TxT360 是由 LLM360 创建的一个 Hugging Face 上用于大语言模型训练的数据集。该数据集包含了来自多个领域的高质量文本数据,总计超过15万亿个tokens,去重后的约5.7万亿个高质量的tokens。
该数据集通过全球去重技术解决了跨数据集的重复问题,同时保留了高质量的精选数据源。TxT360在规模和性能上超越了FineWeb和RedPajama等现有数据集,允许预训练者更好地控制数据分布和上采样技术,从而优化模型训练。
- 99个Common Crawl快照:数据集包含了99个从互联网上抓取的网页数据集
- 14个精选数据源:除了网络抓取的数据外,该数据集还包括14个高质量的精选数据源,例如法律文档、百科全书等,
- 数据权重调整配方:这个数据集还提供了一种方法(配方),允许用户根据不同的数据来源或需求调整数据的权重。这意味着用户可以灵活地决定哪些数据在模型训练中应该占更大的比例,以优化模型的性能。
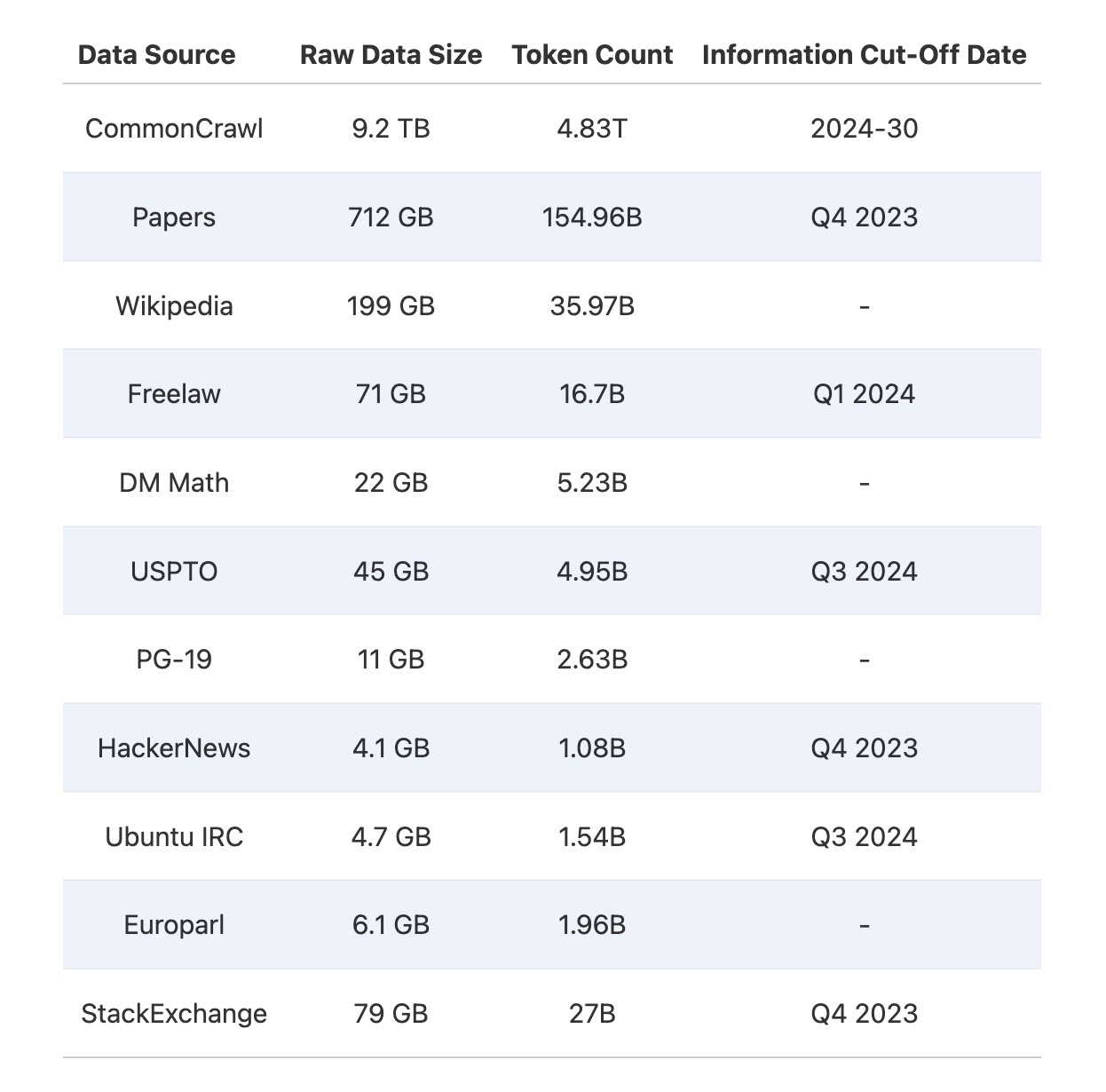
- 数据来源与去重:TxT360 汇集了来自多个领域的数据,比如法律文档(FreeLaw)和历史书籍(PG-19)等,还包含了CommonCrawl上的99个大规模网页快照。为了确保数据的独特性,项目进行了复杂的去重操作,保证相同内容不会多次出现。
