
GenWarp 是一种能够从一张图像生成该图像不同视角的新图像的方法。通常情况下,生成一个场景的不同视角需要多个角度的拍摄图像作为参考,但GenWarp只需要一张图像就可以完成这个任务。
在生成过程中,GenWarp 不仅能够生成视觉效果很好的新图像,还能保留原始图像中的重要信息和细节。例如,如果原图像中有一个特定的物体或场景细节,无论视角如何变化,生成的图像仍然会正确地显示这些细节,而不会因为视角的改变而出现信息丢失或错误。
简而言之,GenWarp 的独特之处在于,它可以在生成不同视角图像的同时,保持图像中原有的语义信息,即图像的意义和细节不会因为视角的改变而消失或被扭曲。
主要功能:
- 单视角图像生成新视角:GenWarp能够从一张输入图像生成多个不同视角的图像。用户只需要提供一张图像,GenWarp就可以生成该图像在其他视角下的样子。这个功能特别有用,例如在虚拟现实、电影制作等需要从多个角度展示场景的应用中。
- 语义信息保持:GenWarp在生成新视角图像时,能够保留原始图像中的语义信息,即图像中的重要细节和含义不会因为视角的改变而丢失。这一功能在保持生成图像与原图像的一致性方面至关重要。
- 处理复杂场景:与传统方法不同,GenWarp通过结合几何变形信号和自注意力机制,能够在处理复杂3D场景时生成高质量的图像。这使得它在面对具有挑战性的视角变化时,生成的图像更加真实和连贯。
- 泛化能力:GenWarp不仅擅长处理它已经“见过”的图像(域内图像),还能处理那些它在训练时未曾见过的图像类型(域外图像)。这使得该模型在实际应用中更加灵活和强大,能够应对更广泛的图像类型和场景。
 技术方法
技术方法
GenWarp提出了一种语义保持的生成变形框架,该框架通过增强的注意力机制在生成过程中学习如何在图像中进行变形和生成,确保在生成新视角图像时保留原始图像中的语义信息。
