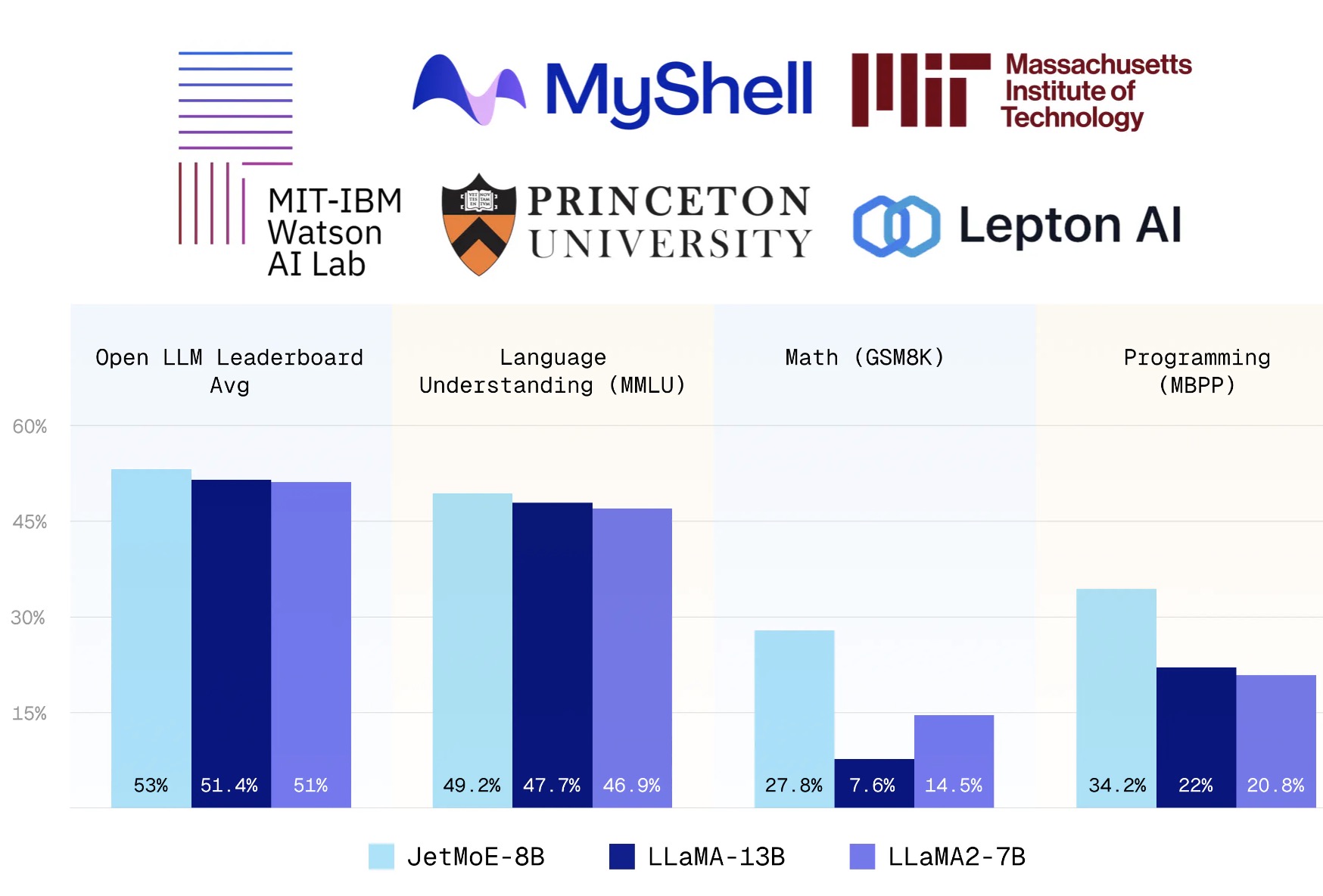
JetMoE-8B 是一个高性能的大语言模型,它以不到10万美元的成本训练,性能超过了Meta AI的LLaMA2-7B模型,后者拥有数十亿美元的训练资源。这表明训练大语言模型(LLMs)的成本可以远低于普遍预期。 <div class="w-full text-token-text-primary" dir="auto" data-testid="conversation-turn-3"> <div class="px-4 py-2 justify-center text-base md:gap-6 m-auto"> <div class="flex flex-1 text-base mx-auto gap-3 juice:gap-4 juice:md:gap-6 md:px-5 lg:px-1 xl:px-5 md:max-w-3xl lg:max-w-[40rem] xl:max-w-[48rem]"> <div class="relative flex w-full flex-col agent-turn"> <div class="flex-col gap-1 md:gap-3"> <div class="flex flex-grow flex-col max-w-full"> <div class="min-h-[20px] text-message flex flex-col items-start gap-3 whitespace-pre-wrap break-words [.text-message+&]:mt-5 overflow-x-auto" dir="auto" data-message-author-role="assistant" data-message-id="c782886a-8149-42ee-8e16-d72daf67a3d1"> <div class="markdown prose w-full break-words dark:prose-invert light"> 模型利用公开数据集进行训练,任何实验室都能以较低成本进行模型微调。JetMoE-8B采用了一种稀疏激活的架构,使其在执行任务时只激活必要的参数,从而降低了运行成本。 <img class="aligncenter size-large wp-image-6203" src="https://img.xiaohu.ai/2024/04/Jietu20240416-195326@2x-1024x694.jpg" alt="" width="1024" height="694" /> <h3><strong>技术细节</strong></h3> <ul> <li>JetMoE采用稀疏激活架构,灵感来自ModuleFormer。JetMoE-8B包含24个块,每个块包含两个MoE层:注意力头混合(MoA)和MLP专家混合(MoE)。每个MoA和MoE层有8个专家,并且每个输入令牌激活2个专家。</li> <li>JetMoE-8B的总参数量为80亿,训练数据为1.25万亿令牌,来源于公开可用的数据集。<img class="aligncenter wp-image-6201" src="https://img.xiaohu.ai/2024/04/3-architecture.webp" alt="" width="389" height="564" /></li> </ul> </div> </div> </div> <div class="mt-1 flex gap-3 empty:hidden"> <div class="text-gray-400 flex self-end lg:self-center items-center justify-center lg:justify-start mt-0 -ml-1 h-7 gap-[2px] visible"> <p class="flex"><strong>具体方法:</strong></p> <ol> <li><strong>稀疏门控混合专家(SMoE)架构</strong>:JetMoE-8B采用了一种基于MoE(Mixture of Experts)的架构,这种架构可以在不牺牲性能的情况下显著降低计算成本。在JetMoE-8B中,每个输入令牌只激活部分专家(expert),从而减少了总体的计算需求。具体来说,尽管总参数量为80亿,但每个输入令牌仅激活约22亿参数。 <ul> <li><strong>模块化设计</strong>:JetMoE-8B使用了由多个独立模块组成的架构,每个模块包含注意力机制和前馈网络(FFN)层,而每层又实现了基于专家的混合(MoE)。这种设计允许在每次推理时只激活一部分参数,减少了必须处理的数据量,从而节省了计算资源。