
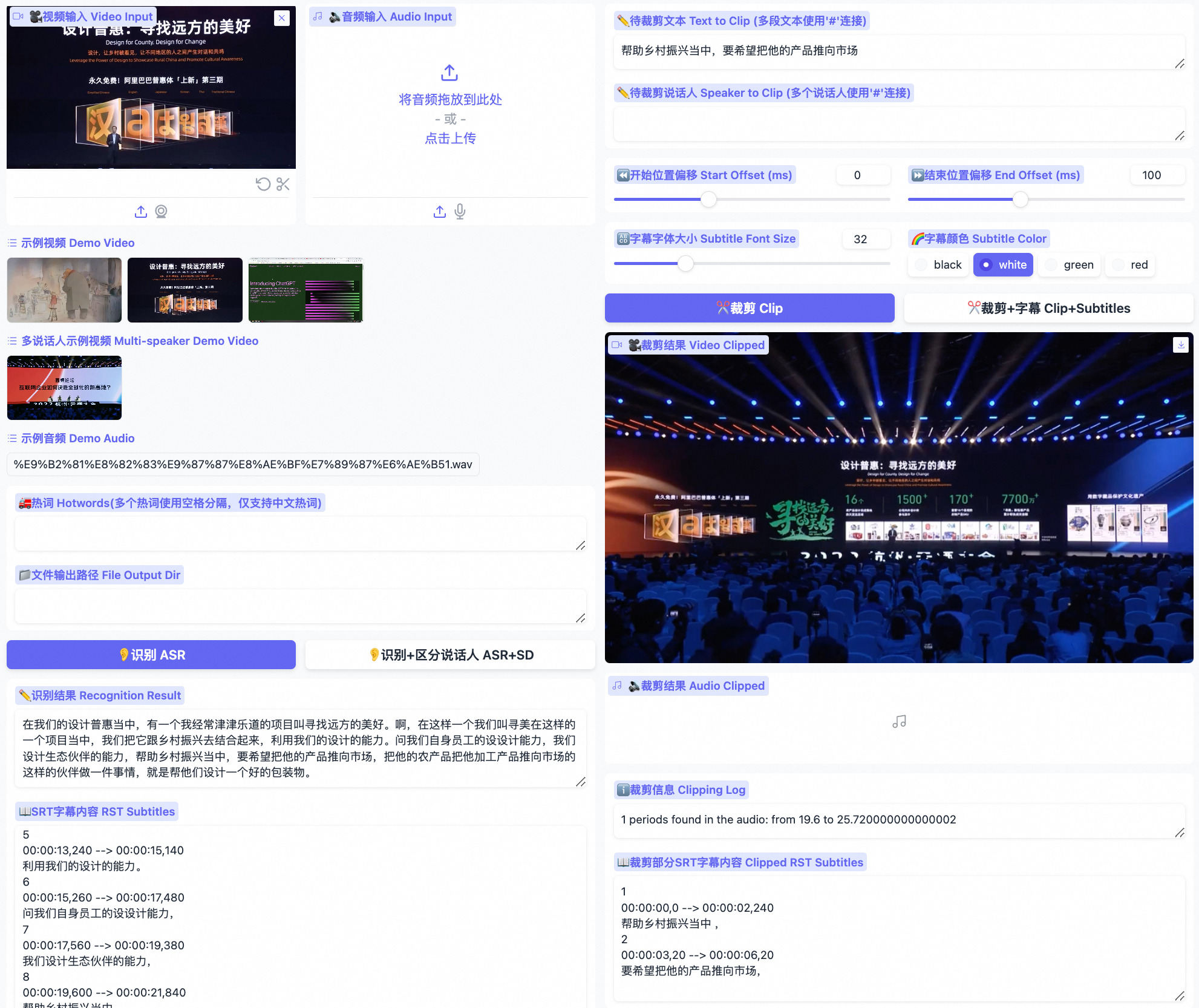
FunClip 是阿里巴巴通义实验室开源的一款视频剪辑工具,专门用于精准、便捷的视频切片。
主要功能
-
高精度语音识别:
- 利用阿里巴巴开源的 Paraformer-Large模型进行视频中的中文语音识别,该模型是当前市场上识别效果最佳的开源中文ASR模型之一。
- 支持热词定制化功能,可以在语音识别过程中定制特定的实体词、人名等,以提高识别的准确度。
-
视频裁剪与剪辑:
- 用户可以基于语音识别结果选择特定的文本片段或者说话人,进行视频的精确裁剪。
- 集成 CAM++说说话人识别模型,使得用户可以根据自动识别出的说话人ID来选择裁剪的视频段落。
-
用户界面与交互:
- 通过 Gradio 界面提供的交互式平台,用户可以方便地上传视频、设置参数并进行剪辑。
- 界面友好,安装简单,使用户即使没有编程背景也能轻松使用。
-
功能扩展性:
- 支持多段视频的自由剪辑,并能自动生成全视频及目标段落的SRT字幕,便于后续处理。
- 计划集成英文视频剪辑能力和大语言模型,进一步拓宽工具的应用范围和功能。
在线演示:modelscope.cn
FunASR介绍
FunASR 是阿里巴巴通义实验室开发的一款综合性语音识别工具包,提供端到端的语音识别解决方案和一系列开源的、性能优越的预训练模型。该工具包旨在桥接学术研究与工业应用,支持语音识别、语音活动检测(VAD)、标点恢复、语言模型、说话人验证和说话人区分等多种功能。
主要功能:
-
语音识别(ASR):
- 提供非自回归端到端语音识别模型,如Paraformer-large,具有高准确性、高效率和便于部署的特点。
- 支持多任务处理,如多语言识别、语音翻译和语言识别等。
-
语音活动检测(VAD)与标点恢复:
- 通过预训练模型进行有效的语音活动区段检测。
- 提供标点恢复功能,增强语音转写文本的可读性。
-
模型动态部署与优化:
- 支持预训练模型的微调和推理。
- 提供文件转录服务和实时转录服务,支持多种平台部署,如CPU和GPU。
