

该项目由字节跳动开发,DiffusionGPT的牛P之处在于它集成了多种领域的专家图像生成模型。
然后使用LLM来对接这些图像生成模型,让LLM来处理和理解各种文本提示。
最后根据理解的信息选择最合适的图像模型来生成图像。
这样就和GPT 4一样,通过聊天画图…
DiffusionGPT主要特点:
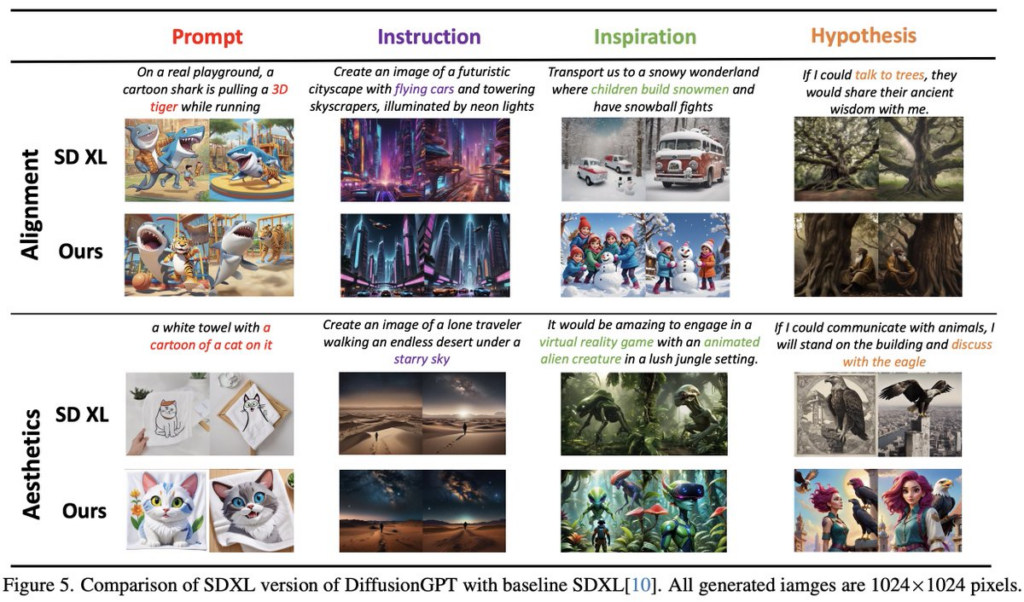
1、多样化文本提示处理:DiffusionGPT 能够理解和处理各种类型的文本提示,包括具体的指令、抽象的灵感、复杂的假设等。
2、集成多个领域专家模型:系统集成了多种领域的图像扩散模型,每个模型在其特定领域具有专业的图像生成能力。这类模型专注于特定领域的图像生成,比如自然景观、人物肖像、艺术作品等。
这意味着系统不仅能够生成普通的图像,还能够处理更特定、更复杂的图像生成任务,比如特定风格或类型的图像。模仿特定艺术家的风格、漫画风格或摄影技术。
3、大语言模型驱动:DiffusionGPT 使用大语言模型(LLM)来解析和理解用户输入的文本提示。这个过程类似于其他基于 LLM 的系统(如 GPT-4)处理文本的方式,但特别应用于理解用于图像生成的指令和描述。
4、智能选择合适的图像模型:基于对文本提示的理解,DiffusionGPT 能够智能地选择最合适的图像生成模型来生成图像。这不仅包括选择正确的模型,还涉及调整生成参数以最好地满足用户的需求。
5、输出高质量图像:通过精准地匹配文本提示与最佳生成模型,DiffusionGPT 能生成高质量、与用户需求高度吻合的图像。
6、用户反馈与优势数据库:结合用户反馈和优势数据库,系统能够根据用户偏好调整模型选择,提升图像生成的相关性和质量。
例如:在系统的早期使用中,用户可能提供对生成图像的反馈,比如“这张图片的颜色太暗了”。DiffusionGPT 利用这些反馈来调整其模型选择,使得未来的图像生成更符合用户的偏好。


