
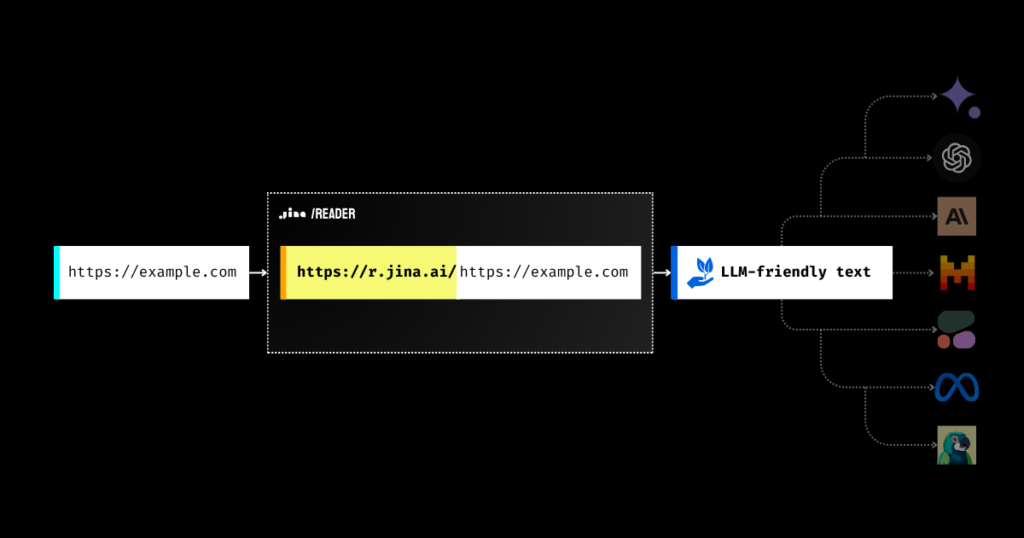
jina-ai/reader 将任何网页URL转换为大语言模型(LLM)友好的输入格式。它通过一个简单的前缀 https://r.jina.ai/ 实现这一转换,从而使LLM能更高效地处理和理解网络内容。这对于提升使用语言模型的自动化系统(如聊天机器人、内容摘要生成器等)的输入质量和输出效果非常有帮助。

主要功能:
- 从URL提取内容:Reader API通过提取URL的核心内容并将其转换为干净的、适合LLM使用的文本,解决了网页抓取的复杂性和HTML格式的杂乱问题。

- 网页搜索支持:通过在查询前添加
https://s.jina.ai/,Reader API会搜索网页并返回前五个结果的URL和内容,每个结果都以适合LLM的格式呈现。
- 图片解析:Reader API能够自动为网页中的图片生成描述,并将其作为图像alt标签添加到输出中,帮助下游LLM进行推理和总结。

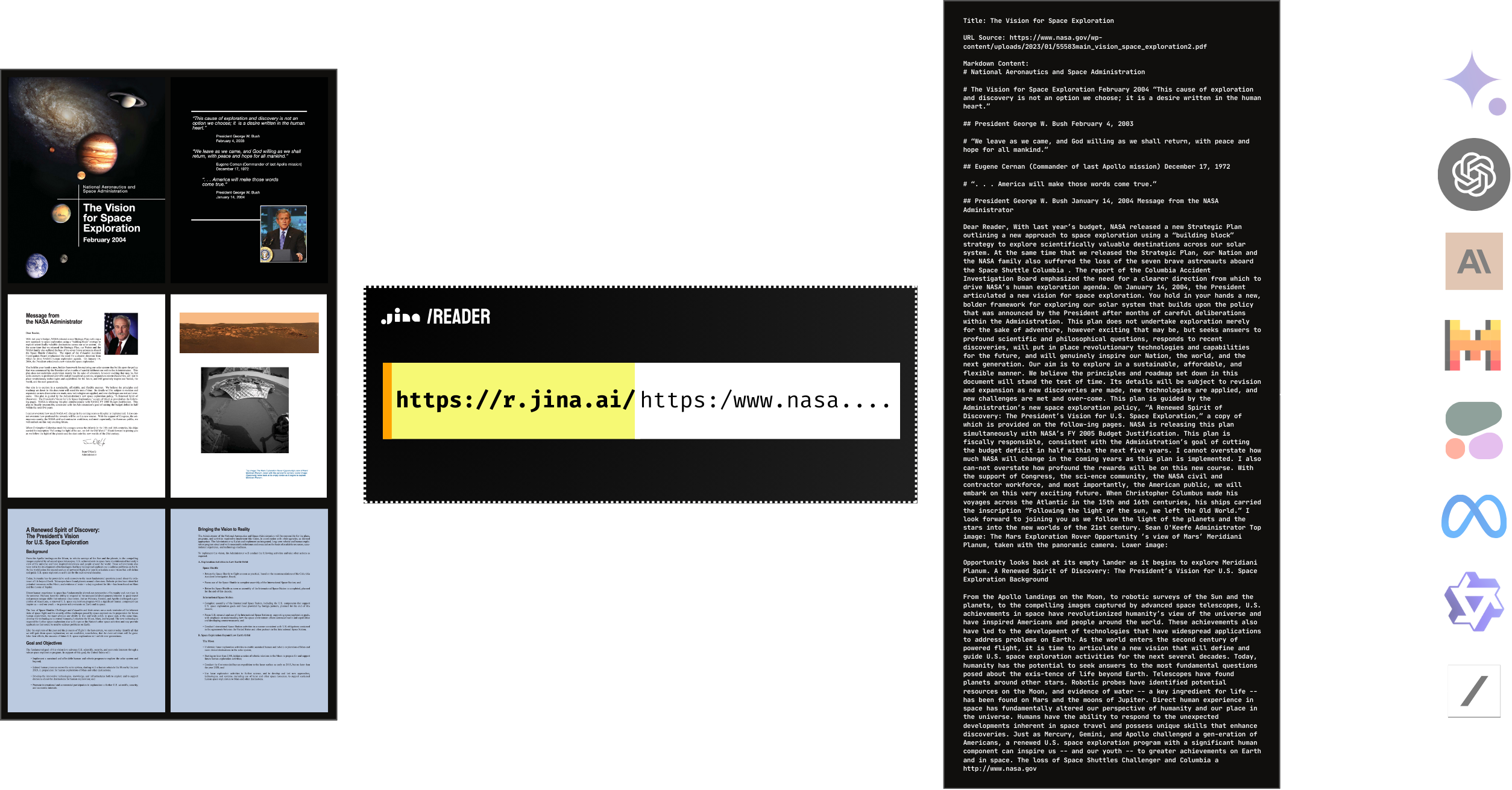
- PDF支持:Reader API原生支持PDF读取,兼容大多数PDF文件,包括含有大量图片的文件,解析速度非常快。
- 高可用性:该API基于可扩展的基础设施构建,提供高访问性、并发性和可靠性,适用于生产环境。


