
RAFT(Retrieval Augmented Fine-tuning)是一种新的技术方法,用于改善大语言模型(LLMs)在执行检索增强生成(RAG,Retrieval Augmented Generation)任务时的性能。这种方法结合了传统的检索增强生成和领域特定微调的优势,旨在提高模型的领域适应能力和生成回答的质量。
RAFT可以显著提升大型语言模型在执行检索增强生成任务时的性能,尤其是在需要高度精准和专业知识的领域中。通过这种方法,模型不仅能生成高质量的文本,还能展示出更高的逻辑推理能力和领域适应性。

RAFT解决了什么问题?
-
提高领域适应性:
- 在处理特定领域(如法律、医疗或银行等)的查询时,传统的领域特定微调方法(DSF)涉及在代表该领域知识的文档集上训练现有基础模型。而RAG方法则在查询时从向量数据库中检索文档。RAFT通过更系统地结合这两种方法,提前让模型“学习”或适应相关领域的信息,从而在实际的RAG设置中使用时,能够更好地理解和生成相关的回答。
-
提高生成质量和准确性:
- 传统RAG方法在处理用户查询时可能会检索到与查询语义相近但内容上并不相关的文档,这可能导致生成的回答包含误导信息或“干扰”内容。RAFT方法通过在RAG设置之前对模型进行领域微调,使其能够更好地区分哪些文档是真正相关的,从而提高回答的相关性和质量。
-
克服传统方法的局限:
- 在传统的微调方法中,模型的性能受限于其训练数据。而在RAG中,虽然模型可以访问大量的开放书籍数据,但它们通常基于文档与查询的语义接近性来检索信息,这可能导致选择不适当的文档。RAFT通过结合两种方法的优势,使模型能在开放书籍考试中表现得更像是事先已经复习过相关教材的学生。
-
适用于特定需求的场景:
- RAFT特别适用于那些需要高度专业知识的领域,如医疗或法律,其中准确性和专业性至关重要。此外,RAFT方法还可以根据特定的业务需求和挑战,帮助企业和开发者创建定制化的解决方案。
RAFT的主要能力
RAFT(Retrieval Augmented Fine-tuning)方法为大型语言模型(LLMs)提供了一系列强大的能力,使其在执行检索增强生成(RAG)任务时更为高效和精准。以下是RAFT的一些核心能力:
-
领域特定的微调:RAFT 专为领域特定的 RAG 场景设计,允许模型在回答问题时利用特定领域的文档。在训练过程中,RAFT 教导模型如何识别并使用那些能够帮助回答问题的文档,同时忽略无关的干扰文档。
-
改进的领域适应性:RAFT使模型能够在具体领域(如医疗、法律或金融)中表现得更好。通过在相关领域的文档上进行预先微调,模型在处理特定类型的查询时可以更准确地理解和响应。
