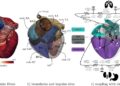
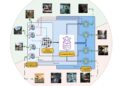
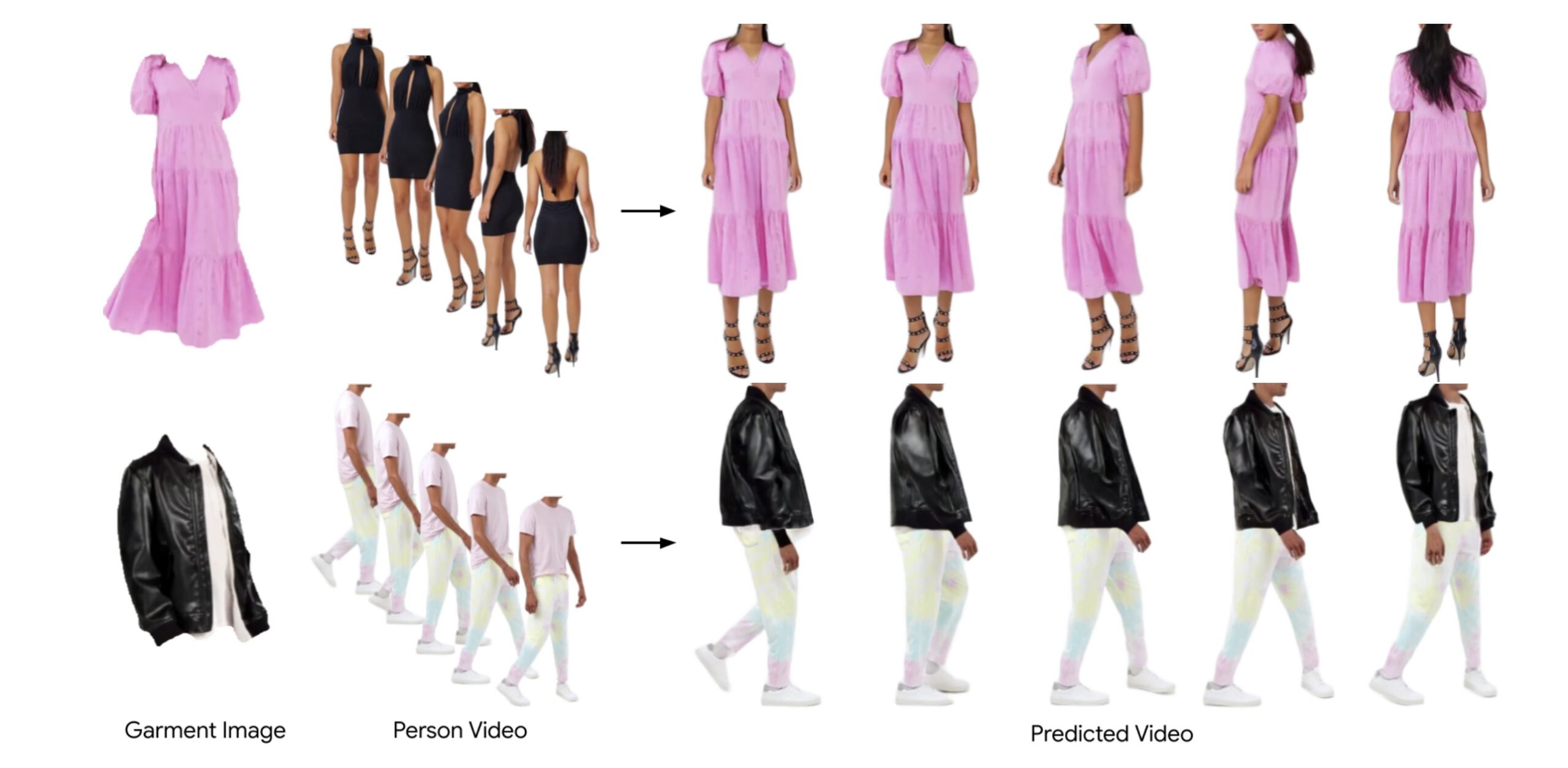
<strong>Fashion-VDM</strong> 是一个基于扩散模型(Video Diffusion Model,VDM)的虚拟试衣视频生成模型。可以通过 AI 技术生成高质量的虚拟试衣视频,使用户能够看到一个人在穿上特定服装后的动态效果。 它能够结合给定的<strong>衣物图像</strong>和<strong>人物视频</strong>,生成一段<strong>虚拟试穿视频</strong>,展示人物穿上该衣物后的样子,同时保留人物的<strong>身份特征</strong>和<strong>动作流畅性</strong>。 <h5><strong>视频虚拟试穿的优势</strong></h5> <ul> <li><strong>衣物细节:</strong> 与传统的图像虚拟试穿相比,视频虚拟试穿能够更加生动地展示衣物如何与人物的运动互动。例如,衣物的动态形态变化(如随人物动作而产生的褶皱、摆动等)被准确捕捉。</li> <li><strong>人物自然性:</strong> 通过保持人物的原始身份和动作,Fashion-VDM确保了虚拟试穿视频在视觉上的自然性和真实性,避免了人物与衣物之间的不协调感。</li> </ul> [video width="1570" height="720" mp4="https://img.xiaohu.ai/2024/11/11月13日-12.mp4"][/video] <h3><strong>主要功能:</strong></h3> <ol> <li><strong>虚拟试穿视频生成:</strong> <ul> <li><strong>输入:</strong> 给定一张衣物图像和一段人物视频。</li> <li><strong>输出:</strong> 生成一段新的视频,展示该人物穿上输入衣物后的视频效果,且该人物的动作、表情和身体姿势保持一致。</li> </ul> </li> <li><strong>高质量细节呈现:</strong> <ul> <li><strong>衣物细节:</strong> Fashion-VDM能够生成具有高细节度的衣物表现,避免了传统视频虚拟试穿方法中衣物细节模糊或失真的问题。</li> </ul> </li> <li><strong>时间一致性:</strong> <ul> <li><strong>动作流畅性:</strong> 该方法有效解决了现有方法在时间一致性上的问题,生成的视频能够流畅地展示人物的动态,而不出现跳跃或不自然的变化。</li> </ul> </li> </ol> [video width="1492" height="720" mp4="https://img.xiaohu.ai/2024/11/11月13日-2.mp4"][/video] <h5><strong>解决了什么问题?</strong></h5> 在传统的虚拟试衣技术中,虽然图像基础的虚拟试衣(例如 2D 图像上的服装叠加)已经取得了不错的效果,但仍存在一些明显的局限性。<strong>Fashion-VDM</strong> 解决了以下主要问题: <ol> <li><strong>服装细节不足:</strong> <ul> <li>传统的视频虚拟试衣方法通常会忽略服装的细节,特别是在动态场景中。当人物进行运动时,服装的展示可能不够真实或缺乏精细的纹理和细节。</li> <li><strong>Fashion-VDM</strong> 采用扩散模型,通过对视频进行去噪处理,使得服装的细节更加丰富和真实,特别是在动态展示时,生成的试衣视频能够呈现服装的材质、褶皱、动感等细节,提升试衣效果的真实感。</li> </ul> </li> <li><strong>时序一致性问题:</strong> <ul> <li>在视频虚拟试衣中,确保服装在视频中的呈现与人物运动的同步非常重要。许多现有方法难以处理视频中服装与人物运动的时间一致性,可能会出现人物运动流畅但服装展示不自然的情况。</li> <li><strong>Fashion-VDM</strong> 通过引入<strong>时序注意力模块</strong>和<strong>3D卷积结构</strong>,确保生成的视频中服装与人物的运动在时间上保持一致,从而避免了服装和人物运动不同步或画面抖动的问题。