
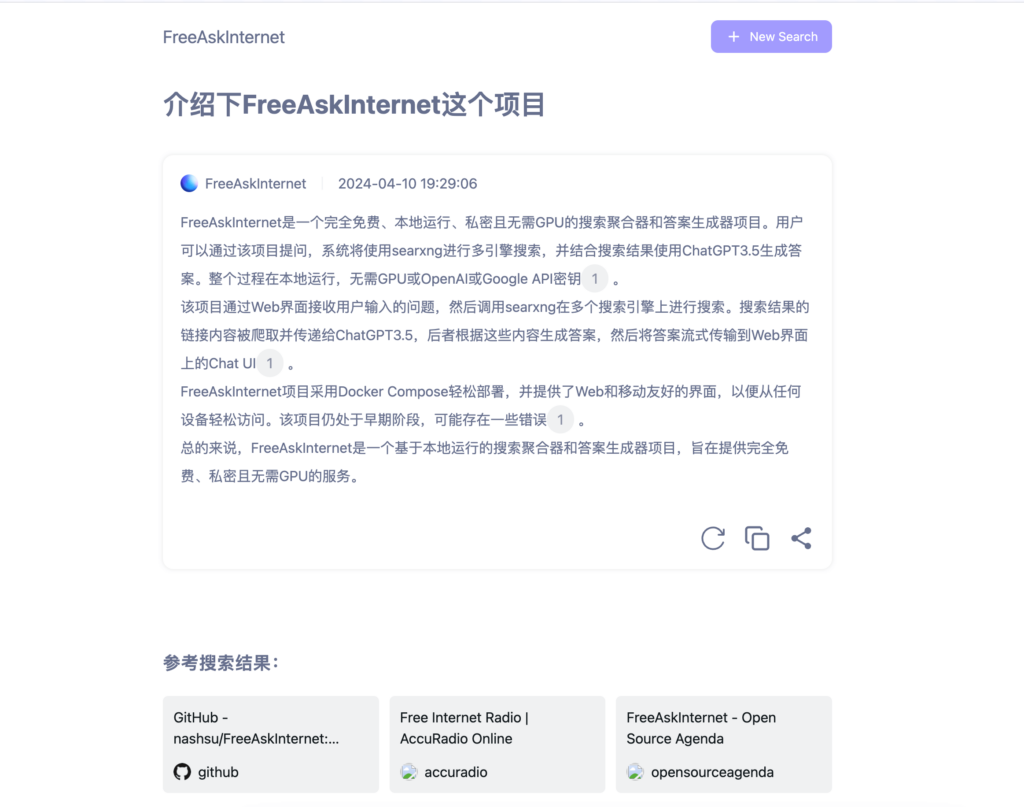
FreeAskInternet 是一个开源项目,提供了一个完全免费、私密且本地运行的类似perplexity.ai 的搜索聚合器和答案生成器。用户可以提出问题,系统将使用多引擎搜索,并结合搜索结果和LLM(如ChatGPT3.5)生成答案。整个过程都在本地运行,无需GPU、OpenAI或Google的API密钥。
主要特性和功能:
- 完全免费使用:不需要任何API密钥,用户可以免费使用所有功能。
- 本地运行:所有的搜索和处理活动都在用户的本地计算机上进行,不需要将查询发送到互联网上的服务器。
- 保障隐私:由于所有操作都在本地完成,用户的查询和数据不会被上传到互联网,从而保护了用户的隐私。
- 不需要GPU:尽管使用了多个大型语言模型,但FreeAskInternet设计得足够轻量,无需高性能GPU即可运行。
- 支持多个LLM:项目不仅集成ChatGPT3.5、Kimi、Qwen、智谱GL等模型,还支持定制的LLM,如ollama,提供更广泛的应用场景。
- 易于部署:通过Docker Compose可以快速部署和启动,简化了安装和使用过程。
- Web和移动友好界面:设计了适合于Web搜索增强的AI聊天界面,支持从任何设备访问。
工作原理:
FreeAskInternet 利用searxng进行多搜索引擎查询,抓取搜索结果后,将这些内容传递给LLM(例如ChatGPT3.5或其他定制模型),根据搜索内容生成回答。这一切过程都在用户的本地环境中完成,无需外部API支持,也不需要高端硬件。
主要包括以下几个步骤:
- 用户输入查询:用户通过FreeAskInternet的界面输入查询问题。这个界面运行在用户的本地计算机上,确保了查询的私密性。
- 本地搜索引擎聚合:系统使用 searxng,一个开源的隐私保护搜索引擎聚合工具,来在多个搜索引擎上进行查询。searxng 在本地运行,它汇总多个搜索引擎的结果,但不会暴露用户的个人信息给这些外部搜索引擎。
- 抓取搜索结果内容:从搜索引擎聚合得到的结果中,FreeAskInternet 抓取相关的网页内容或信息。这个过程同样在本地完成,无需将数据发送到外部服务器。
- LLM处理查询:系统将抓取到的内容传递给本地运行的大型语言模型(LLM),如ChatGPT3.5或自定义的模型如ollama。这些LLM被用来根据提供的参考内容生成针对用户查询的回答。由于LLM也在本地运行,整个处理过程不依赖互联网服务,保证了查询的私密性。










{kind=link}