Playground v3(PGv3)是由Playground开发的一种文本到图像生成模型,其基于最新的大语言模型(LLMs)设计,在多语言理解、精确的RGB颜色控制、图像与文本的对齐等方面表现出色。

Playground v3 技术报告 :完全整合了大语言模型的图像生成模型 精细的图像生成与控制能力







{kind=link}
Recommendeds





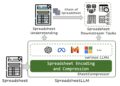

Playground v3(PGv3)是由Playground开发的一种文本到图像生成模型,其基于最新的大语言模型(LLMs)设计,在多语言理解、精确的RGB颜色控制、图像与文本的对齐等方面表现出色。