-
增强的回答生成质量:与传统的RAG相比,RAFT通过领域微调来提前“学习”相关的文档,使得在实际查询时,模型能够更有效地从检索到的文档中提取和利用有价值的信息,从而生成更精确、更相关的回答。
-
减少干扰文档的影响:在常规的RAG设置中,模型可能会检索到与查询语义上相近但实际上并不相关的文档。RAFT通过先进的微调策略,帮助模型更好地辨识出真正有用的文档,从而避免因干扰文档而产生不准确或误导性的回答。
-
提升学习和推理能力:RAFT不仅限于改善文本生成,它还通过链式推理(Chain-of-Thought)的方法来增强模型的逻辑思维和问题解决能力。这种方法要求模型在生成答案前,先展示其推理过程,从而提高答案的逻辑性和可信度。
-
扩展到多种领域和语言:虽然RAFT特别适用于需要高度专业知识的领域,但其方法论也可适用于更广泛的应用场景,包括不同的行业和多种语言,使模型能够灵活应对多样化的环境和需求。
-
简化模型训练与部署:RAFT的实现通常依赖于高级的机器学习平台和工具(如Azure AI Studio),这些工具简化了数据准备、模型训练和部署过程,使开发者可以更专注于领域特定的任务,而无需深入了解底层的技术细节。

工作原理
RAFT结合了检索增强生成(RAG)和领域特定微调(DSF)的优势,目的是提高大型语言模型在特定领域的问答能力。下面详细介绍RAFT的工作原理:
1. 基本概念和组件
- 检索增强生成(RAG): 在RAG中,模型首先从一个大型的文档数据库中检索出与用户查询语义相近的文档,然后将这些文档作为上下文来生成答案。这种方法类似于“开卷考试”,模型可以访问相关资料来响应查询。
- 领域特定微调(DSF): 在DSF中,模型在特定领域的大量文档上进行训练,以吸收和学习该领域的专业知识和术语。
2. RAFT的核心步骤
- 预备阶段: 在传统的RAG模式中,模型直接在运行时检索文档。RAFT改变了这一流程,通过先对模型进行领域特定的微调,使模型在实际被用于生成回答前,已经对相关领域有了深入的了解。
- 创建合成数据集: RAFT方法首先使用一个基本的大型语言模型(如Llama 2)创建一个合成数据集。这个数据集包含:
- 问题:定义需要回答的具体问题。
- 文档集:包括与问题直接相关的文档和一些不相关的文档。这些文档被用来模拟真实场景中的信息检索环境。
- 答案和思路链解释:从相关文档生成答案,并提供一串基于文档内容的思路解释,以展示如何得出该答案。
- 微调模型: 使用上述合成数据集对模型进行微调,目的是让模型学会从复杂的、含有干扰信息的环境中提取关键信息,并生成准确的答案。微调时,也会强调思路链的生成,以增强模型的逻辑推理能力。
