

- HuggingFace Open LLM LeaderBoardHuggingFace 公开LLM 排行榜
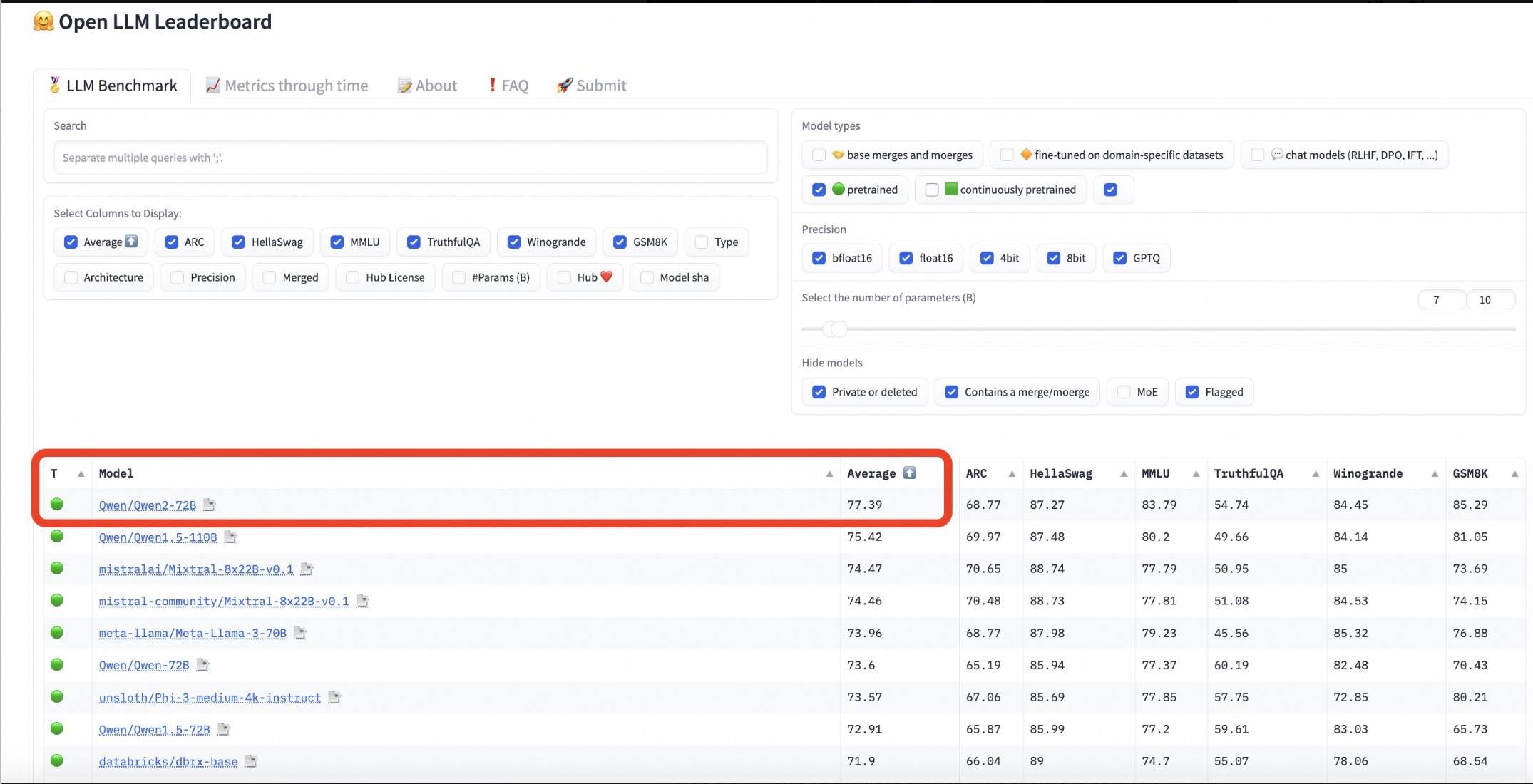
- Qwen2发布后两小时,Hugging Face联合创始人兼首席执行官克莱门特·德朗格发推宣布,各位,HF开源大模型榜单新的第一出来了,Qwen2-72B
- 该排行榜被认为是当前大模型领域最具权威性的榜单之一,评测维度涵盖阅读理解、逻辑推理、数学计算、事实问答等六大评测,收录了全球上百个开源大模型。
- OpenCompass
- Qwen-72B在上海人工智能实验室的OpenCompass开源基座大模型竞技场榜单中夺冠。OpenCompass评测平台涵盖学科、语言、知识、理解、推理等五大维度,并支持50余个数据集的评测,评测对象包括Qwen、LLaMA2等开源模型及GPT-4、ChatGPT等主流模型。
模型架构及训练
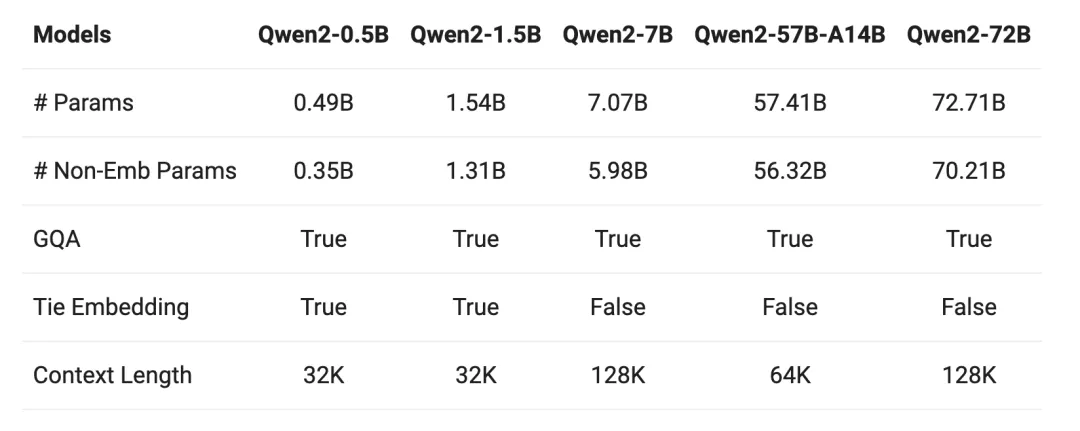
