

Genmo 推出最新开源视频生成模型 Mochi 1。
- Mochi 1 采用了Asymmetric Diffusion Transformer(AsymmDiT)架构,是迄今为止最大的开源视频生成模型,具备100亿参数。
- 该模型可同时处理文本和视频信号,拥有更强的视觉推理能力,同时优化了内存需求。
功能特点:
1. 高保真动作生成
- 动作流畅、自然:生成的视频帧率达到30帧/秒,持续时间最长可达5.4秒,具备高时间一致性,确保动作连贯且自然。
.
- 逼真的物理效果:模型在生成流体动态、毛发模拟和人类行为时,遵循物理法则,生成结果更加自然逼真。
.
- 突破“恐怖谷”问题:人类角色的动作和表情流畅连贯,细节丰富,显著提升了视频的真实感和自然度。
2. 强大的文本提示响应
- 精确的提示对齐:Mochi 1 能根据用户的文本指令,生成与描述高度一致的场景、角色和动作。
- 多模态融合:模型在处理视觉和文本提示时使用多模态自注意力机制,实现文本和视频的协同处理,使得生成结果符合用户预期。
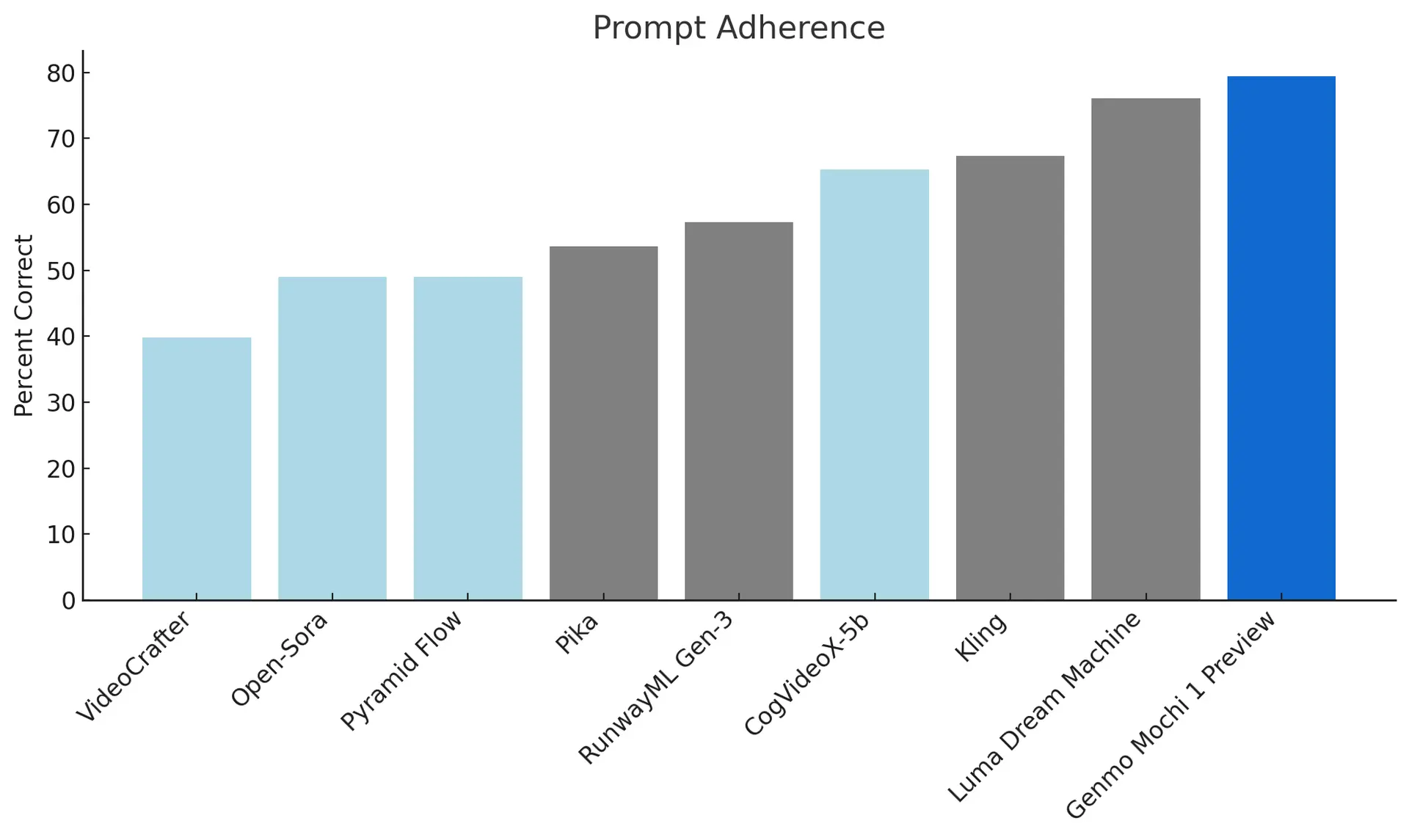
衡量生成的视频遵循所提供的文本指令的准确程度,确保高度保真用户意图 This is premium stuff. Subscribe to read the entire article.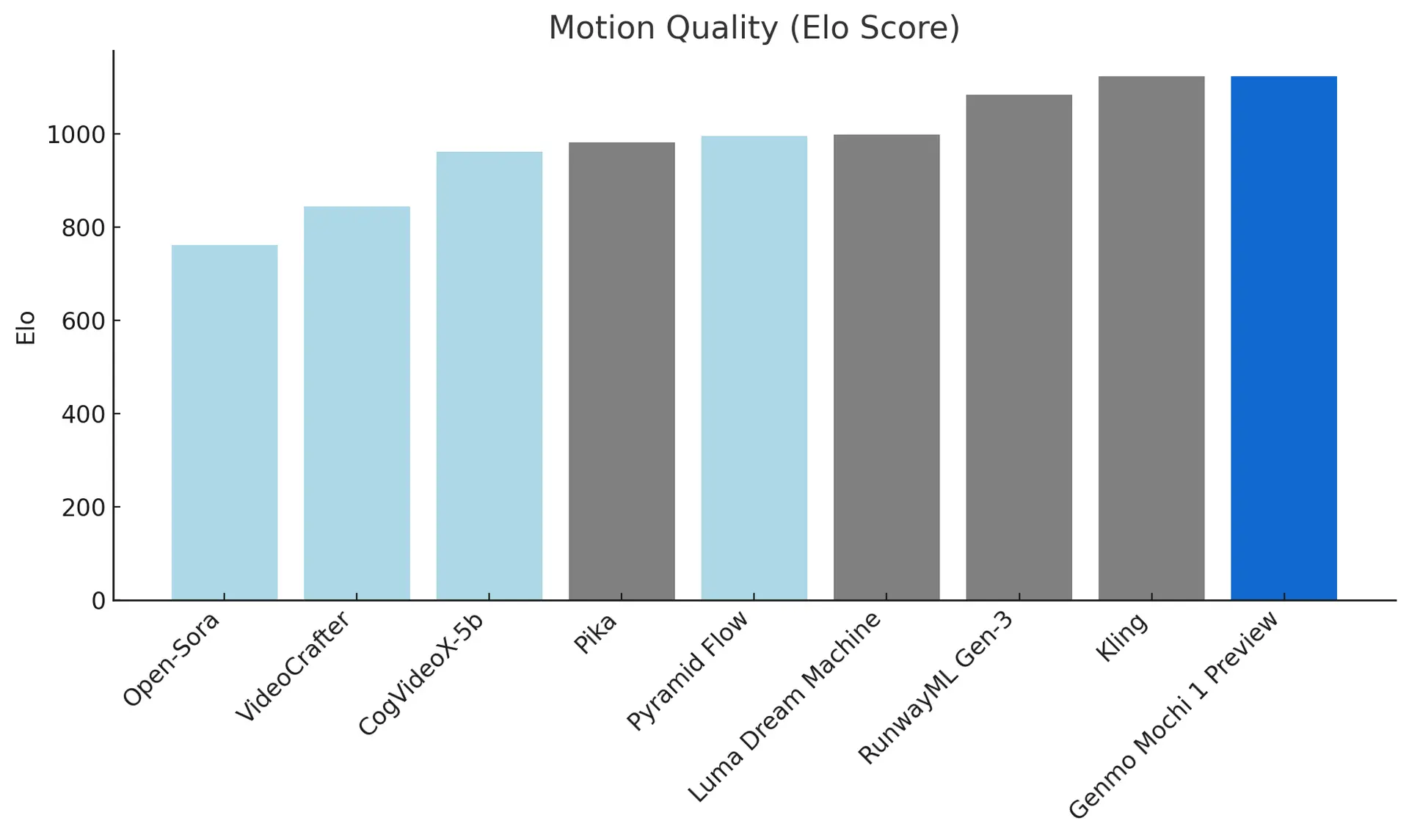
Support authors and subscribe to content
Login if you have purchased













{kind=link}