
InternVL 1.5由上海人工智能实验室开发,一个旨在缩小开源和专有商业模型在多模态理解能力上差距的开源多模态大型语言模型(MLLM)。是一个大规模的视觉-语言基础模型,专为增强机器的视觉与语言理解能力而设计。
- InternVL 1.5 利用持续学习策略对其视觉基础模型 InternViT-6B 进行优化,显著提升了其视觉内容理解能力。
- 该模型可以在不同的大型语言模型(LLM)之间进行迁移和重用,增强了视觉表征的通用性和灵活性。
InternVL 适用于需要高级视觉和语言理解的各种应用,如智能助手、自动内容生成、图像基础教育工具等。
在与如 GPT-4V 和其他商业模型的比较中,InternVL 1.5 显示出与这些先进模型竞争的潜力。尤其是在特定的基准测试中,例如 OCR 相关的基准,InternVL 1.5 甚至超越了部分商业模型。
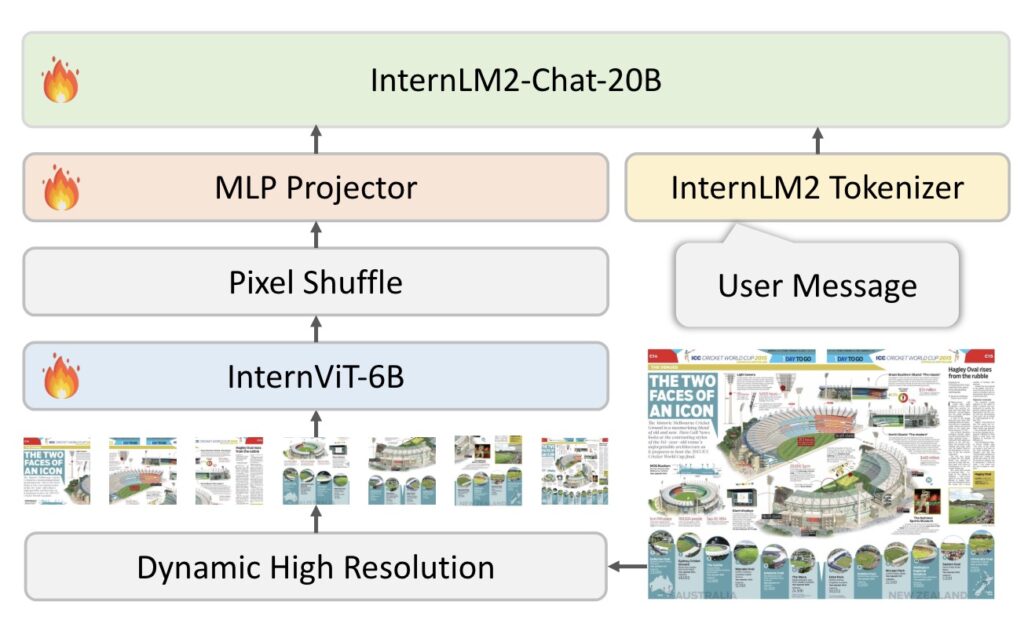
模型架构和核心组件
-
视觉编码器 InternViT-6B:
- InternViT-6B 是一种基于 Transformer 架构的视觉编码器,其参数规模扩展到了60亿,专为处理复杂的视觉输入而设计。
- 这种编码器优化了对图像的理解,可以处理高分辨率的输入,支持从简单的图像分类到复杂的图像内容理解。
-
语言中间件 QLLaMA:
- QLLaMA 作为语言处理的核心,参数规模为8亿,主要负责处理和生成语言内容,为多模态任务提供语言支持。
- 该中间件使用多语言增强的 LLaMA 来初始化,使其能够更好地与多种语言的输入数据对齐。
