

腾讯发布开源 Mixture of Experts(MoE)模型:腾讯混元大模型(Hunyuan-Large),这是目前在业界是规模最大的开源 Transformer 专家模型,具有 3890 亿参数,其中活跃的参数为 520 亿。
它专为提升自然语言处理、计算机视觉和科学任务而设计,在长文本处理、常识推理、数学能力等方面表现出色。
腾讯混元大模型(Hunyuan-Large)训练过程中使用了大量合成数据,使其可以学习到更丰富的语言表达方式。这种数据增强技术帮助 Hunyuan-Large 更好地泛化未见过的内容,提升对长文本的理解能力。
- KV 缓存压缩(KV Cache Compression)
- 分组查询注意力(Grouped Query Attention, GQA):通过 GQA 技术将注意力机制中的查询分组,大幅减少了模型在推理时的内存消耗,优化了计算效率。
- 跨层注意力(Cross-Layer Attention, CLA):使用 CLA 机制,Hunyuan-Large 可以在不同层次共享部分信息,从而降低存储和计算负担,进一步提高推理效率。这些改进使得模型在处理大规模输入时可以更高效地利用计算资源,适合资源受限的环境。
- 专家特定学习率(Expert-Specific Learning Rate)
- 针对不同子模型优化学习率:Hunyuan-Large 采用 MoE 架构中的专家机制,根据每个专家模型的特性设置不同的学习率。这一方法确保了各子模型能够从数据中有效学习,进而在整体上提升了模型的表现。
- 提高了模型的训练效率:专家特定学习率使得模型训练更具适应性,避免了“学习过度”或“学习不足”现象,最大限度地利用了每个专家模块的能力。
- 长上下文处理能力
- 预训练模型支持 256K 的上下文窗口:Hunyuan-Large 的预训练模型支持长达 256K 的上下文处理,这使得它在处理超长文本时依旧能保持较高的性能,不会遗漏关键上下文信息。
- Instruct 模型支持 128K 长度的文本输入:通过 Instruct 模型的优化,Hunyuan-Large 可以高效处理 128K 的指令任务输入,大幅扩展了其在处理长文档和复杂指令方面的能力。
基准测试与性能表现
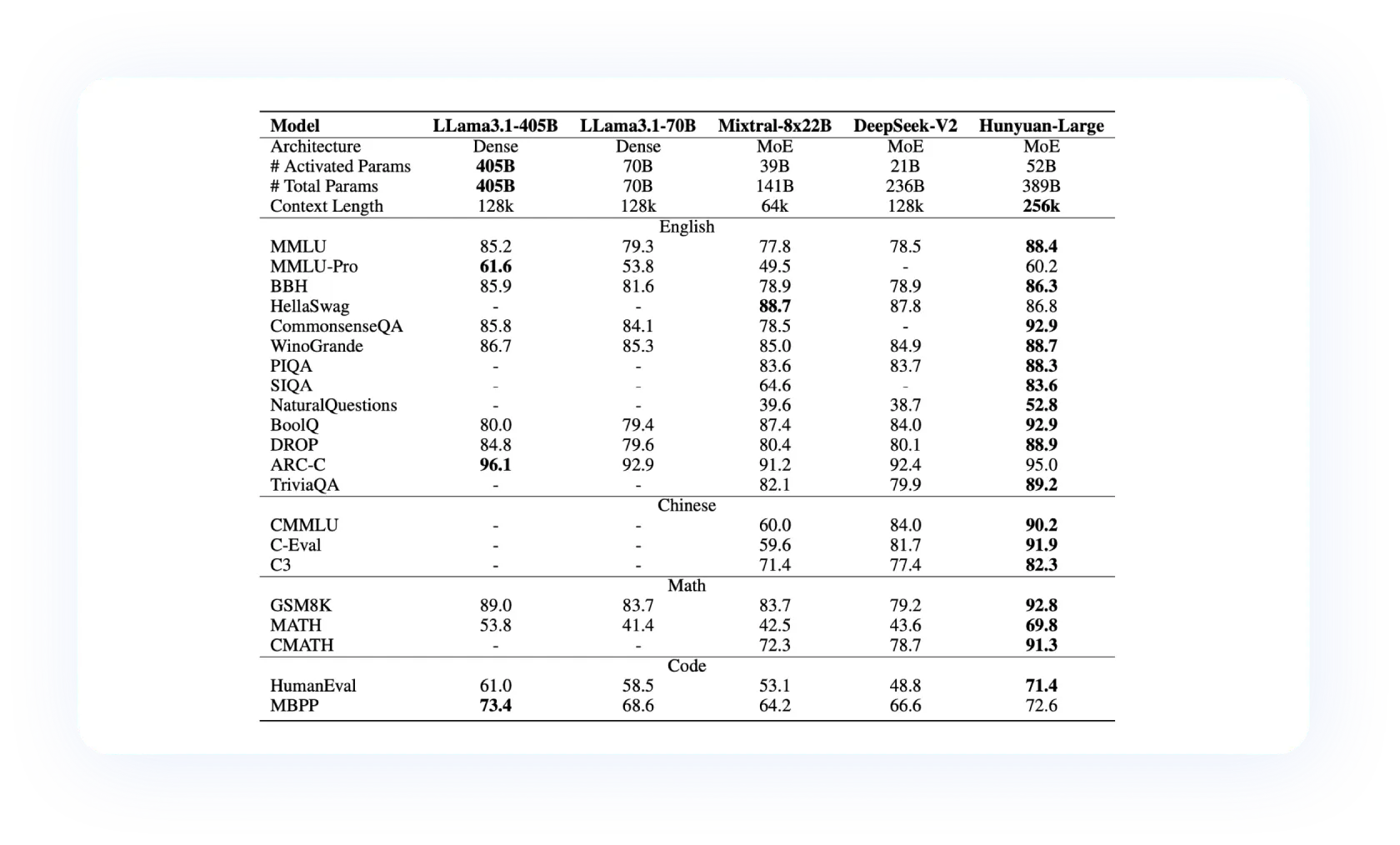
- 多项任务表现优越
- 常识和逻辑推理:在 CommonsenseQA 和 PIQA 等任务中,Hunyuan-Large 取得了显著的优势,证明了其在常识推理和逻辑推理任务中的高效性能。

