
Meta Reality Labs开发一套名为“Sapiens”的人工智能模型。主要提供用于处理人类视觉任务的高分辨率模型,专门用来分析和理解图片或视频中的人和他们的动作。这些任务包括识别人类的姿势、分割身体部位、测量深度和判断物体表面的角度。模型在超过 3 亿张人类图像上进行了训练,能够在各种复杂的环境下表现出色。
- 2D姿态估计:识别和估计人类身体在二维图像中的姿势。
- 身体部位分割:将图像中的人类身体部分进行精确分割,例如识别和区分手、脚、头等不同部位。
- 深度估计:预测图像中物体的深度信息,这有助于理解三维空间中的距离和布局。
- 表面法线预测:推断图像中物体表面的方向,这对于更好地理解物体的形状和材质非常重要。
这些模型可以处理非常高分辨率的图像,并且能够在很少的标注数据甚至是完全合成的数据的情况下,仍然表现出色。这使得它们在实际应用中非常有用,尤其是在数据稀缺的情况下。
此外,Sapiens模型设计简单,易于扩展。当增加模型的参数数量时,其在各项任务中的性能会显著提升。在多个基于人类视觉的测试中,Sapiens模型已经超过了现有的基线模型,表现优异。
应用场景
Sapiens模型主要应用于多个关键的人类视觉任务领域,其应用场景和用途包括:
1. 2D姿势估计
- 应用场景:在视频监控、虚拟现实、运动捕捉、医疗康复等领域,2D姿势估计是关键技术之一。它可以识别人类的姿势、动作和手势。
- 功能:Sapiens能够准确地检测并预测人体的关键点(如关节、面部特征等),即使在多人场景中也能良好地工作。这使得它在动作分析和人机交互中具有广泛的应用潜力。

2. 身体部位分割
- 应用场景:在医学图像分析、虚拟试衣、动画制作以及增强现实(AR)等领域,精确的人体部位分割是基础性技术。
- 功能:Sapiens模型能够将图像中的每个像素精确分类为身体的不同部位(例如上半身、下半身、面部细节等)。这有助于开发更精细化的虚拟服装试穿、医学诊断工具以及更加自然的虚拟人物动画。