共包含5种不同尺寸的模型,分别为Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。每个模型的大小不同,适用于不同的应用场景和需求。
模型尺寸
- Qwen2-0.5B:这是最小的模型,适用于资源有限的设备或对计算资源要求较低的任务。
- Qwen2-1.5B:适用于中等规模的任务,能够处理比0.5B模型更复杂的任务。
- Qwen2-7B:这是一个中大型模型,适用于需要较强语言处理能力的任务。
- Qwen2-57B-A14B:这是一个大规模模型,适用于需要高性能和精确度的任务。
- Qwen2-72B:这是系列中最大的模型,适用于需要处理非常复杂任务和大量数据的场景。
 使用GQA技术
使用GQA技术
所有尺寸的模型都使用了GQA(Generalized Query Attention)技术,这项技术能够显著提升推理速度并降低显存占用。简单来说,GQA让模型可以更快地处理数据,并且在使用显存方面更加高效。
- 上下文长度
所有预训练模型都在32K tokens的数据上进行训练,这意味着它们可以处理很长的文本。在测试中,这些模型在处理128K tokens时依然表现良好。上下文长度越长,模型在处理长篇文本时的表现就越好。
- 指令微调模型
除了预训练模型,Qwen2系列还包含指令微调模型,这些模型专门针对特定任务进行了优化。例如,Qwen2-7B-Instruct和Qwen2-72B-Instruct可以处理长达128K tokens的上下文长度。这些模型通过YARN等技术扩展了其处理长文本的能力。
- 多语言能力
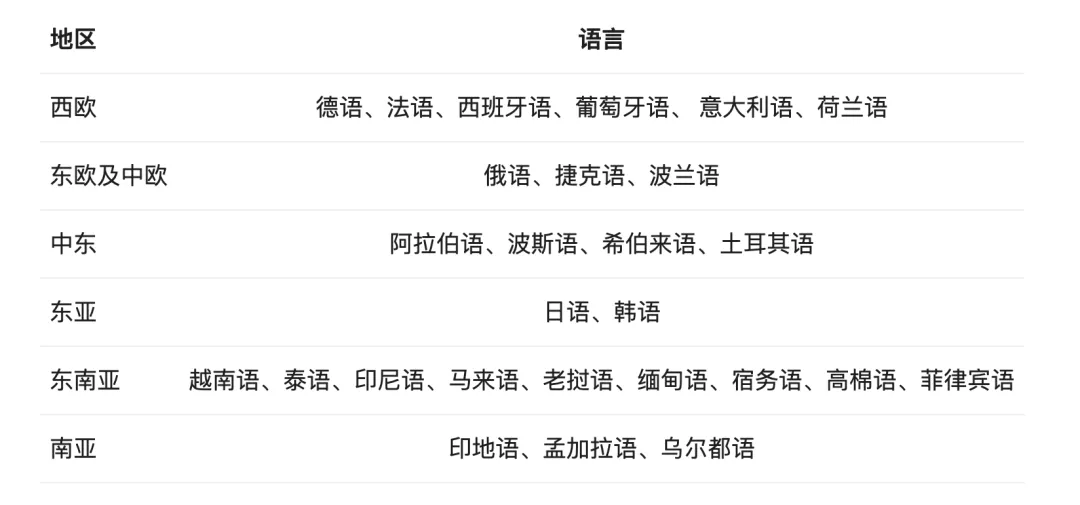
Qwen2系列模型针对27种语言进行了优化,特别是中英文以外的多语言处理能力得到了显著提升。这意味着模型在处理多语言任务时更高效,发生语言转换(code switch)的概率大大降低。
 共享参数技术
共享参数技术
针对较小的模型,使用了tie embedding技术,这种技术让输入和输出层共享参数,增加了非embedding参数的占比,使得模型在同样大小下更强大。
Qwen2模型测评结果
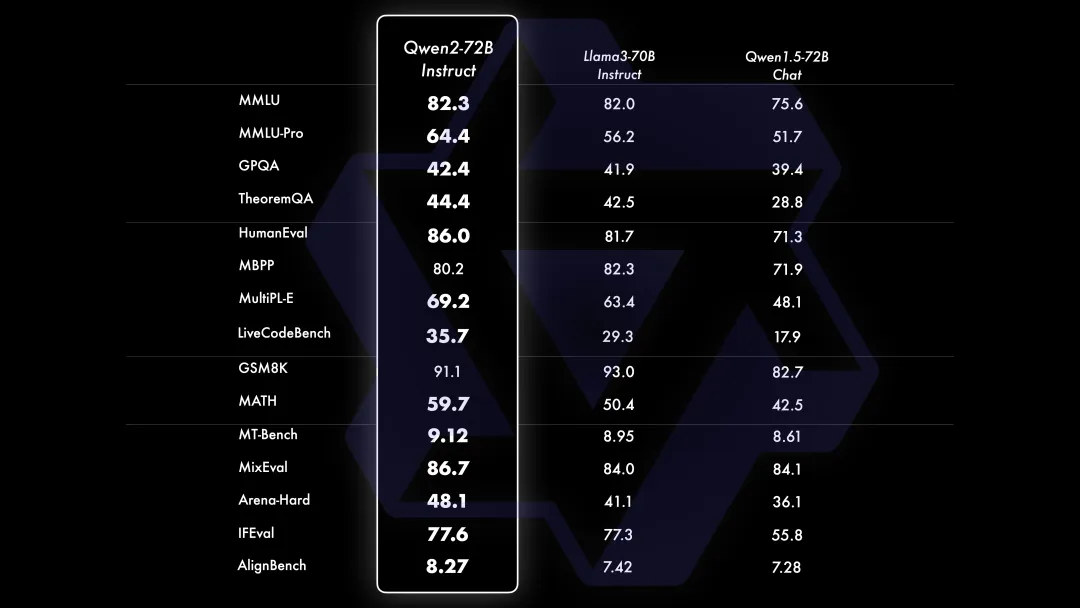
Qwen2系列模型在多个方面的测评结果显示,它们在各项任务中的表现都非常优异。以下是一些关键的测评结果和亮点:
自然语言处理能力
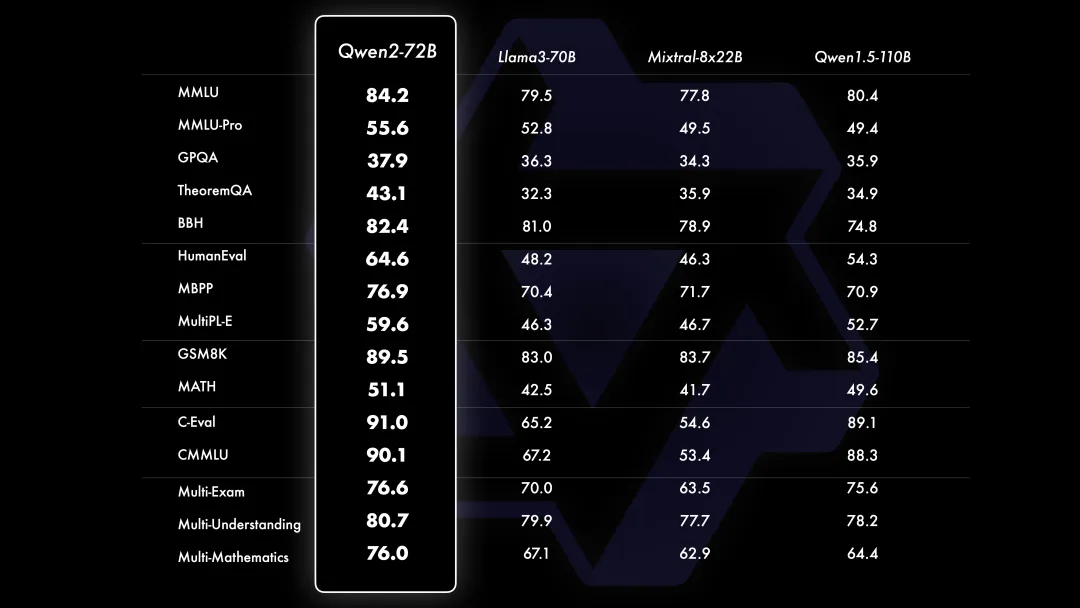
Qwen2-72B模型在自然语言理解、知识掌握、代码生成、数学能力及多语言处理等方面均显著优于当前最好的开源模型,如Llama-3-70B和Qwen1.5系列的最大模型Qwen1.5-110B。
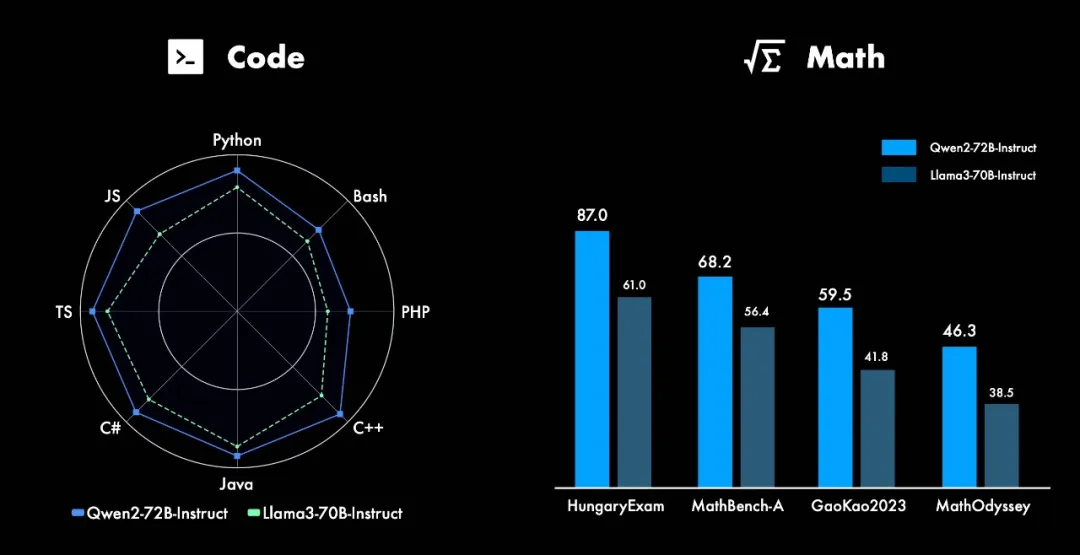
 代码和数学能力
代码和数学能力
- 代码能力:Qwen2系列模型在多种编程语言上的表现都有显著提升,尤其是在代码生成和理解任务上表现突出。
- 数学能力:大规模且高质量的数据帮助Qwen2-72B-Instruct在数学解题能力上取得了飞跃式的进步。
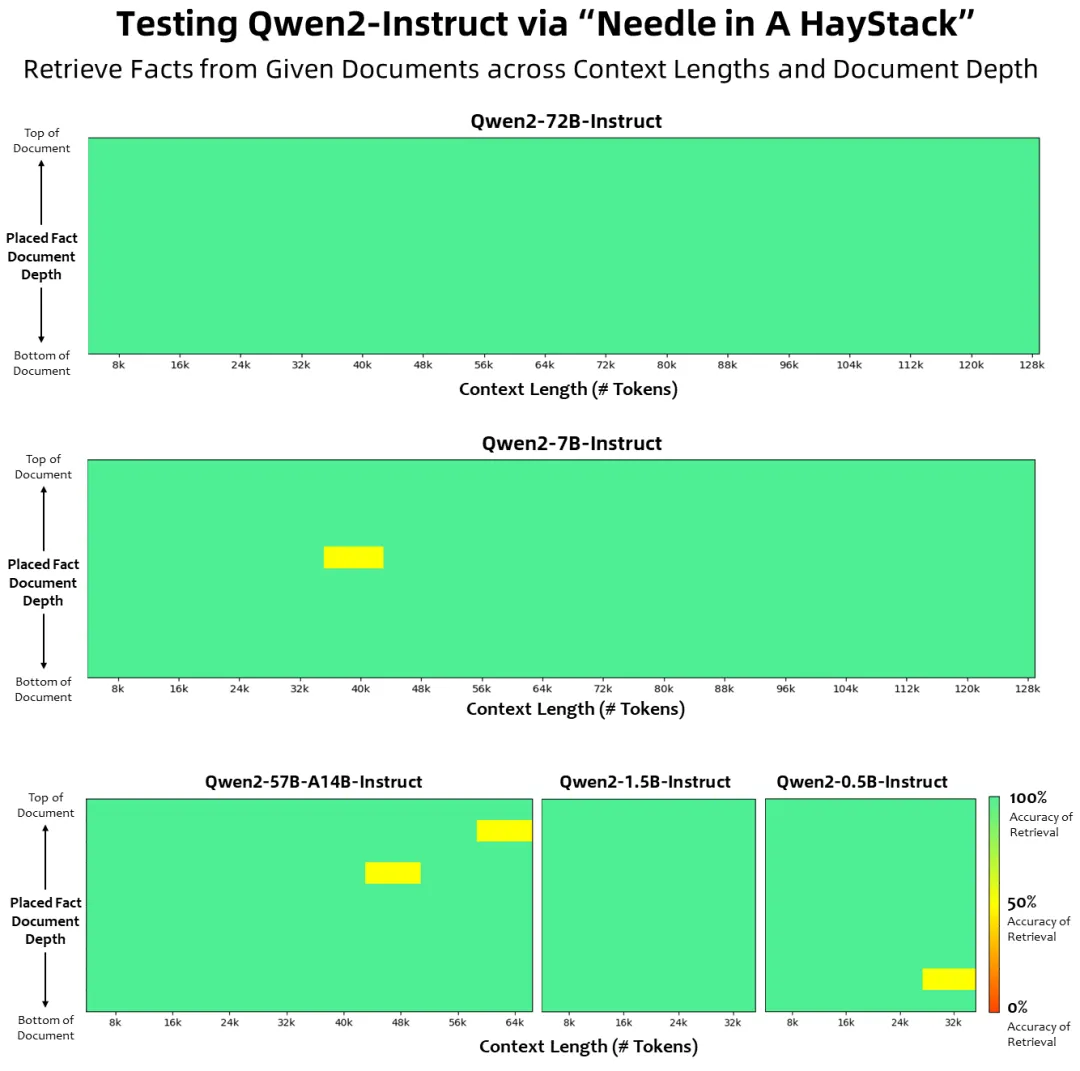
 长文本处理
长文本处理
- Qwen2系列模型在处理长文本方面表现优异,所有Instruct模型均在32K tokens上下文长度上进行训练,并通过YARN或Dual Chunk Attention等技术扩展至更长的上下文长度。