</li> <li><strong>双层稀疏激活</strong>:JetMoE在注意力和前馈网络层都实现了稀疏激活,不同于传统的只在前馈层使用MoE的做法。这意味着在处理每个输入时,只有选定的“专家”参与计算,大大减少了操作的复杂度和所需的计算资源。</li> </ul> </li> <li><strong>高效的训练策略</strong>:采用了有效的训练方法,如使用常数学习率预热和后期使用指数衰减学习率,以及精心设计的数据混合策略来优化模型训练。这种策略帮助模型在不同阶段集中学习最有价值的数据,从而提高学习效率和最终模型的性能。 <ul> <li><strong>数据选择</strong>:该模型完全使用公开可获取的数据集进行训练,避免了昂贵的数据采购成本。这包括从网站、学术论文、编程代码等多种来源收集的大量数据,这些数据来源都是免费或开源的。</li> <li><strong>两阶段训练法</strong>:第一阶段使用大量的开源数据进行预训练,设置一个恒定的学习率以及线性预热期;第二阶段则转向更具挑战性的数据集,采用指数衰减的学习率,以提高模型在特定任务上的表现。</li> <li><strong>优化的数据混合</strong>:在训练过程中,通过精心设计的数据混合策略来优化模型的学习,强调了从高质量数据中学习的重要性,特别是在学习率衰减阶段增加了这些数据的比重。</li> </ul> </li> <li><strong>GPU优化和成本控制</strong>:项目组利用了高效的硬件配置,通过有限的GPU资源(30,000 H100 GPU小时)进行训练,同时优化了模型训练的时间和资源使用,确保了成本效益。 <ul> <li><strong>GPU使用优化</strong>:尽管训练了一个拥有数十亿参数的模型,项目组通过有效管理GPU使用时间(30,000小时H100 GPU),控制了训练成本。这包括了对训练任务的调度优化,使得每个GPU都能在最大效率下运行。</li> <li><strong>并行处理和负载平衡</strong>:采用流水线并行处理技术优化训练过程,减少了因专家不平衡导致的计算资源浪费。此外,通过在模型的不同部分之间均匀分配计算任务,确保了资源的充分利用。</li> </ul> </li> </ol> </div> </div> <h3 class="pr-2 lg:pr-0">训练情况</h3> <img class="aligncenter wp-image-6204" src="https://img.xiaohu.ai/2024/04/Jietu20240416-200053@2x-1024x600.jpg" alt="" width="757" height="444" /> <div class="w-full text-token-text-primary" dir="auto" data-testid="conversation-turn-11"> <div class="px-4 py-2 justify-center text-base md:gap-6 m-auto"> <div class="flex flex-1 text-base mx-auto gap-3 juice:gap-4 juice:md:gap-6 md:px-5 lg:px-1 xl:px-5 md:max-w-3xl lg:max-w-[40rem] xl:max-w-[48rem]"> <div class="relative flex w-full flex-col agent-turn"> <div class="flex-col gap-1 md:gap-3"> <div class="flex flex-grow flex-col max-w-full"> <div class="min-h-[20px] text-message flex flex-col items-start gap-3 whitespace-pre-wrap break-words [.text-message+&]:mt-5 overflow-x-auto" dir="auto" data-message-author-role="assistant" data-message-id="1b1d06c5-1c43-4640-baa2-c2e85dc84a5c"> <div class="markdown prose w-full break-words dark:prose-invert light"> <strong>1. 预训练数据源</strong> JetMoE-8B使用了广泛的开源数据集进行预训练,这些数据集包括: <ul> <li><strong>RefinedWeb</strong>: 从公共网页数据中提取的高质量文本数据,该数据通过MacroData Refinement (MDR)流程进行优化处理,以提升数据质量。