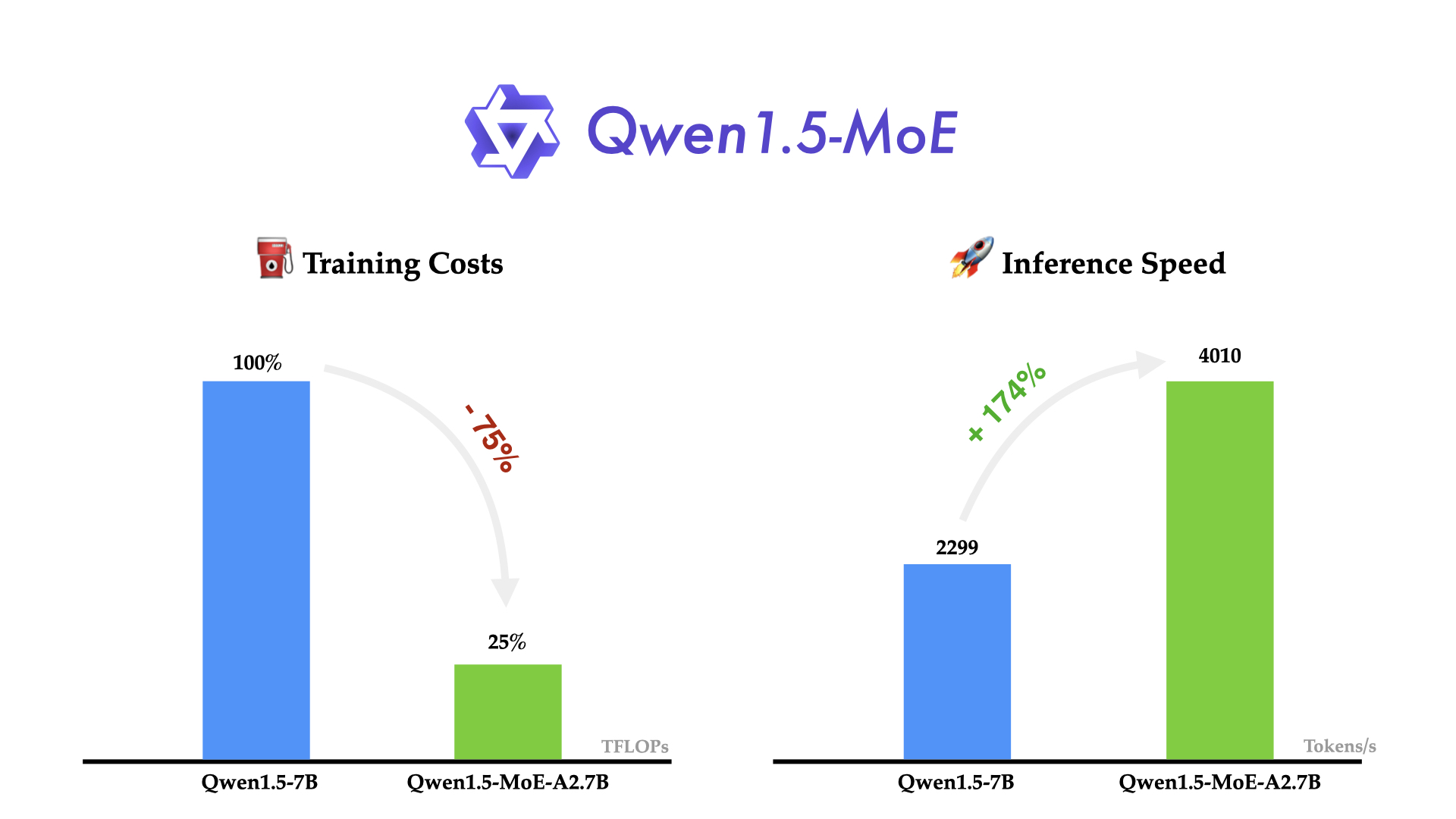
Qwen团队发布了他们的新型混合专家(MoE)模型——Qwen1.5-MoE-A2.7B,这是一款只有2.7亿激活参数的小型MoE模型,但其性能却能匹配到像Mistral 7B和Qwen1.5-7B这样的7B参数模型。与Qwen1.5-7B相比,Qwen1.5-MoE-A2.7B大大减少了训练成本,降低了75%,并将推理速度提高了1.74倍,有效提高了资源利用率,同时保持了出色的性能。
这一更新不仅是模型功能和性能的提升,也预示着Qwen模型从当前版本向更高级版本Qwen2的转变。Qwen1.5携带了若干重要的更新和优化,为未来Qwen2版本的发布铺垫了基础。















{kind=link}