使用示例:
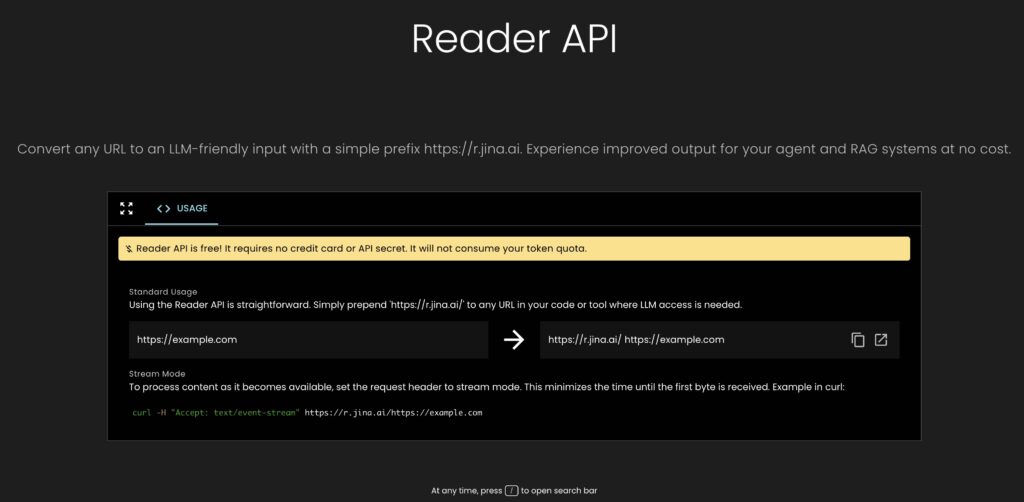
- 读取URL:将
https://r.jina.ai/添加到任何URL前缀中,即可返回该页面的主要内容,适合LLM使用。 - 搜索查询:将
https://s.jina.ai/添加到查询前,即可调用搜索引擎并返回前五个结果的内容。
定价和限制:
- 免费提供API,每个新的API密钥包含一百万免费令牌。
- 无API密钥的请求速率限制为20 RPM,使用API密钥后速率限制为200 RPM。
高级功能:
- 提供JSON响应格式,包含URL、标题、内容和时间戳(如果有)。
- 支持通过代理服务器访问URL和跳过缓存。
- 能够设置请求头以控制API行为。
主要用途:
- 提高输入质量: 通过格式化和清理URL内容,确保LLM接收到的输入更加规范和易于处理。
- 流式处理支持: 允许系统以流式方式处理大量或实时数据,适合需要快速响应的应用场景。
- 适应多种场景: 支持多种模式(如标准模式、流式模式和JSON模式),以适应不同的技术需求和应用场景。
- 改善自动化系统性能: 对于使用代理和检索生成系统的用户来说,可以得到更改善的输出结果。
- 简单易操作: 不需要 API 密钥。只需在 URL 前添加 “https://r.jina.ai/”即可,用户无需复杂配置即可使用。
- 特定输出格式: 支持特定的输出格式,如文本流或JSON,专为与LLM集成设计。
- 延迟时间短:API 一般在 2 秒内处理 URL 并返回内容,但复杂或动态页面可能需要更多时间。
一些缺点:
- 阅读器 API 以 URL 的原始语言返回内容。暂时不提供翻译服务。
- 虽然主要是为网页设计的,但它可以从 arXiv 等网站上以 HTML 格式浏览的 PDF 中提取内容,但它并没有针对一般的 PDF 提取进行优化。
- 目前,应用程序接口不处理媒体内容,但未来的增强功能将包括图像字幕和视频摘要。
- 目前只能处理来自可公开访问的 URL 的内容,不能处理来自本地的地址
这个工具非常适合开发者和研究人员,他们可以使用它来提升基于LLM的应用程序的效率和输出质量。
- 在线演示,可通过访问这里进行体验。
- 示例:使用curl命令以流式模式访问Wikipedia首页,获取即时的分块内容输出。