</li> <li><strong>The Pile</strong>: 包含多种类型的数据,如Wikipedia文章、科学论文(arXiv)、开源图书等,总量达到825GB,涵盖广泛的知识领域和语言使用场景。</li> <li><strong>Code Datasets</strong>: 包括从GitHub上收集的各种编程语言的源代码,这些数据帮助模型理解和生成编程相关的内容。</li> <li><strong>Math and Scientific Data</strong>: 特别包括用于数学和科学问题解答的数据集,如数学问题集和科学文档。</li> </ul> <strong>2. 训练策略</strong> JetMoE-8B的训练采用了两阶段方法,优化了学习过程中的数据使用和参数调整: <ul> <li><strong>第一阶段(Warmup and Stable Learning Rate)</strong>: <ul> <li>使用大规模开源数据进行训练,目的是让模型掌握广泛的语言结构和知识。</li> <li>应用线性预热和恒定学习率,使模型在初期可以稳定地适应各种语言模式。</li> </ul> </li> <li><strong>第二阶段(Exponential Decay Learning Rate)</strong>: <ul> <li>在这一阶段,模型使用从第一阶段训练中筛选的高质量数据进行微调。</li> <li>采用指数衰减学习率,加强模型在特定任务(如编程、数学问题解答)上的表现。</li> <li>增加高质量数据的比重,这些数据通常来自更具挑战性的语言使用场景,能够进一步提升模型的性能。</li> </ul> </li> </ul> <strong>3. GPU资源管理和优化</strong> <ul> <li><strong>GPU时长管理</strong>:训练过程中使用了30,000 H100 GPU小时,通过精确控制每个训练阶段的GPU使用时长和任务调度,确保成本效益。</li> <li><strong>Pipeline并行处理</strong>:采用pipeline并行策略优化训练过程,减少了因数据传输和处理延时造成的资源浪费。</li> </ul> </div> </div> </div> <div class="mt-1 flex gap-3 empty:hidden"> <div class="text-gray-400 flex self-end lg:self-center items-center justify-center lg:justify-start mt-0 -ml-1 h-7 gap-[2px] visible"> <h3><strong>性能评估</strong></h3> <ul> <li>在与Open LLM排行榜相同的评估方法下,JetMoE-8B的性能甚至超过了LLaMA2-7B、LLaMA-13B和DeepseekMoE-16B。与具有类似训练和推理计算的模型(如Gemma-2B)相比,JetMoE-8B展示了更优异的表现。</li> </ul> </div> </div> <div class="pr-2 lg:pr-0"><img class="aligncenter size-large wp-image-6202" src="https://img.xiaohu.ai/2024/04/Jietu20240416-194834@2x-1024x676.jpg" alt="" width="1024" height="676" /></div> </div> <div class="absolute"> <div class="flex w-full gap-2 items-center justify-center"> <h3><strong>完全开源</strong></h3> JetMoE-8B的代码和训练过程完全开源,包括详细的技术报告和训练细节,数据处理、模型架构和训练策略等, </div> </div> </div> </div> </div> </div> <div class="w-full text-token-text-primary" dir="auto" data-testid="conversation-turn-12"> <div class="px-4 py-2 justify-center text-base md:gap-6 m-auto"> <div class="flex flex-1 text-base mx-auto gap-3 juice:gap-4 juice:md:gap-6 md:px-5 lg:px-1 xl:px-5 md:max-w-3xl lg:max-w-[40rem] xl:max-w-[48rem]"> <div class="flex-shrink-0 flex flex-col relative items-end"> <div