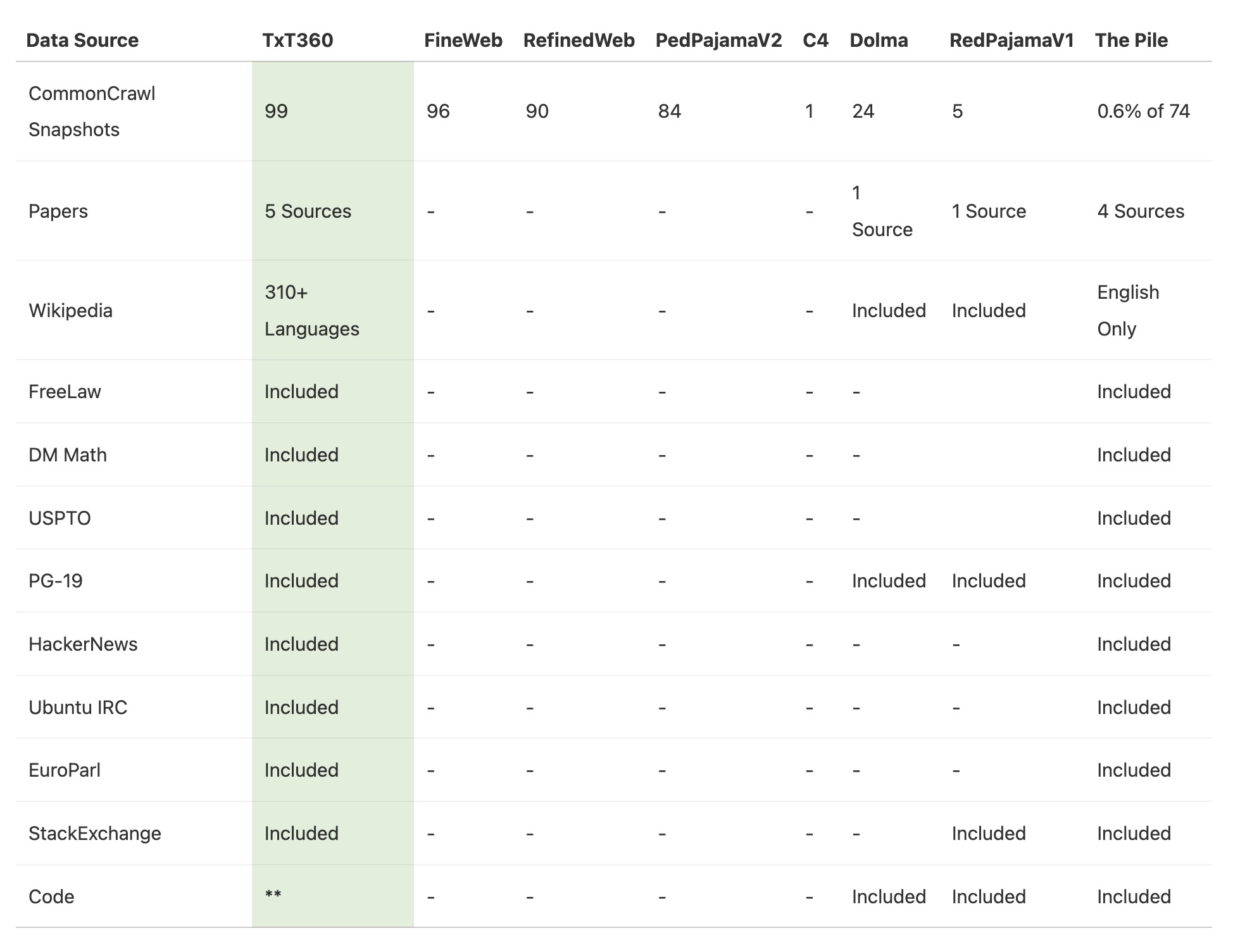
- 多样化的数据源:TxT360结合了99个CommonCrawl快照和14个精选高质量数据源,如FreeLaw、PG-19、Wikipedia、StackExchange、HackerNews、USPTO等。
- 去重处理:TxT360是首个对如此大规模的数据进行全球去重的预训练数据集,去除重复数据,避免了训练中的数据冗余和信息重复现象。通过正则表达式,TxT360移除了文档中的个人身份信息(PII),如电子邮件和IP地址,确保了数据的隐私和安全性。
- 规模与质量并重:通过整合网络数据和精选数据源,TxT360不仅具备大规模的多样性数据,同时确保了数据的高质量,适用于最前沿的LLM预训练。
- 元数据和精确控制:该数据集不仅包含文本,还存储了丰富的元数据(如每条数据的来源、类别等),使得研究人员能够精确控制数据的使用和分布。这意味着他们可以根据不同的需求调整数据的比例。