- Qwen2-72B-Instruct能够处理长达128K tokens的上下文长度任务,表现非常稳定。
- 其他模型如Qwen2-7B-Instruct和Qwen2-57B-A14B-Instruct也能分别处理128K和64K tokens的上下文长度。
 多语言处理
多语言处理
Qwen2系列模型在多语言处理能力上表现出色,尤其在中英文以外的27种语言上有显著提升。语言转换(code switch)现象大幅减少,模型能够更流畅地处理多语言内容。
安全性
- Qwen2-72B-Instruct在处理多语言不安全查询(如非法活动、欺诈、色情、隐私暴力)方面,与GPT-4表现相当,并显著优于Mixtral-8x22B模型。
- 测试数据来自Jailbreak并被翻译成多种语言进行评估,Qwen2系列模型在安全性方面得到了充分验证。
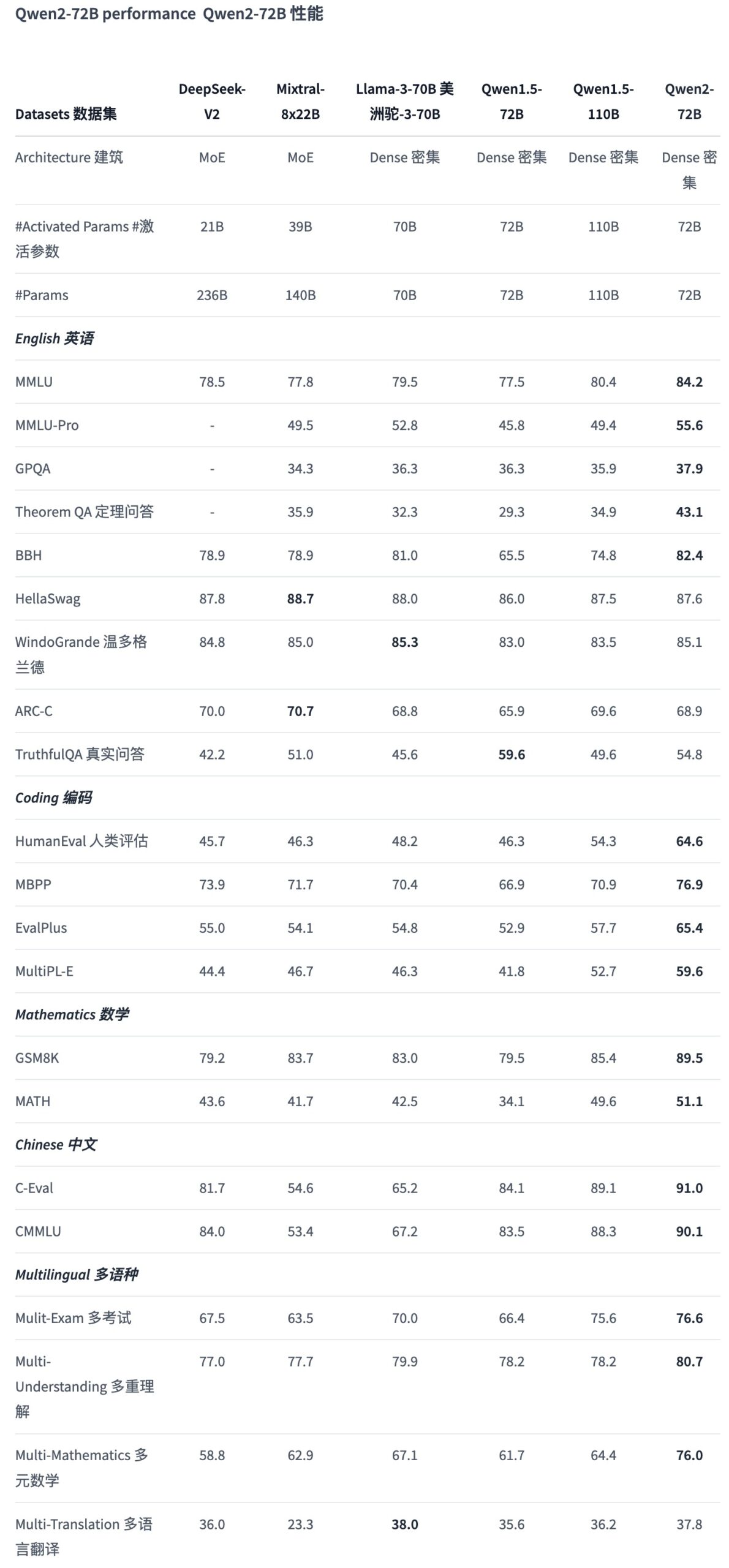
详细评测结果
- 自然语言理解:Qwen2-72B在自然语言理解基准测试中表现卓越,超越了包括Llama-3-70B在内的其他领先模型。
- 知识掌握:在知识测评任务中,Qwen2-72B表现出色,能够回答各种复杂的问题。
- 代码生成:在代码生成任务中,Qwen2系列模型尤其在多语言编程环境下表现优异。
- 数学能力:Qwen2-72B-Instruct通过大量高质量的数学数据训练,在数学问题解决上表现出色。
- 多语言处理:针对27种语言进行了优化,减少了语言转换现象,提升了模型的多语言处理能力。
- 长文本处理:Qwen2-72B-Instruct和其他模型在处理长文本任务上表现稳定,能够有效处理超长上下文。
模型现已开源在Hugging Face和ModelScope上,详细用法请参见模型卡。
模型下载:
GitHub:https://github.com/QwenLM/Qwen2
在线体验:https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
竞技场体验:https://modelscope.cn/studios/opencompass/CompassArena/summary













{kind=link}