</li> </ul> </li> <li><strong>人物形态不准确:</strong> <ul> <li>现有的虚拟试衣方法往往只根据人物的关节或姿态点来生成试穿效果,缺乏对人物身体形态的精细建模,可能导致试衣效果中的人物形态不准确或失真。</li> <li><strong>Fashion-VDM</strong> 使用了基于关节点的姿势编码,虽然这能够保持人物的动态一致性,但仍然存在身体形态误差,特别是在遮挡区域。尽管如此,这一模型仍相较于传统方法,在动态试穿的精度上有了显著提升。</li> </ul> </li> <li><strong>服装遮挡区域的错误:</strong> <ul> <li>在生成虚拟试衣视频时,服装与人物的边界是一个难点,尤其是对于遮挡区域,现有方法容易出现伪影或误差。</li> <li><strong>Fashion-VDM</strong> 通过<strong>分割式分类器无指导(split-CFG)</strong>,改善了对服装和人物之间边界的控制,减少了由于图像缺失或不完整视角导致的伪影和错误。</li> </ul> </li> </ol> <h5><strong><img class="aligncenter size-full wp-image-15454" src="https://img.xiaohu.ai/2024/11/Jietu20241113-114021@2x-scaled.jpg" alt="" width="2560" height="1254" /></strong></h5> <h3>技术方法</h3> <strong>Fashion-VDM</strong> 的技术方法主要围绕 <strong>视频扩散模型(VDM)</strong>,并采用了若干创新策略来提升虚拟试穿视频生成的质量和一致性。 <strong>通过以下几个方面进行了创新:</strong> <ul> <li><strong>扩散模型</strong>:用于生成高质量的虚拟试穿视频。</li> <li><strong>无分类器引导</strong>:提升了控制输入条件的能力。</li> <li><strong>渐进式时间训练</strong>:确保生成视频的时间一致性。</li> <li><strong>联合图像-视频训练</strong>:使生成的视频既能保留静态图像的细节,也能表现动态视频中的人物动作。</li> <li><strong>细节和一致性</strong>:通过高质量的衣物细节和流畅的动作捕捉,Fashion-VDM克服了传统虚拟试穿方法中的主要不足,提供了更真实、更自然的虚拟试穿体验。</li> </ul> <h5><a href="https://img.xiaohu.ai/2024/11/architecture.svg"><img class="aligncenter size-full wp-image-15451" src="https://img.xiaohu.ai/2024/11/architecture.svg" alt="" width="1536" height="720" /></a>1. <strong>扩散模型架构(Diffusion-based Architecture)</strong></h5> <ul> <li><strong>扩散模型</strong>:Fashion-VDM使用了扩散模型(Diffusion Models),一种当前在图像生成和视频生成中非常流行的深度学习方法。扩散模型通过逐步噪声化数据并反向去噪来生成高质量的数据。具体而言,Fashion-VDM通过一个扩散过程生成虚拟试穿的视频帧,这样的生成过程有助于避免传统方法中容易出现的细节损失和模糊问题。</li> <li><strong>视频生成:</strong> Fashion-VDM的目标是生成多个视频帧(例如64帧的视频)。通过逐帧生成视频,模型能够精确控制每一帧的细节,使得人物穿上衣物的效果自然且细腻。</li> </ul> <h5>2. <strong>无分类器引导(Classifier-Free Guidance)</strong></h5> <ul> <li><strong>无分类器引导技术</strong>:为了更精确地控制虚拟试穿的输出,Fashion-VDM采用了<strong>无分类器引导</strong>(classifier-free guidance)。