
g1 是一个使用 Llama-3.1 70b 模型在 Groq 上创建类似 o1 的推理链的实验性应用。其主要功能和特性如下:
-
推理链功能:g1 利用 Llama-3.1 模型,通过动态的链式推理(Chain of Thought)来解决通常难以处理的逻辑问题。模型通过逐步推理和多方法验证,以提高逻辑问题的解决能力。
-
多方法推理:模型被要求使用至少 3 种不同的方法得出答案,并探索多种可能性,确保模型能够正确地解决问题。这种策略帮助 Llama-3.1 在 Strawberry 问题上的准确率从 0% 提升至 70%。
-
用户可视化:用户可以看到每一步推理过程的标题和内容,帮助理解模型的推理逻辑。
-
JSON格式输出:模型的每一步推理输出以 JSON 格式显示,包括标题、推理内容和下一步行动(继续或给出最终答案)。
g1 的工作原理基于使用 Llama-3.1 模型,通过提示策略改进逻辑推理能力。其具体工作过程如下:
-
动态推理链(Chain of Thought):
g1 利用动态推理链的原理,逐步引导 Llama-3.1 模型完成复杂的逻辑问题。每次解决问题时,模型不会直接给出答案,而是按步骤进行推理。每一步都有明确的标题和内容,确保推理过程可视化和结构化。 -
多步骤推理:
在 g1 中,Llama-3.1 模型被提示使用至少 3 种不同的推导方法来解决问题。这个多步骤的推理过程允许模型探讨不同的解决途径,避免因早期推理错误导致的最终答案错误。例如,在“草莓中有多少个 R”问题中,模型会被引导逐步拆解单词,并仔细检查每个字母。 -
迭代与自我校验:
模型会在每个推理步骤中重新审视之前的判断,并根据需要使用新的方法进行验证。这种迭代的自我校验机制有助于确保推理的准确性,避免简单错误。 -
JSON 格式的输出:
每个推理步骤的结果都会以 JSON 格式输出,包括:- title(标题):当前步骤的操作描述。
- content(内容):该步骤的具体推理细节。
- next_action(下一步行动):指示模型是否应继续推理还是提供最终答案。
-
提示策略:
g1 的提示策略优化了 Llama-3.1 模型的推理流程。通过提醒模型使用多种方法探索问题,并不断反思之前的推理,g1 提升了模型的整体推理性能。这种提示包括要求模型“重新检查并使用新的方法”以及“使用最佳实践”。
Examples 示例
g1 并不完美,但它的性能明显优于LLMs。根据初步测试,g1 能够准确解决 60-80%的简单逻辑问题,而这些问题通常会难倒LLMs。然而,准确性尚未正式评估。请参见下面的示例。
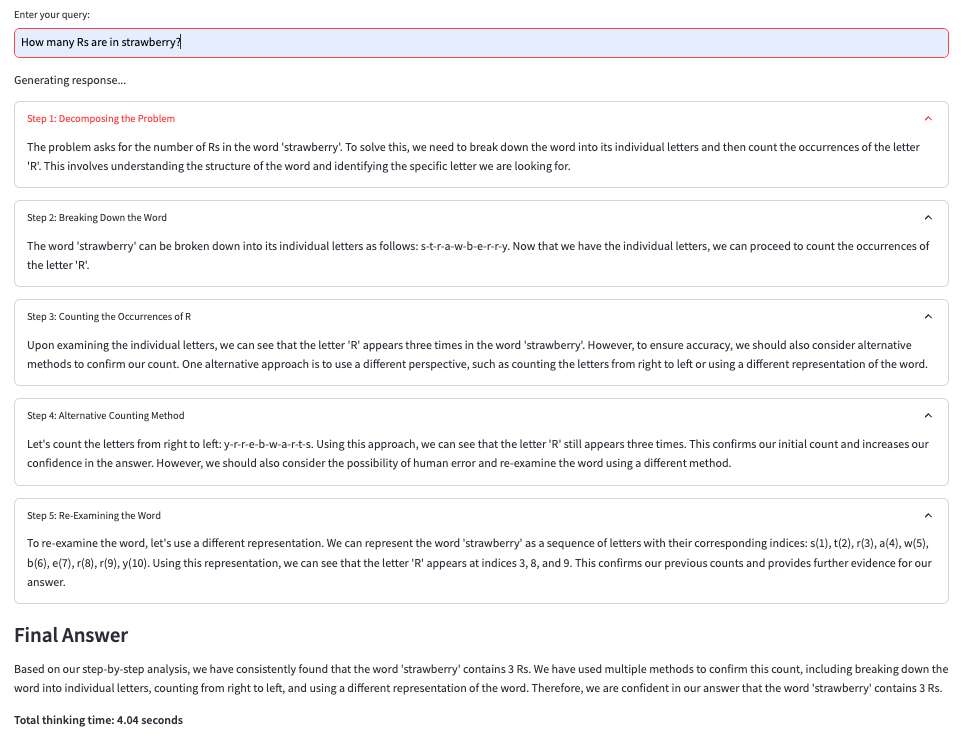
How many Rs are in strawberry?
