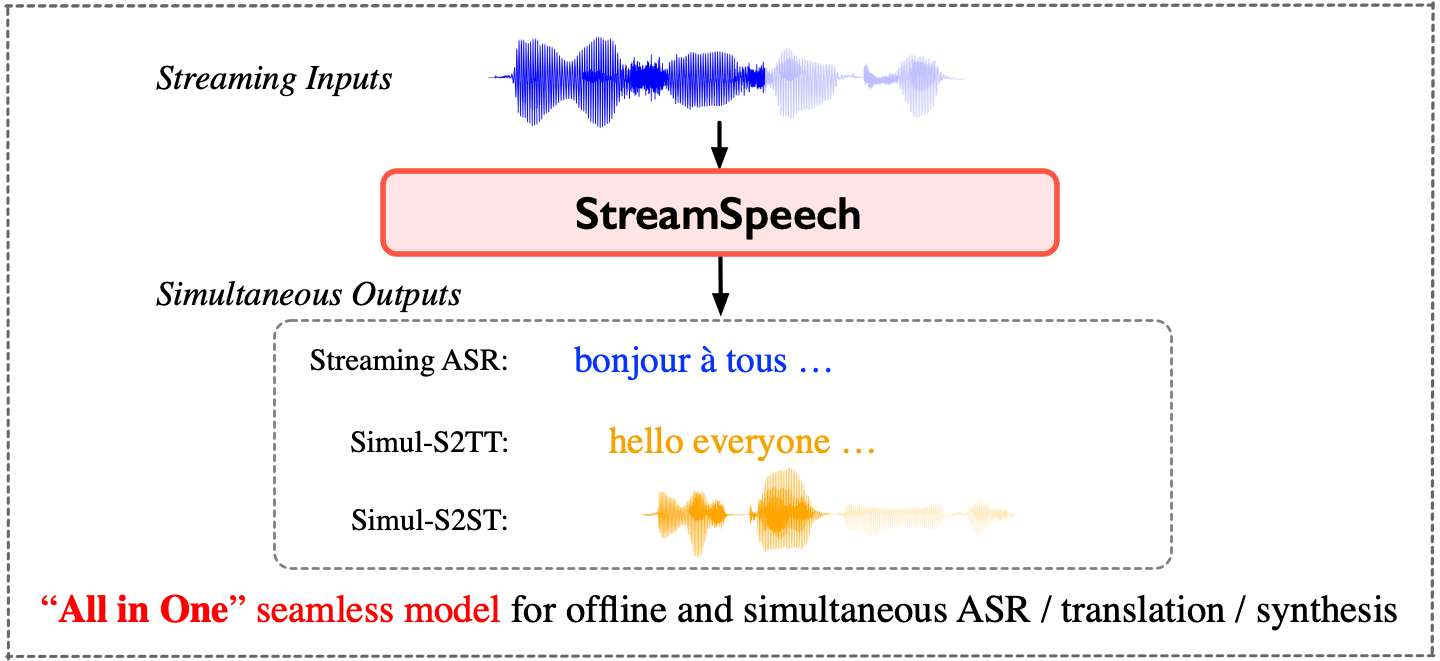
StreamSpeech 是一个用于实时语言翻译的先进模型,旨在实现流媒体语音输入的实时翻译。 用于在实时通信中将语音即时翻译成另一种语言,同时输出对应的目标语音。 Simul-S2ST不仅能将语音翻译成另一种语言,还能将语音内容实时转录为文本。这对于需要文本记录的场景,如会议记录、字幕生成等非常有用。用户可以同时获得语音和文本两种形式的翻译结果。 Simul-S2ST支持多种语言的翻译,能够在不同语言之间进行高效的语音翻译。 [video width="2272" height="1080" mp4="https://img.xiaohu.ai/2024/06/Area067.mp4"][/video] 它结合了语音识别(ASR)、语音翻译(Speech-to-Text Translation,S2TT)和语音合成(Speech Synthesis),通过多任务学习的统一框架,同时学习翻译和同步策略,从而在讲话人说话的同时生成目标语言的语音翻译。 <strong>技术优势</strong> <ul> <li><strong>统一框架</strong>:通过多任务学习的统一框架,同时优化语音识别、翻译和合成任务。</li> <li><strong>低延迟</strong>:在保持高质量翻译的同时,实现低延迟的实时翻译,适用于需要即时沟通的应用场景。</li> <li><strong>高性能</strong>:在各类基准测试中表现出色,确保翻译的准确性和流畅性。</li> </ul> <h4><img class="aligncenter size-full wp-image-9179" src="https://img.xiaohu.ai/2024/06/streamspeech.png" alt="" width="1440" height="661" />主要功能特点</h4> <ol> <li><strong>实时翻译</strong>: <ul> <li><strong>实时语音识别(ASR)</strong>:能够即时识别流媒体语音输入,并提供实时的语音转文本结果。</li> <li><strong>同步语音到文本翻译(Simul-S2TT)</strong>:Simul-S2ST不仅能将语音翻译成另一种语言,还能将语音内容实时转录为文本。这对于需要文本记录的场景,如会议记录、字幕生成等非常有用。用户可以同时获得语音和文本两种形式的翻译结果。</li> <li><strong>同步语音到语音翻译(Simul-S2ST)</strong>:实时生成目标语言的语音翻译,使其适用于需要低延迟、高质量翻译的场景,如国际会议、在线教育和跨语言交流等。</li> <li>这意味着翻译过程是同步进行的,无需等待整个语音输入结束,从而实现低延迟的实时翻译。</li> <li><strong>连续语音输入和输出:</strong>该系统能够处理连续的语音输入,自动识别并翻译源语言的语音,然后输出连续的目标语言语音。这种功能使得Simul-S2ST非常适合长时间的演讲或对话,不会因为句子或段落的结束而中断。</li> </ul> </li> <li><strong>中间结果展示</strong>在翻译过程中,StreamSpeech 能够提供高质量的中间结果,提升用户的实时通信体验: <ul> <li><strong>ASR 结果</strong>:在翻译过程中展示实时的语音识别结果,帮助用户即时了解翻译进度。</li> <li><strong>翻译结果</strong>:提供同步翻译的中间文本结果,进一步提升低延迟通信体验。</li> </ul> </li> <li><strong>高质量翻译和低延迟</strong>: <ul> <li><strong>高性能</strong>:在各种基准测试中,StreamSpeech 都表现出了最先进的翻译性能,确保翻译质量的同时,实现了低延迟的实时翻译体验。</li> <li>Simul-S2ST在翻译过程中具有极低的延迟,使用户几乎可以实时接收到翻译结果。这对于需要快速响应和即时沟通的场景,如谈判、紧急会议等非常关键。</li> <li><strong>中间结果展示</strong>:在翻译过程中能够提供高质量的中间结果(例如 ASR 或翻译结果),进一步提升了用户的实时通信体验。</li> </ul> </li> <li><strong>全面的语音处理能力</strong>: <ul> <li><strong>语音识别</strong>:StreamSpeech 能够进行高效的语音识别,及时展示识别结果。