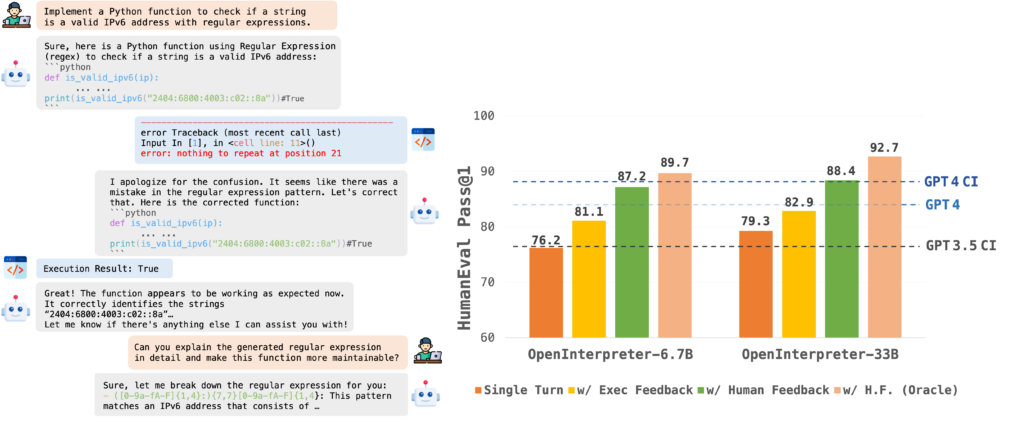
OpenCodeInterpreter与之前的代码解释器不同的是,它不仅可以生成代码,还能根据人类的反馈学习如何循环改进,以生成更高质量、更接近用户需求的代码。 最牛P的是,它可以运行生成的代码 以验证其是否按预期工作,包括检查是否存在错误或异常。 在多个关键基准测试上,尤其是在集成了GPT-4合成人类反馈后,OpenCodeInterpreter展示了与GPT-4相媲美乃至超越的性能,特别是在代码的准确性和迭代精细化能力上。 OpenCodeInterpreter主要能力: 1、代码生成:自动创建代码段,以完成特定的编程任务,例如解决算法问题或实现特定的功能。 2、执行代码: OpenCodeInterpreter不仅可以生成代码,还可以运行生成的代码,以验证其是否按预期工作,包括检查是否存在错误或异常。提供一个更接近实际编程环境的开发体验。 2、迭代精细化: 传统代码生成模型往往在初次生成后不再进行修改,而OpenCodeInterpreter通过引入迭代精细化过程,允许模型根据执行结果和人类反馈进行改进,从而生成更优质的代码,使生成的代码更加准确和高效。 3、集成人类反馈: 利用Code-Feedback数据集,该系统能够理解和应用人类给出的反馈,进一步优化代码生成过程。 Code-Feedback数据集: Code-Feedback数据集是OpenCodeInterpreter项目的核心组成部分,这个数据集包含68K多轮交互,既有用户指令也有编译器反馈,为代码生成提供了丰富的上下文,是OpenCodeInterpreter能够理解和应用人类反馈的关键。 多样化和具有挑战性的真实世界查询:数据集应涵盖来自真实世界编码任务的广泛查询,展现多样性和复杂性。 多轮对话结构:Code-Feedback采用多轮对话结构,包括两种类型的反馈:执行反馈(包括编译器的输出和诊断)和人类反馈(包含用户的额外指导或指令)。 交织的文本和代码响应:每个响应旨在提供融合自然语言解释和代码片段的解决方案,提供解决编码查询的全面方法。 每一轮交互都包括用户的编程指令和对应的编译器反馈,可能还包括人类提供的额外反馈。这些特点使得OpenCodeInterpreter能够: 理解编程任务:通过分析用户的指令来识别他们想要完成的编程任务。 学习从错误中改进:通过编译器反馈识别代码中的错误,并根据这些信息调整代码生成策略。 集成人类反馈:利用来自人类的反馈来进一步精细化代码,使其更加符合用户的预期和实际需求。 性能如何? 1、基准测试性能:在如HumanEval、MBPP及其通过EvalPlus增强的版本等关键基准上,OpenCodeInterpreter展示了卓越的性能。特别是,OpenCodeInterpreter-33B模型在HumanEval和MBPP的平均(及增强版本)上达到了83.2(76.4)的准确率,与GPT-4的84.2(76.2)相当。这表明OpenCodeInterpreter能够生成高质量的代码,与当前最先进的代码生成模型(如GPT-4)相竞争。 2、反馈增强性能:当集成了来自GPT-4的合成人类反馈后,OpenCodeInterpreter-33B的性能进一步提升,准确率达到91.6(84.6)。与GPT-4相媲美乃至超越的性能。这一结果突显了通过执行反馈和人类反馈进行动态代码精细化的有效性,以及OpenCodeInterpreter在迭代改进代码方面的能力。 3、技术创新和应用范围:OpenCodeInterpreter的创新不仅体现在其性能上,还体现在它能够执行代码并根据执行结果进行迭代精细化的能力上。这种集成执行和反馈的方法提供了一种新的方式,用于提高代码生成的准确性和适用性,尤其是在需要快速迭代和优化代码的场景中。 项目:https://opencodeinterpreter.github.io/ GitHub:https://github.com/OpenCodeInterpreter/OpenCodeInterpreter 论文:https://arxiv.org/abs/2402.14658 模型:https://huggingface.co/collections/m-a-p/opencodeinterpreter-65d312f6f88da990a64da456 在线演示:https://huggingface.co/spaces/m-a-p/OpenCodeInterpreter_demo







{kind=link}