- 阅读理解和问答任务:在 TriviaQA、NaturalQuestions 等阅读理解任务上,模型表现优异,尤其在复杂问答任务中展现了卓越的理解和回答能力。

- 数学推理能力:在 GSM8K 和 MATH 数据集上,Hunyuan-Large 的表现超过了所有其他基线模型,特别是在 CMATH(中文数学)数据集中也获得了最佳成绩,突显了其在数学和逻辑推理方面的实力。

- 常识和逻辑推理:在 CommonsenseQA 和 PIQA 等任务中,Hunyuan-Large 取得了显著的优势,证明了其在常识推理和逻辑推理任务中的高效性能。
- 中文任务的卓越表现
- C-Eval 和 CMMLU:在中国语言测试(如 C-Eval 和 CMMLU)中,Hunyuan-Large 展现出一流的性能,是同类开源模型中的佼佼者。尤其是在中文语境下的多项选择、阅读理解等任务中,该模型的准确性显著提升。
- 常识与推理能力:在中文常识推理(如 CMATH 和 CommonsenseQA 中文版)任务中,模型的准确率显著高于其他开源模型,表明其在中文理解和推理能力方面具有领先优势。
- 与其他模型的性能对比
- 与 Dense 模型和其他 MoE 模型的对比:Hunyuan-Large 在 MMLU、BBH 和 WinoGrande 等多个基准测试上均超过了 LLama3.1、Mixtral 和 DeepSeek 等同类模型。特别是在 MMLU 数据集上,Hunyuan-Large 的表现优于 LLama3.1-405B 模型,提升幅度达到 2.6%,充分展示了其在大规模任务上的理解和推理能力。
- 数学任务的表现:Hunyuan-Large 在 MATH 数据集上表现卓越,超越了 LLama3.1-405B 模型,准确率提升了 3.6%,表明其在数学推理任务中的显著优势。
官网:https://llm.hunyuan.tencent.com/













{kind=link}