</li> <li><strong>语音翻译</strong>:支持多种语言之间的实时翻译,提升跨语言沟通的效率。</li> <li><strong>语音合成</strong>:通过非自回归的文本到单元生成,快速生成目标语言的语音输出。</li> </ul> </li> <li><strong>无缝集成</strong>该系统可以无缝集成到各种应用和设备中,如翻译耳机、会议系统、直播平台等,为用户提供便捷的翻译服务。无论是在个人设备上使用,还是在大型会议系统中应用,Simul-S2ST都能提供稳定的性能。</li> <li><strong>自适应翻译策略</strong>Simul-S2ST能够智能地判断何时开始翻译,并在适当的时刻生成目标语言的语音输出。这种自适应策略确保了翻译内容的连贯性和准确性,使得听众能够顺畅地理解翻译内容。</li> <li><strong>多语言支持</strong>StreamSpeech 支持多种语言之间的翻译,适应各种跨语言交流的需求: <ul> <li><strong>多语言翻译</strong>:目前支持多种语言对之间的翻译,如法语到英语、西班牙语到英语和德语到英语。</li> <li><strong>灵活扩展</strong>:模型架构支持进一步扩展到更多语言,提升跨语言交流的广泛性。</li> </ul> </li> </ol> [video width="1156" height="720" mp4="https://img.xiaohu.ai/2024/06/6月18日.mp4"][/video] <h3>StreamSpeech 的技术方法</h3> StreamSpeech 采用多任务学习框架,同时处理多个任务,如语音识别(ASR)、语音翻译(S2TT)、和语音合成(TTS)。这种方法通过共享模型参数,提高了不同任务的性能,并使得模型能够在一个统一的框架内学习到更全面的语言表示。 <h4><img class="aligncenter size-full wp-image-9178" src="https://img.xiaohu.ai/2024/06/model-1.png" alt="" width="2187" height="793" />1. <strong>两步架构</strong></h4> StreamSpeech 采用两步架构,将翻译过程分为两个阶段: <ul> <li><strong>阶段一:自动回归语音到文本翻译(AR-S2TT)</strong>:首先,将源语音转换为目标文本的隐藏状态。这一步类似于将说话人的话实时转录成文本。</li> <li><strong>阶段二:非自回归文本到单元生成(S2UT)</strong>:然后,通过非自回归的方式,将目标文本生成对应的目标语音。这一步将文本转换成语音输出。</li> </ul> <h4>2. <strong>多任务学习</strong></h4> StreamSpeech 通过多任务学习框架,同时进行多个任务的训练和优化: <ul> <li><strong>语音识别(ASR)</strong>:识别并转录输入语音,将其转换为源文本。</li> <li><strong>语音到文本翻译(S2TT)</strong>:将转录文本翻译成目标语言文本,用于非自回归的语音到文本翻译。</li> <li><strong>语音合成(Speech Synthesis)</strong>:将目标语言文本生成对应的语音,用于语音合成</li> </ul> <h4>3. <strong>CTC 解码器</strong></h4> StreamSpeech 引入了源/目标/单元 CTC(Connectionist Temporal Classification)解码器,用于学习源语音、目标文本和单元之间的对齐关系。通过 CTC 解码器,模型能够学习到源语音和目标文本之间的对齐信息,从而指导翻译过程中的读取(READ)和写入(WRITE)操作。这些解码器在多任务学习过程中,通过以下任务来指导模型的识别、翻译和合成: <ul> <li><strong>源语音到文本的对齐(ASR)</strong>:帮助模型识别何时开始识别语音。</li> <li><strong>非自回归语音到文本翻译(NAR-S2TT)</strong>:帮助模型在实时翻译过程中学习语音与文本的对齐。</li> <li><strong>语音到单元翻译(S2UT)</strong>:帮助模型在生成目标语音时实现高效对齐。