主要工作原理:
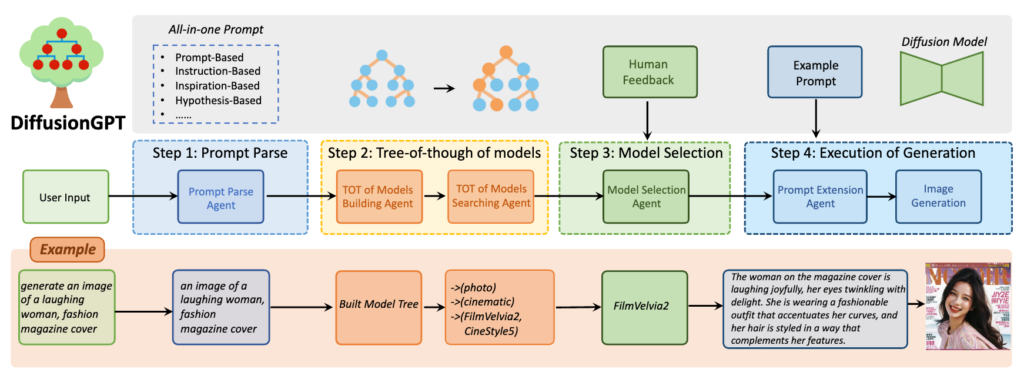

1、输入解析:用户提供文本提示,如描述、指令或灵感。
大型语言模型(LLM)负责解析这些文本提示,理解其含义和需求。
2、思维树(Tree-of-Thought)构建:根据不同的图像生成任务,系统构建了一个“思维树”,这是一种组织不同图像生成模型的结构。
思维树基于先验知识和人类反馈,涵盖了多种领域的专家级模型。
3、模型选择:根据 LLM 解析的结果,系统通过思维树来确定最适合当前文本提示的图像生成模型。在选择过程中,可能还会考虑用户的偏好和历史反馈,这些信息存储在优势数据库中。
4、图像生成:一旦选定了合适的模型,该模型就会被用来生成图像。生成的图像将与输入的文本提示紧密相关,并反映出用户的意图和偏好。
5、结果输出:最终生成的图像会呈现给用户。
这些图像可以是多样化的,包括但不限于具体描述的场景、概念艺术作品或符合特定风格的图像。
6、用户反馈优化过程:
用户对生成图像的反馈被用来丰富优势数据库,进而帮助系统更好地理解用户偏好,优化后续的模型选择和图像生成。

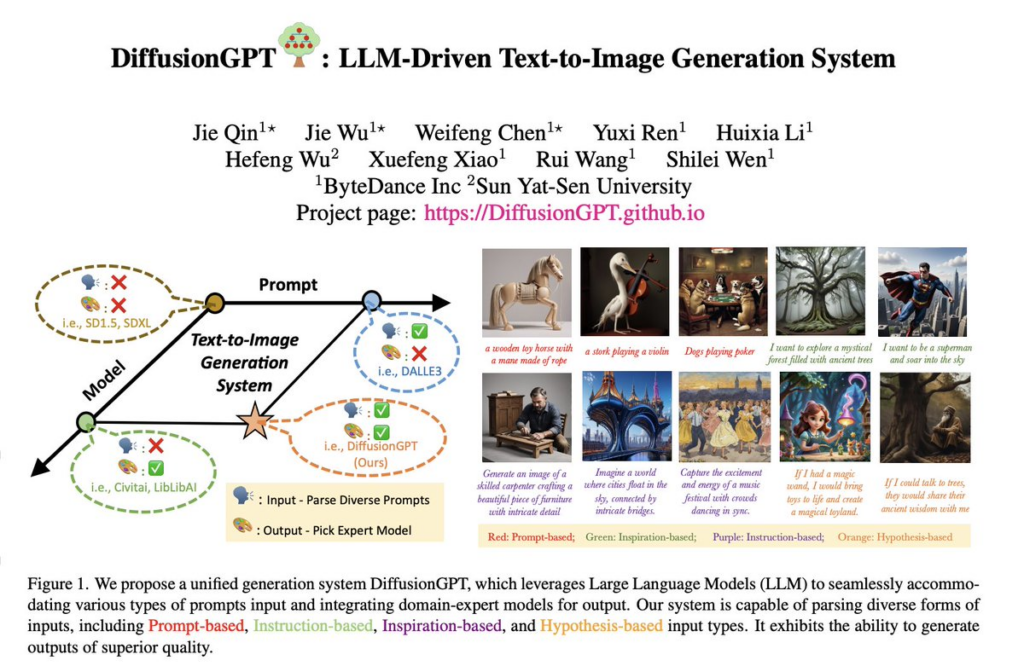
实验结果:
DiffusionGPT 在生成人类和场景等类别的图像时展现了高度的真实性和细节。
与基准模型(如 SD1.5)相比,DiffusionGPT 生成的图像在视觉保真度、捕捉细节方面有明显提升。
DiffusionGPT 在图像奖励和美学评分方面的表现优于传统的稳定扩散模型。
在进行图像生成质量的量化评估时,DiffusionGPT 展示了较高的评分,说明其生成的图像在质量和美学上更受青睐。

在线演示:
DiffusionGPT-XL:https://huggingface.co/spaces/DiffusionGPT/DiffusionGPT-XL