草莓里有多少个 Rs?
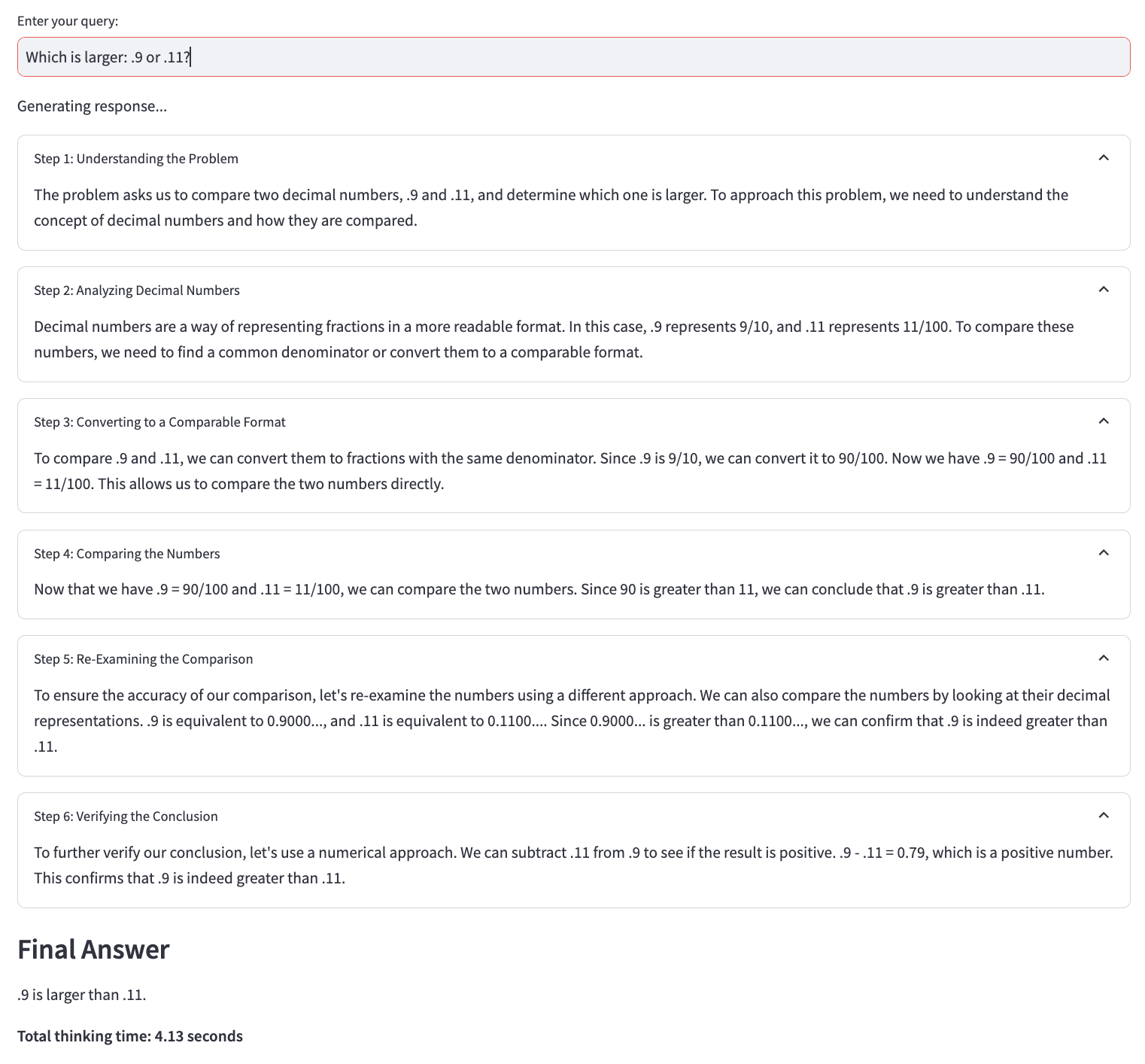
Prompt: Which is larger, .9 or .11?
提示:哪个更大,.9 还是 .11?
Result: 结果:













{kind=link}