</li> </ul> <h4>4. 模型结构</h4> <h5>4.1 流式语音编码器(Streaming Speech Encoder)</h5> <ul> <li><strong>结构</strong>:采用了块(chunk)基的 Conformer 架构,该架构在处理流式输入时,能够在局部块内进行双向编码,同时在块之间进行单向编码。</li> <li><strong>实现</strong>:首先将原始语音输入转换为语音特征,然后将这些特征划分为块进行编码。块内的自注意力(self-attention)和卷积操作(convolution operations)只在块内进行,而在块之间则是单向的,从而适应流式输入的需求。</li> </ul> <h5>4.2 同步文本解码器(Simultaneous Text Decoder)</h5> <ul> <li><strong>功能</strong>:在流式语音编码器生成的隐藏状态基础上,同时生成目标文本。</li> <li><strong>策略</strong>:模型需要决定何时生成每个目标标记(token),这依赖于源语音和目标文本之间的对齐。</li> <li><strong>实现</strong>:引入源 CTC 解码器和目标 CTC 解码器,通过辅助任务(ASR 和 NAR-S2TT)进行优化,指导模型何时进行识别(READ)和翻译(WRITE)。</li> </ul> <h5>4.3 非自回归文本到单元生成(Non-autoregressive Text-to-Unit Generation)</h5> <ul> <li><strong>结构</strong>:由 T2U 编码器和单元 CTC 解码器组成。T2U 编码器接受同步文本解码器的输出,并通过单元 CTC 解码器生成目标语音单元。</li> <li><strong>优化</strong>:通过 S2UT 任务进行优化,使用 CTC 损失函数(CTC loss)。</li> </ul> <h4>5. 训练与推理</h4> <h5>5.1 多任务联合优化</h5> 所有任务(S2UT、AR-S2TT、ASR 和 NAR-S2TT)通过多任务学习在一个端到端的框架中进行联合优化。总训练目标包含所有任务的损失函数,确保模型在各个任务上都能获得良好的性能。 <h5>5.2 多块训练(Multi-chunk Training)</h5> 为了提高模型在不同延迟条件下的性能,StreamSpeech 采用了多块训练的方法。训练时,流式语音编码器的块大小是随机采样的,从而使模型能够适应不同的延迟需求。 <h5>5.3 推理策略</h5> 推理过程中,StreamSpeech 根据设定的块大小(C)处理流式语音输入。模型通过 CTC 解码器生成当前收到的语音对应的源和目标标记,然后根据这些标记生成目标语音单元,并通过 HiFi-GAN 声码器合成目标语音。 <h3>实验与结果</h3> <h4>数据集</h4> 在CVSS-C基准(法语到英语、西班牙语到英语和德语到英语)上进行了实验。这些数据集来源于CoVoST 2语音到文本翻译语料库,通过最先进的文本到语音(TTS)系统合成目标语音。 <h4>离线S2ST结果</h4> 在离线语音到语音翻译(S2ST)任务中,StreamSpeech展示了卓越的性能,超过了目前最先进的UnitY模型,平均提升了1.5 BLEU分数。 <ul> <li><strong>法语到英语(Fr→En)</strong>:StreamSpeech达到了28.45 BLEU(UnitY: 27.77)。</li> <li><strong>西班牙语到英语(Es→En)</strong>:StreamSpeech达到了27.25 BLEU(UnitY: 24.95)。</li> <li><strong>德语到英语(De→En)</strong>:StreamSpeech达到了20.93 BLEU(UnitY: 18.74)。</li> </ul> 不同模型在Fr→En、Es→En和De→En任务上的详细性能对比: <img class="aligncenter size-full wp-image-9177" src="https://img.xiaohu.ai/2024/06/offline_s2st.png" alt="" width="3334" height="1196" /> <h4>同时S2ST结果</h4> 在同时语音到语音翻译(Simul-S2ST)任务中,StreamSpeech在不同的延迟条件下均优于Wait-k策略,特别是在低延迟条件下,有大约10 BLEU的提升。 <ul> <li><strong>法语到英语(Fr→En)</strong>:StreamSpeech的ASR-BLEU在所有延迟下均高于Wait-k,低延迟下提升约10 BLEU。</li> <li><strong>西班牙语到英语(Es→En)</strong>:类似结果,StreamSpeech在所有延迟下均表现出优越的性能。</li> <li><strong>德语到英语(De→En)</strong>:类似结果,StreamSpeech在所有延迟下均表现出优越的性能。</li> </ul> <h4>多任务学习效果</h4> 通过引入辅助任务(ASR、NAR-S2TT等),显著提升了StreamSpeech在S2ST任务上的性能。多任务学习为模型提供了阶段性的中间监督,提升了整体翻译质量和效率。 <ul> <li><strong>ASR(语音识别)</strong>:引入ASR任务后,StreamSpeech的识别错误率(WER)显著降低。</li> <li><strong>NAR-S2TT(非自回归语音到文本翻译)</strong>:辅助的NAR-S2TT任务提供了中间翻译结果,提升了整体翻译性能。</li> <li><strong>AR-S2TT(自回归语音到文本翻译)</strong>:主要用于生成高质量的翻译结果。</li> <li><strong>S2UT(语音到单元翻译)</strong>:用于语音合成部分,通过CTC损失进行优化。</li> </ul> 多任务学习对StreamSpeech性能的影响: <table> <thead> <tr> <th>模型设置</th> <th>ASR (WER)</th> <th>NAR-S2TT (BLEU)</th> <th>AR-S2TT (BLEU)</th> <th>S2UT (BLEU)</th> <th>S2ST (ASR-BLEU)</th> </tr> </thead> <tbody> <tr> <td>UnitY</td> <td>/</td> <td>31.31</td> <td>61.0</td> <td>33.47</td> <td>27.77</td> </tr> <tr> <td>StreamSpeech (完整)</td> <td>20.55</td> <td>23.82</td> <td>60.9</td> <td>32.60</td> <td>28.45</td> </tr> <tr> <td>StreamSpeech (无ASR)</td> <td>/</td> <td>22.95</td> <td>59.9</td> <td>31.56</td> <td>27.73</td> </tr> <tr> <td>StreamSpeech (无NAR-S2TT)</td> <td>20.70</td> <td>/</td> <td>62.3</td> <td>31.42</td> <td>28.18</td> </tr> </tbody> </table> <h4>速度提升</h4> StreamSpeech相对于UnitY模型在推理速度上有显著提升: <ul> <li><strong>法语到英语(Fr→En)</strong>:速度提升3.6倍</li> <li><strong>西班牙语到英语(Es→En)</strong>:速度提升4.5倍</li> <li><strong>德语到英语(De→En)</strong>:速度提升4.5倍</li> </ul> 表2展示了StreamSpeech相对于UnitY的速度提升: <table> <thead> <tr> <th>模型</th> <th>Fr→En (ASR-BLEU)</th> <th>速度提升</th> <th>Es→En (ASR-BLEU)</th> <th>速度提升</th> <th>De→En (ASR-BLEU)</th> <th>速度提升</th> </tr> </thead> <tbody> <tr> <td>UnitY</td> <td>27.77</td> <td>1.0×</td> <td>24.95</td> <td>1.0×</td> <td>18.74</td> <td>1.0×</td> </tr> <tr> <td>StreamSpeech</td> <td>28.45</td> <td>3.6×</td> <td>27.25</td> <td>4.5×</td> <td>20.93</td> <td>4.5×</td> </tr> </tbody> </table> <h4><strong>同步语音到语音翻译(Simul-S2ST)</strong></h4> StreamSpeech 在CVSS-C基准测试上的同步语音到语音翻译任务中同样表现出色。 <ul> <li><strong>实时性</strong>:通过优化的同步策略,实现了低延迟的实时翻译。</li> <li><strong>评估指标</strong>:实时BLEU分数和延迟(Latency)。</li> <li><strong>结果</strong>:在保证高翻译质量的同时,StreamSpeech 显示出低延迟的优势,使其适用于实时翻译场景。</li> </ul> <img class="aligncenter size-full wp-image-9176" src="https://img.xiaohu.ai/2024/06/simul_s2st.png" alt="" width="3340" height="1312" /> <h4><strong>流媒体语音识别(Streaming ASR)</strong></h4> StreamSpeech 在流媒体语音识别任务中的表现也非常优秀。 <ul> <li><strong>基准测试数据</strong>:使用了CVSS-C数据集中的流媒体语音数据进行评估。</li> <li><strong>评估指标</strong>:词错误率(Word Error Rate, WER)。</li> <li><strong>结果</strong>:StreamSpeech 在流媒体语音识别任务中的WER显著低于其他现有模型,证明了其在实时语音识别中的准确性和鲁棒性。</li> </ul> <img class="aligncenter size-full wp-image-9175" src="https://img.xiaohu.ai/2024/06/asr.png" alt="" width="1268" height="642" /> <h4><strong>同步语音到文本翻译(Simultaneous S2TT)</strong></h4> 在同步语音到文本翻译任务中,StreamSpeech 展现了卓越的性能。 <ul> <li><strong>基准测试数据</strong>:同样使用了CVSS-C数据集进行评估。</li> <li><strong>评估指标</strong>:实时BLEU分数和延迟(Latency)。</li> <li><strong>结果</strong>:StreamSpeech 在同步翻译任务中不仅保持了高BLEU分数,还显著降低了翻译延迟,实现了快速而准确的翻译。</li> </ul> <img class="aligncenter size-full wp-image-9174" src="https://img.xiaohu.ai/2024/06/s2tt.png" alt="" width="1306" height="913" /> <h4></h4> 项目及演示:<a href="https://ictnlp.github.io/StreamSpeech-site/" target="_blank" rel="noopener">https://ictnlp.github.io/StreamSpeech-site/</a> GitHub:<a href="https://github.com/ictnlp/StreamSpeech" target="_blank" rel="noopener">https://github.com/ictnlp/StreamSpeech</a> 论文:<a href="https://arxiv.org/pdf/2406.03049" target="_blank" rel="noopener">https://arxiv.org/pdf/2406.03049</a> 模型下载:<a href="https://huggingface.co/ICTNLP/StreamSpeech_Models/tree/main" target="_blank" rel="noopener">https://huggingface.co/ICTNLP/StreamSpeech_Models/tree/main</a>






{kind=link}









