
Synthesia 公司推出能通过脚本就能预测表情的虚拟数字人形象:Expressive-1 AI Avatars,他们声称这是世界上首款表情丰富的AI虚拟形象。
这项技术可以将文本转换为生动的视频内容,包括面部表情、语音和肢体语言等元素。视频中的角色可以根据所表达的内容展现出不同的情绪和肢体动作,使视频更具吸引力和表现力。
🧠 可根据脚本自动预测表情
🗣️ 更自然的面部特征和头部动作
🫦匹配的声音和出色的口型同步
- 表现力丰富:这些虚拟数字人形象能根据文本的语义表达出相应的情感和情绪变化。
- 自然语音:提供非常自然的语音,可与虚拟形象搭配使用或单独使用。
- 即时虚拟形象预览:只需几秒钟预览AI虚拟形象
- 多语种支持:支持130多种语言的视频制作。
- 广泛的虚拟形象选择:平台提供160多种多样化的AI虚拟形象
形象能根据文本自动做出皱眉、微笑、皱眉头等表情
主要功能特点
-
增强的表现力:只需输入文本脚本内容,EXPRESS-1就能使用具体的语调、面部表情和身体语言来表演,这使得它们能够更自然地表达情绪和反应。
-
情绪反应的同步:根据脚本的情绪内容,EXPRESS-1可以展示与情感状态相匹配的表情和语调。例如,如果剧本是悲伤的,化身将显示悲伤的表情和语调;如果是兴奋的,化身将表现出活泼和充满活力的状态。
-
模仿人类的微表情和身体语言:通过分析和学习大量的人类交谈视频,EXPRESS-1能够精确地复制人类的微表情和细微的身体动作,提高了AI化身的真实感和互动质量。
- 匹配的声音和出色的口型同步:每个虚拟形象都配备了匹配的声音,同时实现了出色的口型同步技术,确保声音和嘴唇动作的一致性,提供更流畅的视听体验。
-
场景适应性:AI化身能够根据不同的交流场景和对话内容调整其表现方式,使得交互更加贴合实际情境。
Synthesia 公司介绍
Synthesia 是一个领先的AI视频生成平台,使用户能够从文本快速创建工作室级质量的视频。该平台支持130多种语言的AI虚拟形象和语音合成,操作简便,就像制作幻灯片一样。
主要功能:
-
AI虚拟形象和语音合成:
- 提供160多个AI虚拟形象和130多种语言的语音选项,帮助用户制作多样化和包容性强的视频内容。
- 支持自定义AI虚拟形象(数字双胞胎),使视频更具个性化和专业性。
-
文本到视频的转换:
- 用户可以输入或生成脚本,系统将自动将其转换为具有高质量语音的视频。
- 支持自动生成字幕,提高视频的可访问性。
-
高效的视频创建流程:
- 视频制作过程简单快速,类似于创建幻灯片,包括脚本编写、视频定制、合作和共享。
- 提供200多个免费视频模板,加速视频制作流程。
-
成本和时间效率:
- 相比传统视频制作方法,大幅降低了成本和时间消耗。例如,Xerox的全球培训团队将视频和语音合成成本降低了超过50%。
- 提升用户参与度和教育效果,比如BSH的e-learning参与度提高了30%以上。
-
易于维护和更新:
- 提供简便的视频更新和反馈工具,无需重新拍摄即可更新视频内容。
- 支持将视频嵌入到用户喜爱的工具中,如作者工具、学习管理系统(LMS)等。
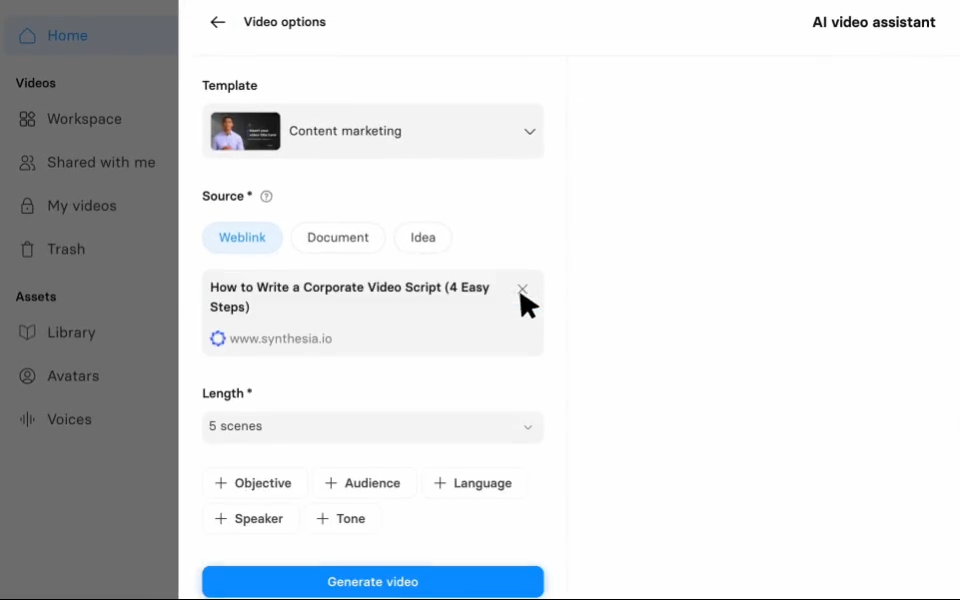
像制作幻灯片一样轻松制作视频













{kind=link}