这种方法不依赖于传统的分类器,而是通过强化模型的条件控制,从而优化生成结果。</li> <li><strong>多条件控制</strong>:例如,模型可以根据不同的输入条件(如单纯的服装、人物+服装或人物+服装+姿势)来控制生成效果的精细度。</li> <li>通过这种引导方法,模型能够更好地结合输入的<strong>衣物图像</strong>和<strong>人物视频</strong>,确保生成的视频保持一致的风格和细节,同时提高了对衣物样式、颜色以及纹理的表现能力。</li> </ul> <h5><img class="aligncenter size-full wp-image-15452" src="https://img.xiaohu.ai/2024/11/temporal_progressive_training.svg" alt="" width="943" height="204" />3. <strong>渐进式时间训练(Progressive Temporal Training)</strong></h5> <ul> <li><strong>训练策略:</strong> 为了解决时间一致性问题,Fashion-VDM采用了<strong>渐进式时间训练策略</strong>。最开始,模型只训练空间层,通过图像数据进行预训练。然后,随着训练的深入,模型逐渐开始训练时序层,并增加视频帧的数量。这一策略逐步训练模型生成更多的视频帧,并在训练过程中逐渐增加时间维度的细节,以便生成具有连贯性的动态视频。</li> <li><strong>单次生成64帧</strong>:通过逐渐增加每次生成的视频帧数量,模型可以在不同阶段优化视频生成质量,最终能够生成高达 64 帧的视频。该策略使得Fashion-VDM能够在一次生成过程中同时生成64帧、每帧分辨率为512像素的视频,从而保证生成的视频具有较高的质量和自然感。</li> </ul> <h5>4. <strong>联合图像-视频训练(Joint Image-Video Training)</strong></h5> <ul> <li><strong>图像与视频的联合训练</strong>:Fashion-VDM采用了联合图像和视频训练方法。这种训练方式通过同时利用图像和视频数据进行训练,使得生成模型能够同时捕捉到静态图像的细节和视频中的动态变化,从而增强了虚拟试穿生成的效果。</li> <li>这种方法的优势在于,它不仅能生成清晰的衣物细节,还能够保持人物的动作连贯性。</li> </ul> <h5><img class="aligncenter size-full wp-image-15453" src="https://img.xiaohu.ai/2024/11/split_cfg_ablation.svg" alt="" width="989" height="387" />5. <strong>高质量衣物细节与动态一致性</strong></h5> <ul> <li><strong>时序注意力和3D卷积</strong>:为了确保服装和人物的运动在时间维度上保持一致,Fashion-VDM 引入了时序注意力机制和 3D 卷积模块。这使得生成的视频不仅清晰,而且在时间流畅上没有抖动或不连贯的部分。</li> <li><strong>保持运动同步</strong>:人物的动态运动与服装展示之间能够无缝衔接,避免了传统方法中的时间不一致性问题。</li> <li><strong>衣物细节</strong>:Fashion-VDM在生成衣物的细节方面表现出了很高的质量,能够呈现衣物的材质、纹理和颜色等复杂特征。这使得虚拟试穿效果更加真实和细腻。</li> <li><strong>动态一致性</strong>:通过精细的扩散模型和渐进式时间训练,Fashion-VDM能够保持视频中的人物动作一致性,避免了传统方法中的时间跳跃和不自然的动作。</li> </ul> <h5><strong>6.服装与人物的姿势编码(Garment and Pose Encoding)</strong></h5> <ul> <li><strong>分离编码</strong>:Fashion-VDM 对服装和人物分别进行编码。服装图像被转化为<strong>服装分割图</strong>和<strong>服装姿势编码</strong>,而人物视频则通过<strong>人物姿势编码</strong>来表示人物的动态。