GitHub:https://github.com/alibaba-damo-academy/FunASR
论文:https://arxiv.org/abs/2305.11013
Paraformer模型介绍
Paraformer 是一个非自回归端到端语音识别模型,由阿里巴巴达摩院语音团队开发。它是专为高效的GPU并行推理设计的,提供快速且准确的语音到文本的转换。此模型特别适用于处理长音频,集成了语音活动检测(VAD)、自动语音识别(ASR)、标点和时间戳功能。
它能够快速准确地将语音转换为文本。利用了最新的AI技术,可以处理非常长的音频记录,同时保持高准确率。非常适合需要处理大量语音数据的应用场景,如会议记录或语音输入法。Paraformer模型也支持自定义热词,这意味着可以优化模型以更好地识别特定词汇,这对于专业领域中的应用尤其有用。
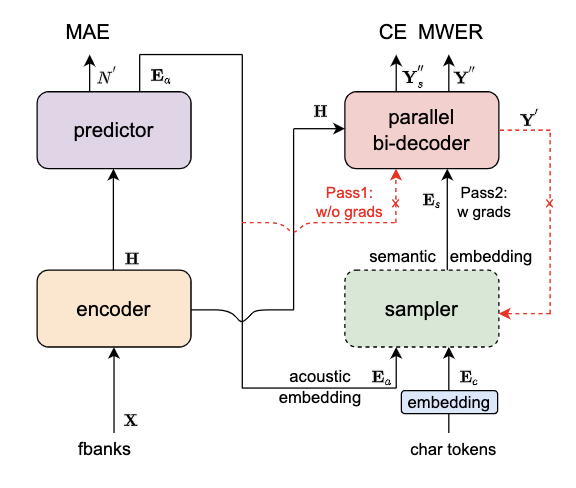
核心特点和功能:
-
高效的模型架构:
- Encoder: 可采用多种网络结构,如self-attention, conformer, SAN-M等。
- Predictor: 两层FFN,负责预测目标文字个数并抽取对应的声学向量。
- Sampler: 无可学习参数模块,将声学向量和目标向量转换为含有语义的特征向量。
- Decoder: 采用双向建模,类似自回归模型,但能够提供更高的效率和准确度。
- Loss Function: 包括交叉熵、MWER区分性优化目标及Predictor优化目标MAE。
-
功能拓展:
- 热词定制版模型: 支持基于热词列表的激励增强,提升热词的召回率和准确率。
- 长音频模型: 能够处理数小时长的音频,输出带标点和时间戳的文本。
-
应用场景:
- 适用于语音输入法、语音导航、智能会议纪要等多种应用场景。
- 非实时语音识别:从录音文件中解码文本。
- 实时语音识别:支持流式语音识别,能够在语音输入时实时输出文本。
模型地址:modelscope.cn
SeACo-Paraformer论文:https://arxiv.org/abs/2308.03266













{kind=link}