主要功能
-
多模态理解和交互:
- InternVL 不仅可以处理图像和文本数据,还能理解它们之间的复杂关系,如图像中的对象与相关描述的对应。
- 支持零样本学习任务,如零样本图像分类和视频分类,通过未标注的图像和文本对进行训练和预测。
-
视觉-语言任务的高效处理:
- 模型在多个视觉-语言基准测试上展示了卓越性能,如 VQA(Visual Question Answering)、图像字幕生成和图像-文本检索等。
- 特别在 OCR 和文档理解方面,模型能够有效识别和解释文档图像中的文字。
-
动态高分辨率 (Dynamic High-Resolution):
- 图像分割:模型根据输入图像的宽高比和分辨率,将图像分割成448×448像素的图块,这些图块的数量可以从1到40不等,支持高达4K的分辨率输入。这种动态分辨率策略允许模型根据需要调整分辨率,从而在计算效率和细节保留之间取得平衡。
- 全局上下文缩略图:为了捕捉全局上下文,除了图块之外,InternVL 1.5 还引入了缩略图视图。这有助于模型在处理具体的视觉信息时,还能够考虑到整体的场景构成。
-
强大的多模态对话系统构建能力:
- InternVL 能够与现有的大语言模型(如 GPT 系列)整合,共同创建功能丰富的多模态对话系统。
- 这使得模型不仅可以回答基于图像的问题,还可以在对话中引入视觉元素,增强交互的自然性和丰富性。
-
与语言模型的集成
- 语言基础模型:InternVL 1.5 使用 InternLM2-20B 作为其语言基础模型,这是一个具有20亿参数的大型语言模型。通过与强大的视觉编码器集成,InternVL 1.5 能够有效地处理和理解复杂的视觉-语言查询。