- 上采样策略:他们使用了一种特殊的策略来扩展数据量,最终创造了一个包含15万亿个token的超大语料库,去重后的约5.7万亿个高质量的tokens。在多个关键指标上,它表现优于其他类似的大规模数据集(如FineWeb 15T)。
- 先进的权重分配:TxT360 提供了更多的数据权重控制能力,允许用户灵活调整不同数据源的权重(比如可以增加或减少某种数据源的使用比例),从而优化语言模型的训练效果。这种功能在以往的数据集里不常见。


- 简单上采样策略:TxT360通过文档的重复次数设置权重,采用了简单的上采样方法,创建了一个超过15万亿tokens的数据集。上采样不仅提高了模型的学习速度,还确保了高质量数据源的合理利用。
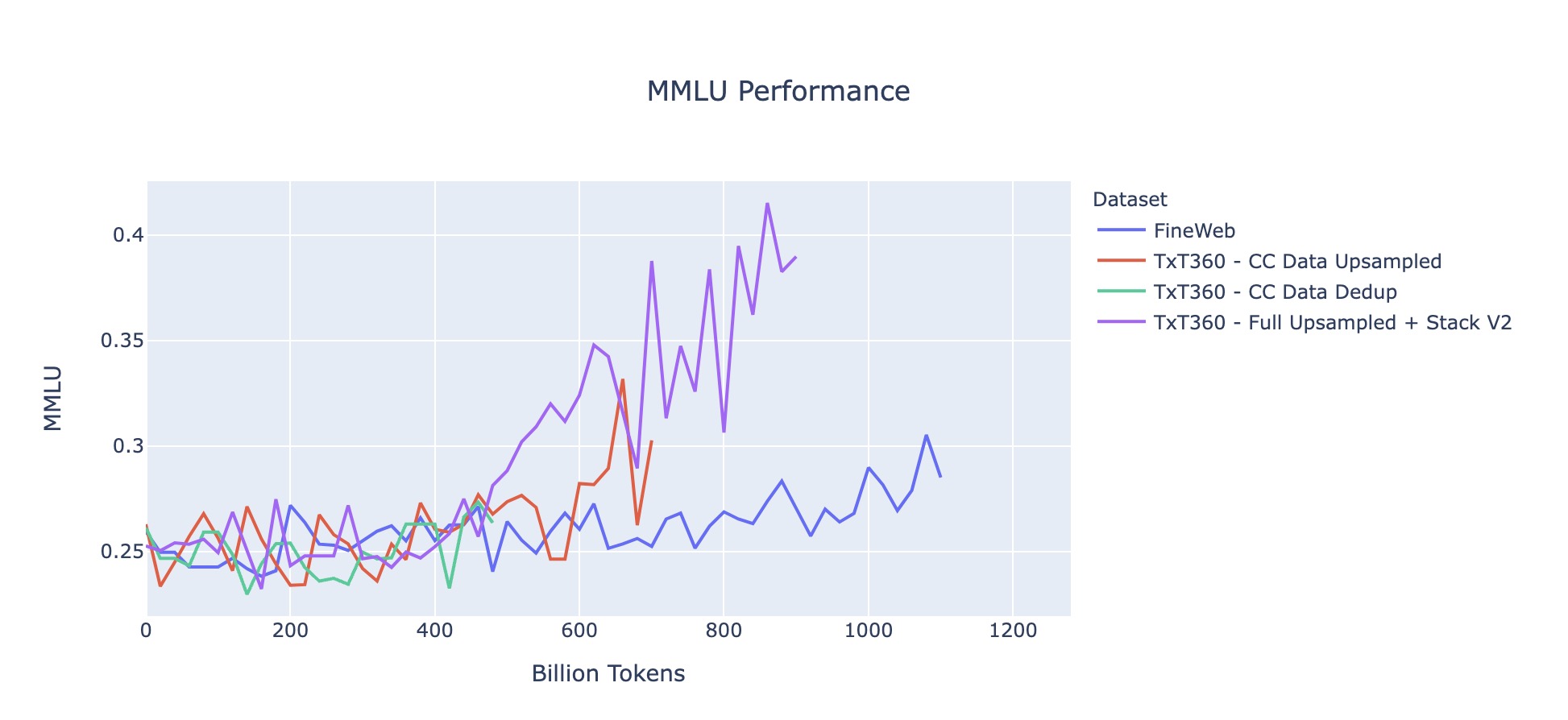
- 学习曲线与评估:通过对1.5万亿tokens的采样进行训练对比,TxT360的学习曲线优于FineWeb,尤其在关键评估指标上表现更为优异,如MMLU和NQ。同时,当结合代码数据(如Stack V2)后,学习曲线更为稳定,模型性能有明显提升。
- 困惑度(Perplexity)分析:对不同重复模式的数据进行了困惑度分析,显示出重复出现的数据在某些情况下可能与高质量内容相关。通过Perplexity评估,TxT360在文档去重、时间跨度等方面展示了良好的质量控制效果。