class="pt-0.5"> <div class="gizmo-shadow-stroke flex h-6 w-6 items-center justify-center overflow-hidden rounded-full"> <ul class="list-none pl-0" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216"> <li class="pl-0" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216" data-immersive-translate-paragraph="1">Github: <a href="https://github.com/myshell-ai/JetMoE" target="_blank" rel="noopener" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216">https://github.com/myshell-ai/JetMoE</a></li> <li class="pl-0" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216" data-immersive-translate-paragraph="1">HuggingFace: <a href="https://huggingface.co/jetmoe/jetmoe-8b" target="_blank" rel="noopener" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216">https://huggingface.co/jetmoe/jetmoe-8b</a></li> <li class="pl-0" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216" data-immersive-translate-paragraph="1">Chat Demo on Lepton AI: <a href="https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat" target="_blank" rel="noopener" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216">https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat</a></li> <li class="pl-0" data-immersive-translate-walked="0e2dedbc-5b9f-488e-8ed5-817d6ebbc216" data-immersive-translate-paragraph="1"><span class="notranslate immersive-translate-target-wrapper" lang="zh-CN" data-immersive-translate-translation-element-mark="1"><span class="notranslate immersive-translate-target-translation-theme-none immersive-translate-target-translation-block-wrapper-theme-none immersive-translate-target-translation-block-wrapper" data-immersive-translate-translation-element-mark="1"><span class="notranslate immersive-translate-target-inner immersive-translate-target-translation-theme-none-inner" data-immersive-translate-translation-element-mark="1">技术报告:<a href="https://arxiv.org/pdf/2404.07413.pdf" target="_blank" rel="noopener">https://arxiv.org/pdf/2404.07413.pdf</a></span></span></span></li> </ul> </div> </div> </div> </div> </div> </div> </div> </div> </div> </div> </div>






{kind=link}