-
高质量双语数据集
- 数据集构建:为了提升模型在中文和英文的多模态任务中的表现,InternVL 1.5 使用了一个涵盖广泛场景的高质量双语数据集。这些数据集包含了大量的自然场景、文档图像,并且每个图像都附带了英文和中文的问答对。
- 双语能力:这种高质量的双语数据集不仅增强了模型在OCR任务中的表现,而且提升了其处理中文场景的能力,特别是在与中文文化相关的任务中。

-
开放性与社区支持:
- 作为一个开源项目,InternVL 鼓励社区开发者参与和贡献,从而不断改进模型的性能和适用性。
- 项目 提供了完整的代码、预训练模型和实现文档,方便研究人员和开发者使用和定制。
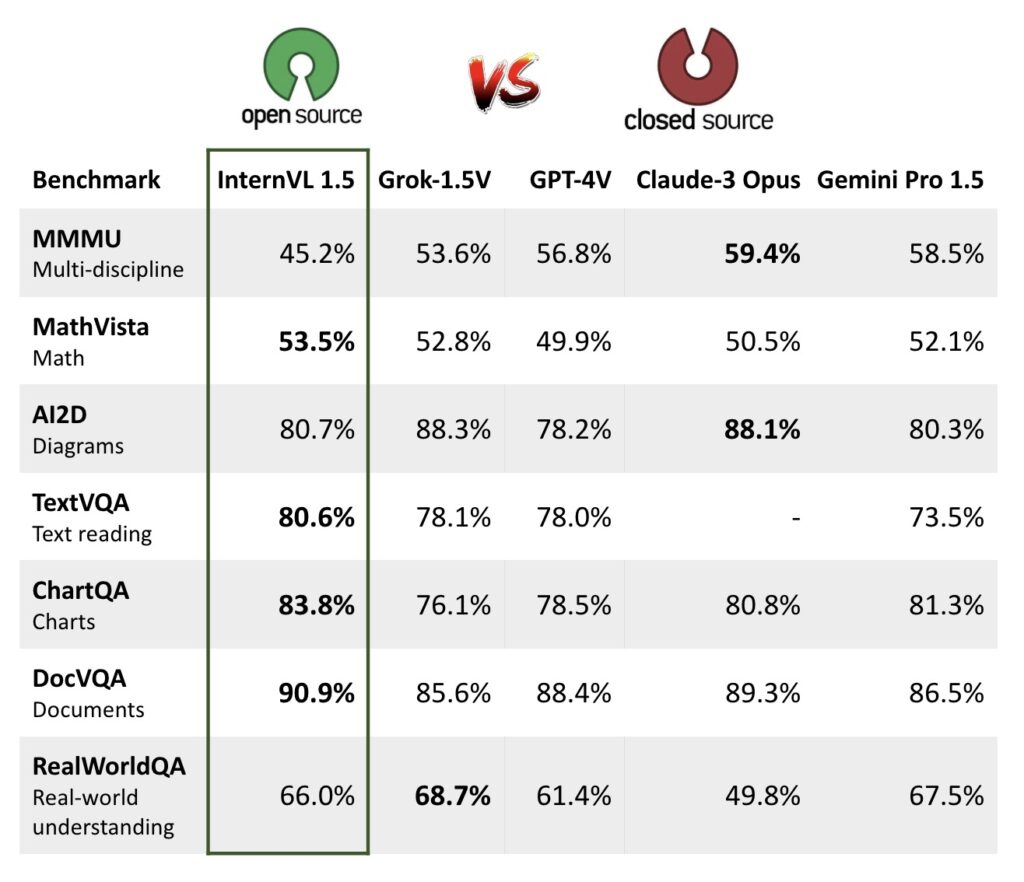
性能优异
- 优秀的基准测试表现:InternVL 1.5 在多个重要的基准测试上表现卓越,包括文档理解(DocVQA)、图表分析(ChartQA)、数学视觉问答(MathVista)等方面。在这些测试中,InternVL 1.5 不仅与现有的顶尖商业模型如 GPT-4V 和 Gemini Pro 竞争,甚至在某些情况下超越它们。
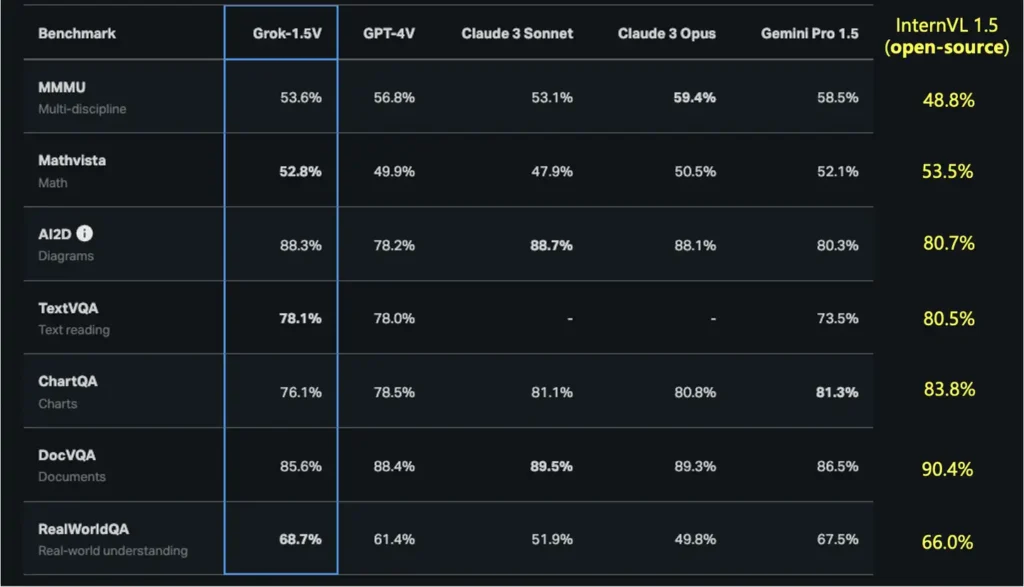
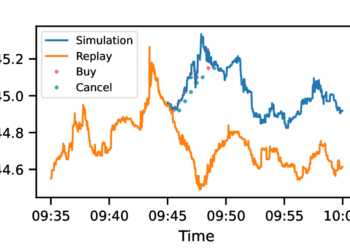
光学字符识别(OCR)相关基准测试
InternVL 1.5 在以下基准测试中显示了优异的性能:











{kind=link}