

WebLlama 是一个研究项目,由 McGill University 的自然语言处理团队开发。它旨在构建和训练可以通过对话进行网页浏览的智能代理,这些代理基于 Llama-3 模型进行了优化和微调。
WebLlama基于 Meta AI最近发布的Llama-3-8B-Instruct模型进行微调的。这款模型专门为网页导航和对话任务进行了优化,使其能够有效处理与网页交互相关的复杂任务。
WebLlama 的性能在多个方面都优于 GPT-4V,特别是在与真实世界的网页浏览相关的任务上。
微调使用了名为WebLINX的数据集,该数据集包含超过100,000个网页导航和对话实例,每个实例都由专家注释人员收集和验证。为了训练这款模型,我们选取了其中的24,000个精选子集。这种精心策划的数据集确保了模型训练的高质量和代理的实用性。
该模型现在已经可以在Hugging Face Model Hub上获取,模型名称为McGill-NLP/Llama-3-8B-Web。同时,用于训练和评估的数据也可以在Huggingface Hub上找到,数据集名称为McGill-NLP/WebLINX。

主要功能
WebLlama 能够处理连续的对话,这允许用户通过多轮交流给代理提供指令,并在完成任务过程中获取反馈。代理能够与现代网页自动化框架如 Playwright 或 Selenium 集成,使其能在实际的浏览器环境中执行动作,如点击、滚动、填写表单等。
WebLlama 能够执行以下功能:
-
自动网页浏览:代理能够根据用户的指令自动浏览网页,执行搜索、导航和信息检索等任务。
-
交互对话:与用户通过自然语言进行交互,理解用户的指令并提供反馈。
-
执行网页操作:执行诸如点击链接、填写和提交表单等网页上的动作。
-
自动任务完成:在用户提供指令的情况下完成特定的任务,如预定酒店、购物或查找信息。
-
数据收集和应用:可以被训练来从网页收集特定信息,并将其用于不同的应用,比如自动化的数据汇总。
-
提高效率:帮助用户提高完成在线任务的效率,尤其是在多任务处理或需要快速反馈的场景中。
WebLINX评估基准
WebLlama 提供了一套评估体系:WebLINX,可以系统地评估代理在多种网页导航任务中的性能,包括简单的指令遵循和复杂的对话引导浏览。
WEBLINX 是一个大规模基准,包含 2300 个专家演示的 10 万次网络会话导航交互。我们的基准涵盖了 150 多个真实世界网站上的各种模式,可用于在不同场景中训练和评估代理。
-
基准测试:代理在特定的基准测试上进行评估,这些测试专门设计来衡量其在实际网页浏览任务中的表现。WebLlama使用的主要基准测试是WebLINX,它包含了真实世界的网页交互场景。
-
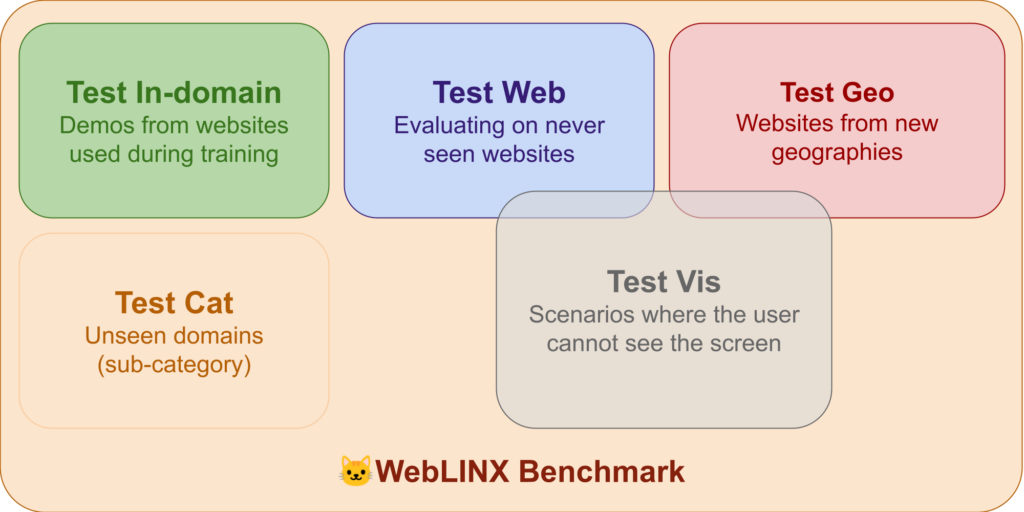
真实世界的场景:WebLINX基准测试包含多个现实场景的测试,例如访问新网站、探索新领域、在未见过的地理位置进行导航,以及用户无法看到屏幕时依赖对话的情况。
-
综合评估:在WebLINX基准测试中,代理的性能会在多个维度上进行评估,包括选择有用链接的能力、点击相关元素的准确度,以及形成对齐回应的质量。
-
定量指标:使用定量指标,如链接选择的准确性百分比(seg-F1)、点击相关元素的交叉比率(IoU),以及回应质量的字符准确率(chr-F1),来衡量性能。
-
横向比较:WebLlama的性能与其他先进模型如GPT-4进行对比,以突出其在特定任务上的优势。
WebLlama选择WebLINX作为首个基准测试的原因是,它不仅提供了用于训练的数据,还特别设计了四种真实世界的测试情境,这些情境能全面检验智能代理的适应性和泛化能力。这四种情境包括:
- 新网站:测试代理对从未访问过的网站的适应能力。
- 新领域:评估代理在面对新类型的网站内容时的表现。
- 未见过的地理位置:检查代理处理与特定地区相关网站的能力。
- 无法看屏幕的场景:模拟用户无法看到屏幕,完全依赖于与代理的对话来浏览网页的情境。
代理控制浏览器,按照用户指令,通过多轮对话的方式解决现实世界中的任务,例如在Quandoo上寻找一家柏林的意大利餐厅并查询是否在某个时间能否订位
WebLINX涵盖了150个不同的网站,这些网站包括了各种常见的在线活动,如预订(booking)、购物(shopping)、写作(writing)、信息查询(knowledge lookup)以及更复杂的任务,比如操作电子表格。这种多样化的测试环境可以确保WebLlama不仅在训练环境中表现良好,而且能够在用户日常�














{kind=link}