这种分离的编码方式帮助模型在试衣过程中精确地将服装与人物的动态融合。</li> <li><strong>交叉注意力机制</strong>:在生成视频时,服装和人物的编码通过交叉注意力机制进行融合,确保服装和人物之间的互动自然且一致。</li> </ul> <h3>实验结果总结:</h3> <h5>1. <strong>定量评估</strong></h5> <ul> <li><strong>FID(Frechet Inception Distance)</strong>:Fashion-VDM的生成视频显著降低了FID值,表明其生成的视频与真实视频之间的相似度更高,生成的衣物和人物更加自然,细节表现更加真实。</li> <li><strong>PSNR(Peak Signal-to-Noise Ratio)</strong>:Fashion-VDM在PSNR上取得了较高分数,说明其生成的视频具有更高的图像质量,尤其在细节和清晰度方面,优于其他基准方法。</li> <li><strong>SSIM(Structural Similarity Index)</strong>:Fashion-VDM的SSIM值远高于其他方法,表明生成的视频在结构和纹理保持上比其他方法更加精细,能够更好地保留图像的结构一致性。</li> </ul> <h5>2. <strong>定性评估</strong></h5> <ul> <li><strong>衣物细节呈现</strong>:Fashion-VDM能清晰地展示衣物的复杂细节,如纹理、光泽、褶皱等,生成的视频表现出更真实的衣物外观,相较于其他视频虚拟试穿方法,衣物的细节更加丰富且自然。</li> <li><strong>人物动作一致性</strong>:Fashion-VDM生成的视频能够很好地保留人物的动作自然性和一致性。生成的视频在人物动作的流畅性和时间一致性方面表现优秀,避免了其他方法中常见的动作不连贯或突兀的现象。</li> <li><strong>视频流畅性</strong>:与现有的虚拟试穿方法相比,Fashion-VDM生成的视频在时间维度上表现出更好的一致性。视频中的人物动作流畅且没有跳帧或断层,确保了整体的连贯性。</li> </ul> <h5>3. <strong>与现有方法的对比</strong></h5> <ul> <li><strong>与传统图像虚拟试穿方法的对比</strong>:传统的图像虚拟试穿方法只能生成静态的图像,无法处理动态视频中的细节和人物的动作。因此,Fashion-VDM在动态效果和时间一致性方面占据了明显优势。</li> <li><strong>与视频虚拟试穿基准方法的对比</strong>:与其他视频虚拟试穿方法相比,Fashion-VDM在衣物的细节展示、视频流畅性和时间一致性上均表现得更为优秀。现有的VVT方法往往在细节呈现或动作自然性方面有所不足,而Fashion-VDM则能够在这些方面提供更真实的效果。</li> </ul> <h5>4. <strong>用户研究</strong></h5> <ul> <li>进行的用户研究表明,Fashion-VDM在生成的虚拟试穿视频中,用户对<strong>视频的真实性</strong>、<strong>衣物的呈现效果</strong>、<strong>人物的动作自然性</strong>等方面给予了高度评价。大多数用户认为生成的视频在视觉效果上非常接近真实视频,且人物的动作流畅且自然,衣物的表现也很精致。</li> <li><strong>用户反馈</strong>:用户普遍认为,Fashion-VDM生成的视频具有更高的现实感,尤其在服装的动态效果和人物动作的自然度方面,都比现有的虚拟试穿方法要优秀。</li> </ul> 项目地址:<a href="https://johannakarras.github.io/Fashion-VDM/" target="_blank" rel="noopener">https://johannakarras.github.io/Fashion-VDM/</a> 论文:<a href="https://arxiv.org/pdf/2411.00225" target="_blank" rel="noopener">https://arxiv.org/pdf/2411.00225</a>






{kind=link}