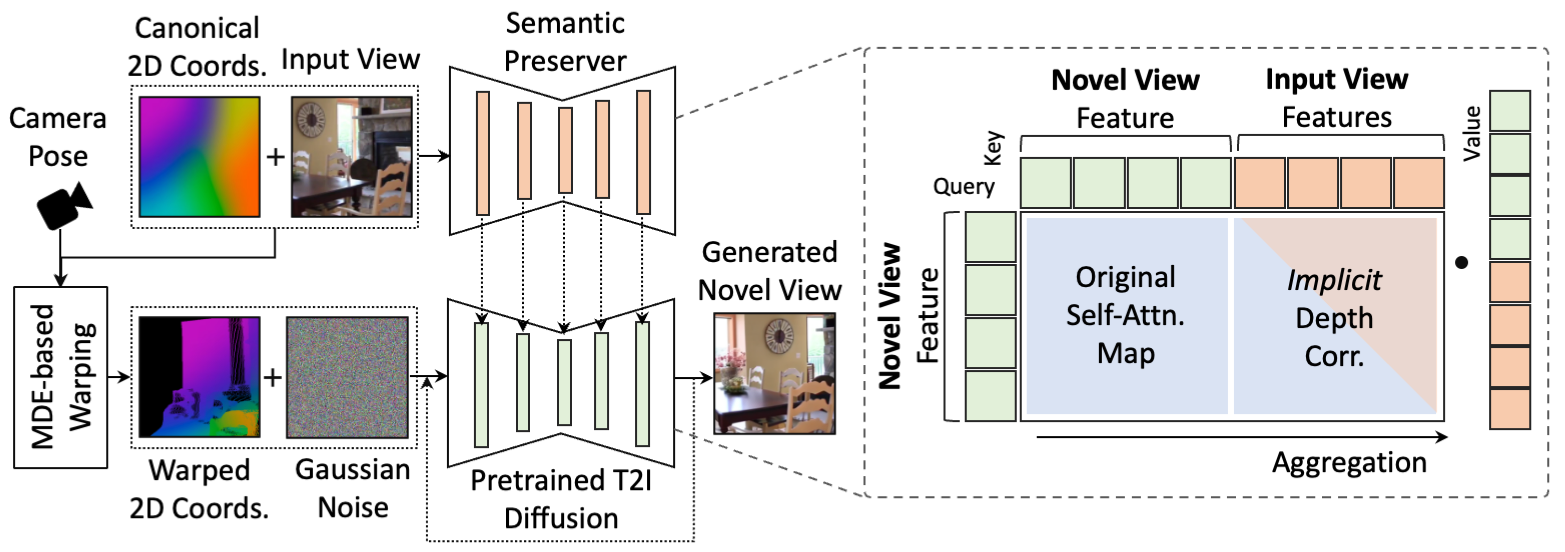
- 双流架构:GenWarp采用了一个双流架构,包括:
- 语义保持网络(Semantic Preserver Network):该网络负责提取并保持输入图像的语义特征。这些特征在生成新视角图像时被用来指导生成过程,以确保语义信息的保真。
- 生成扩散模型(Diffusion Model):该模型负责生成新视角图像。在生成过程中,模型结合了语义保持网络生成的特征,并通过几何变形信号进行指导。
- 增强的注意力机制GenWarp在扩散模型的自注意力机制中引入了跨视角注意力(Cross-View Attention),该注意力机制允许模型在生成过程中动态地决定哪些区域应依赖于输入图像的变形,哪些区域应依赖于生成能力。通过将自注意力和跨视角注意力相结合,GenWarp能够更准确地生成保留语义信息的新视角图像。
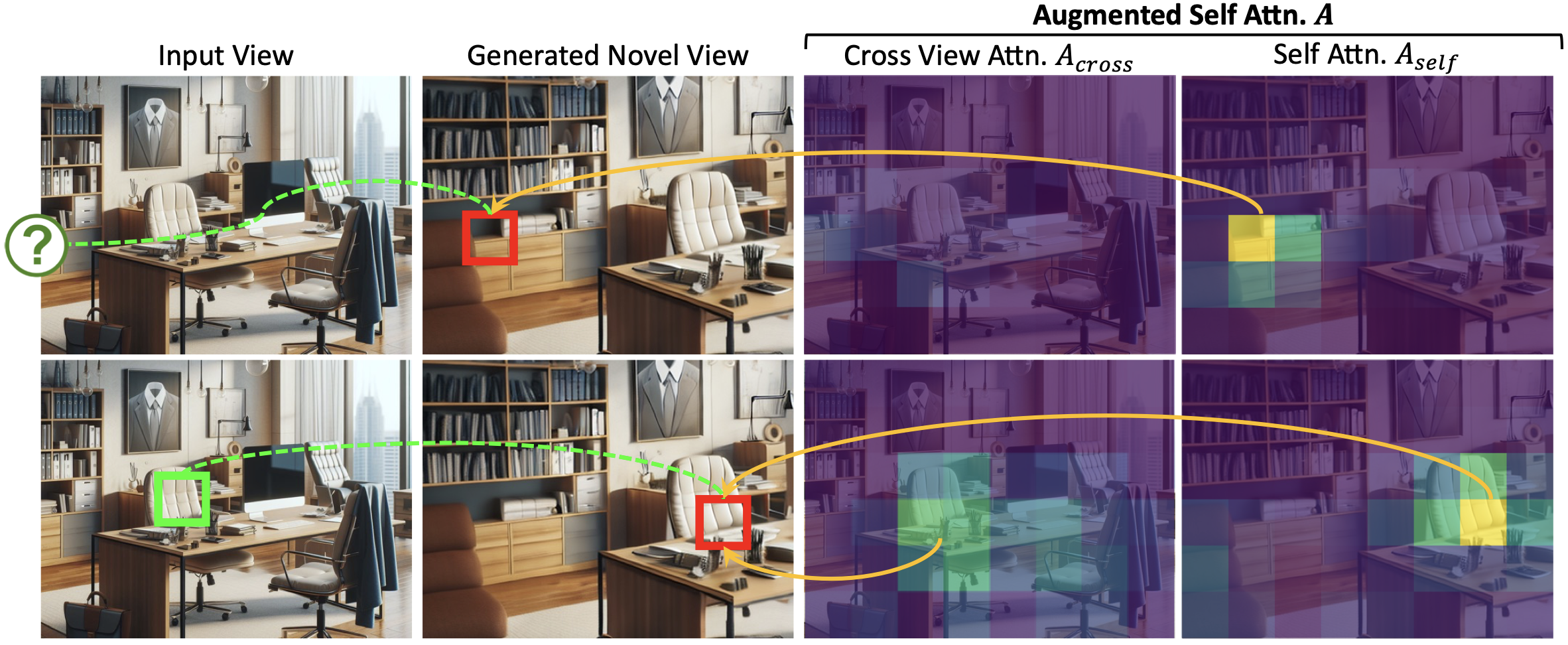
- 语义保持网络(Semantic Preserver Network)
- 语义特征提取: 在生成新视图时,模型会首先从输入图像中提取出语义特征。这是通过一个专门设计的语义保持网络完成的,该网络确保了在变形和生成过程中语义信息的保留。
- 坐标嵌入: GenWarp使用了2D坐标嵌入和变形坐标嵌入两种方式。输入视图的2D坐标嵌入用于表示原始图像的视角,而变形坐标嵌入则用于表示生成的新视图的目标视角。
- 隐式几何变形与传统方法不同,GenWarp在生成过程中实现了隐式几何变形,即模型在生成过程中学习如何进行几何变形,而不是依赖于直接变形后的图像。这样做可以减少由于深度估计误差导致的图像失真。
- 坐标嵌入
为了�










{kind=link}