3. 深度估计
- 应用场景:深度估计在自动驾驶、机器人导航、3D建模和虚拟现实中至关重要,帮助理解场景中的三维结构。
- 功能:Sapiens模型能够从单张图像中推测出场景的深度信息,特别是在人类场景中。通过生成高质量的深度图,它支持各种需要理解空间关系的应用,如自动驾驶中的障碍物检测和机器人路径规划。
4. 表面法线预测
- 应用场景:表面法线预测广泛应用于3D渲染、物理模拟、逆向工程和光照处理等领域。
- 功能:Sapiens模型可以推断图像中每个像素的表面法线方向,这对于生成高质量的3D模型和实现更真实的光照效果至关重要。在需要精确表面特征的应用中,如虚拟现实和数字内容创作中,这一功能显得尤为重要。
5. 通用人类视觉任务
- 应用场景:Sapiens模型可以应用于任何需要理解和分析人类图像的场景,包括社交媒体内容分析、安全监控、运动科学研究以及数字人类生成等。
- 功能:由于其在多个任务上的强大表现,Sapiens可以作为一个通用的基础模型,支持各种以人为中心的视觉任务,从而加速相关应用的开发。
6. 虚拟现实和增强现实
- 应用场景:虚拟现实(VR)和增强现实(AR)应用中,需要高度精确的人体姿势和结构理解,以实现沉浸式体验。
- 功能:Sapiens通过提供高分辨率、精确的人体姿势和部位分割,支持在虚拟环境中创建逼真的人类形象,并且能够动态适应用户的动作变化。
7. 医疗与健康
- 应用场景:在医疗成像和康复训练中,精确的姿势检测和人体分割可以用于病患监控、治疗跟踪和康复指导。
- 功能:Sapiens模型能够帮助医疗专业人士分析患者的姿势和运动情况,提供更个性化和有效的治疗方案。
技术方法
1. 数据集与预处理
- Humans-300M数据集:Sapiens模型的预训练数据集为Humans-300M,一个包含3亿张“自然场景”(in-the-wild)人类图像的大规模数据集。数据集经过精心策划,去除了水印、文本、艺术描绘或不自然的元素。
- 数据筛选:使用预训练的边界框检测器筛选图像,仅保留检测分数高于0.9且边界框尺寸大于300像素的图像,从而确保数据质量。
- 多视图捕捉与标注:为精确捕捉人体姿势和部位,使用多视图捕捉技术获取图像,并手动标注了308个关键点和28个身体部位类别,生成高质量的标注数据。
2. 模型架构
- 视觉变换器(Vision Transformers, ViT):Sapiens模型采用了Vision Transformers(ViT)架构,该架构在图像分类和理解任务中表现优异。通过将图像划分为固定大小的非重叠小块(patch),模型能够处理高分辨率输入,并进行细粒度的推理。
- 编码器-解码器架构:模型的基本架构为编码器-解码器。编码器负责从图像中提取特征,并初始化为预训练权重,解码器则是一个轻量级且任务特定的模块,随机初始化并与编码器一起进行微调。
3. 遮掩自编码器(Masked Autoencoder, MAE)预训练
- 遮掩策略:使用MAE方法进行模型预训练,模型通过观察部分遮掩的图像来重建原始图像。这种策略使模型能够学习到更加鲁棒的特征表示。
- 高分辨率输入:预训练时的输入图像分辨率设置为1024像素,相比于现有的视觉模型,这带来了4倍的计算复杂度,但同时也提高了模型的输出质量。
- 多任务学习:通过在高质量的标签数据上进行微调,Sapiens模型能够处理2D姿势估计、身体部位分割、深度估计和表面法线预测等多项任务。
4. 关键任务方法
- 2D姿势估计:采用自上而下的方法,从输入图像中检测K个关键点的位置。模型通过预测每个关键点的热图来确定它们的位置,训练过程中使用均方误差损失函数(MSE)优化模型。
- 身体部位分割:将输入图像中的每个像素分类为C个类别,采用加权交叉熵损失函数(WeightedCE)进行训练。模型支持标准的20类分割词汇表和扩展的28类词汇表。
- 深度估计:采用修改后的分割架构进行深度估计,输出通道为1(回归任务),使用合成数据生成的高分辨率深度图进行训练,损失函数为相对深度损失(Ldepth)。
- 表面法线预测:预测每个像素的法线向量的xyz分量,训练过程中使用的损失函数为Lnormal,包括L1损失和法线向量之间的点积损失。
5. 大规模预训练与微调
- 预训练规模:Sapiens模型在3亿张图像上进行大规模预训练,并在多达1024个A100 GPU上运行18天,使用PyTorch框架。
- 优化方法:采用AdamW优化器,并结合余弦退火(cosine annealing)和线性衰减(linear decay)学习率策略进行优化。不同层次使用差分学习率,以确保模型的泛化能力。
- 微调策略:在预训练的基础上进行微调,输入图像被调整为4:3的宽高比,并使用标准的数据增强方法(如裁剪、缩放、翻转和光度失真)。
 实验结果:
实验结果:
- 2D姿势估计:
- Sapiens模型在2D姿势估计任务中表现优异,特别是在全身、面部、手部和足部的关键点检测上,显著超越了现有的最先进方法。
- 身体部位分割:
- Sapiens模型在身体部位分割任务中实现了更高的平均交并比(mIoU)和像素准确率(mAcc),在细节丰富的分割任务中表现尤为出色。
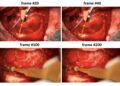
- 深度估计:
- Sapiens模型在深度估计任务中表现出色,尤其在人类场景中,其深度估计精度显著优于现有方法,特别是在多人的复杂场景中。
- 表面法线预测:
- 在表面法线预测任务中,Sapiens模型展现了更高的精度和一致性,在不同的场景下均表现出色,显著降低了平均角度误差。
- 预训练数据源:
- 以人为中心的预训练数据集对提升Sapiens模型在各项任务中的表现至关重要,证明了人类特定数据的重要性。
- 零样本泛化:
- Sapiens模型展示了广泛的零样本泛化能力,能够适应不同的场景、年龄段和视角,尽管训练数据有限。
项目地址:https://about.meta.com/realitylabs/codecavatars/sapiens














{kind=link}