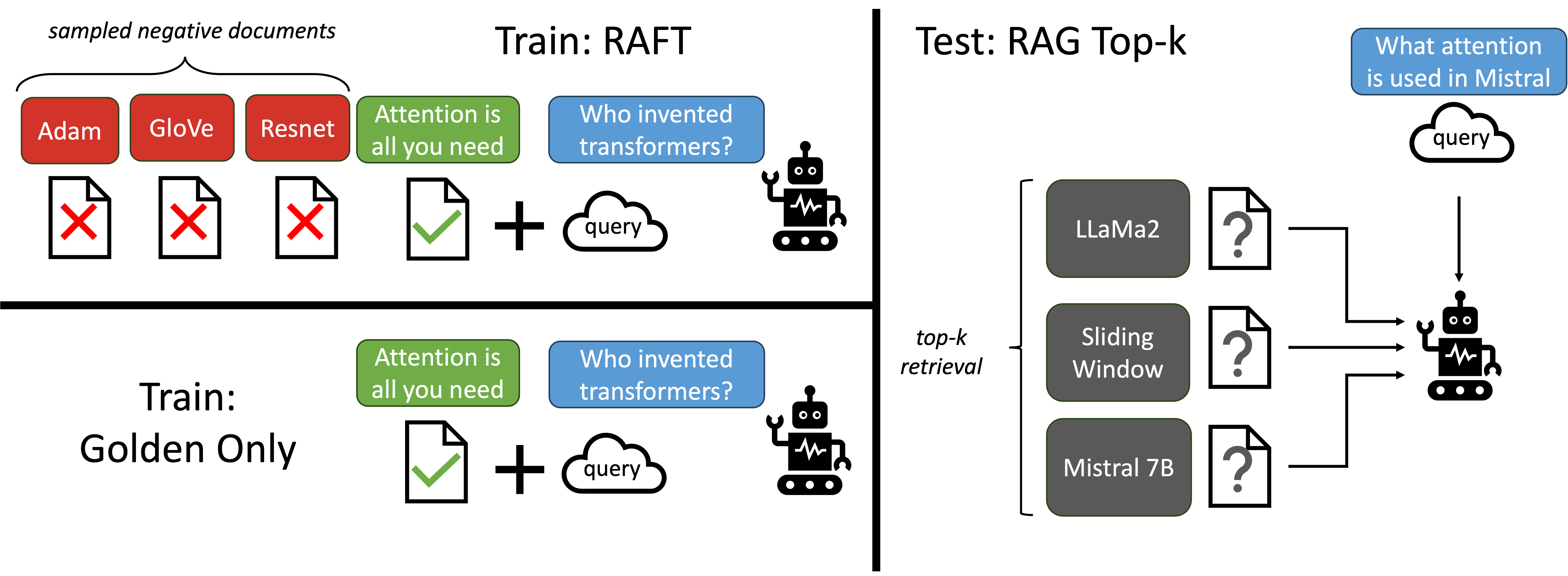
3. 改进和优化
- 上下文利用的优化: 在传统的RAG中,模型可能仅基于文档的语义相似性进行选择,这可能导致选择错误或不相关的文档。RAFT通过微调使模型更好地理解文档的实际内容,从而在实际应用中选择更加相关和准确的文档作为回答生成的依据。
- 防止过拟合和提高鲁棒性: 通过引入思路链(Chain-of-Thought)推理,RAFT不仅帮助模型生成更自然、更连贯的语言输出,同时也减少了过拟合的风险,提高了训练的鲁棒性。
性能结果
1. 数据集
- PubMed: 专门用于生物医学研究的问题回答数据集。RAFT 在这个数据集上的表现突出,能够有效地回答与医疗和生物学相关的问题。
- HotpotQA: 这是一个开放领域的问题回答数据集,主要关注基于维基百科的常识性问题。RAFT 在此数据集上展示了其在处理常规知识问题时的能力。
- Gorilla API Bench: 主要涉及如何根据文档生成正确的函数API调用。RAFT 在这一数据集上的应用表明,它能够准确地识别和使用API文档中的关键信息来回答相关问题。
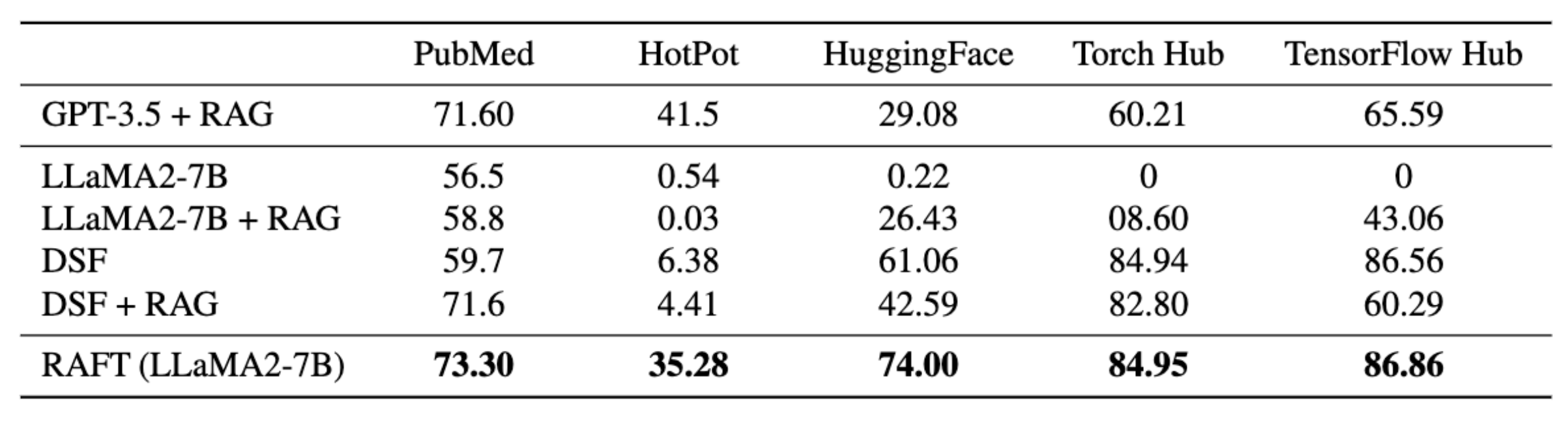
2. 性能提升
- RAFT 显示出在领域特定的“开卷”环境中,特别是在使用领域内文档回答问题时,其性能显著提升。这种性能提升归功于模型能够更有效地使用和引用相关文档中的信息。
- 模型通过训练忽略不相关的干扰文档,从而进一步提高了答案的准确性和相关性。
3. 对比基线模型
- LlaMA2-7B-chat model with 0-shot prompting: 通常用于问题回答任务的指令调整模型,没有引用文档。
- LlaMA2-7B-chat model with RAG (Llama2 + RAG): 类似于前者,但增加了参考文档,是处理特定领域问题回答任务时最常使用的组合。
带有 RAG 的 LlaMA2-7B 聊天模型(Llama2 + RAG): 类似于前者, - Domain-Specific Finetuning with 0-shot prompting (DSF): 没有文档上下文的标准指令微调。
- Domain-Specific Finetuning with RAG (DSF + RAG): 为域特定微调模型配备了外部知识的RAG,即使模型不了解某些“知识”,仍可以参考上下文。















{kind=link}