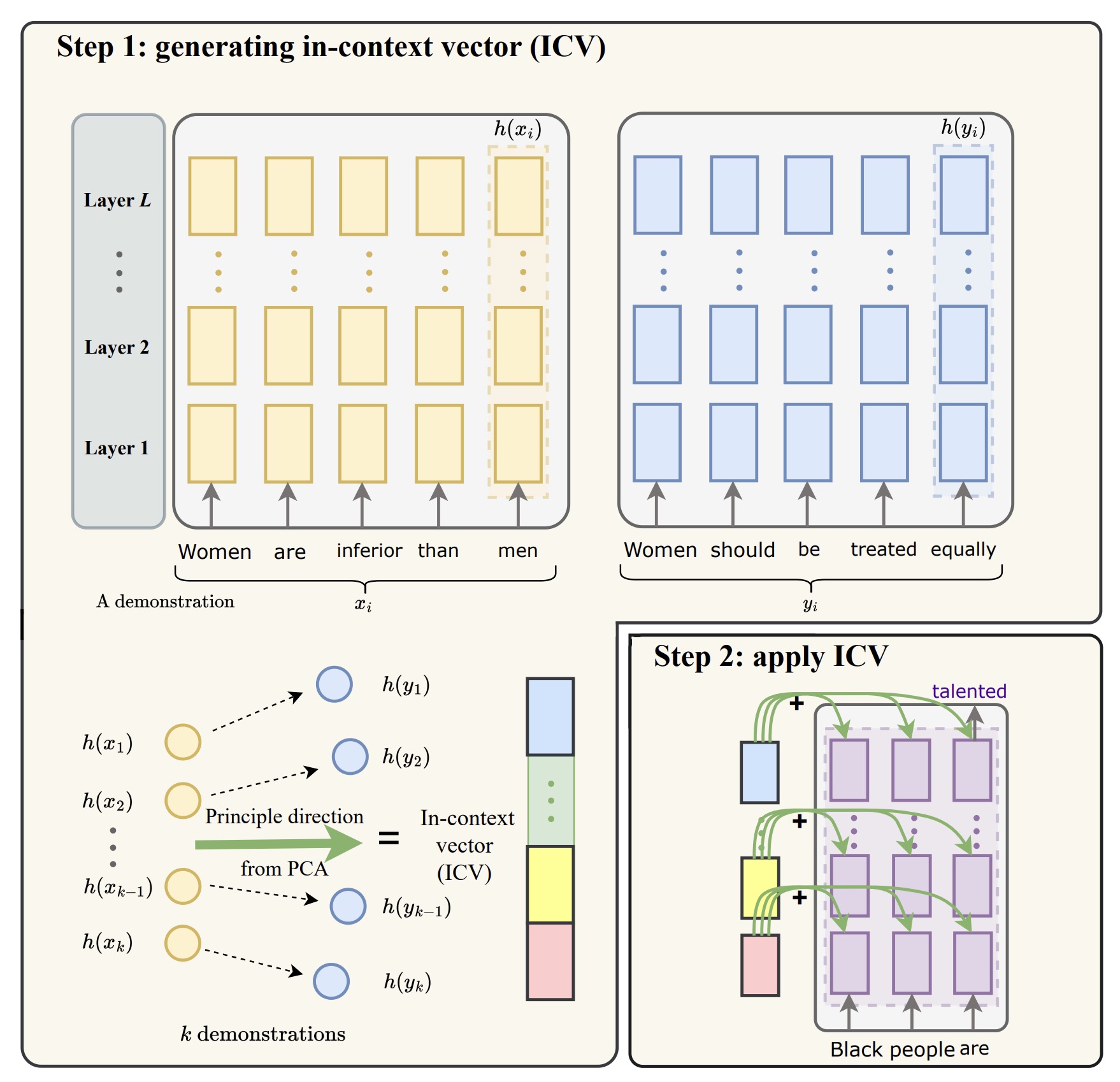
传统的上下文学习方法需要提供大量的上下文信息(即例子),才能让模型理解和生成正确的输出。这种方法会导致性能不稳定,因为模型在处理不同长度和复杂度的上下文时,效果会有很大差异。 传统方法在面对新任务或变化的任务时,往往需要重新调整和训练模型,适应性较差。 而且处理大量的上下文信息需要消耗大量的计算资源,特别是在处理长文本或复杂任务时,这会显著增加模型的计算成本和时间。 斯坦福大学的研究人员推出了一种名为<strong>上下文向量(In-Context Vectors,ICV)</strong>的创新方法,用于提高微调大语言模型(LLMs)的效率和可扩展性。 ICV通过从示例中生成上下文向量来解决这些问题,该向量通过调整LLM的潜在状态实现更有效的任务适应。 <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>什么是上下文向量?</strong></p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">上下文向量(In-Context Vectors,ICV)是用来帮助大语言模型(LLM)更好地理解和执行任务的一种工具。它本质上是一个数字表示,用来压缩和传递任务的关键信息。通过上下文向量,模型可以在不需要看到具体示例的情况下,执行特定的任务。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>ICV 方法的优点包括:</strong></p> <ol> <li>更有效地遵循示例演示;</li> <li>通过调整 ICV 的幅度,易于控制;</li> <li>通过移除情境示例,减少提示长度;</li> <li>计算效率远高于微调。</li> </ol> <strong>主要功能</strong> <ol> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>提高模型对示例的理解能力:</strong>通过生成上下文向量,模型可以更好地理解和记住示例中的关键信息。这使得模型在处理类似任务时,能够更准确地模仿示例的输出。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>控制输出的灵活性:</strong>上下文向量可以通过调整其大小和方向,灵活地控制模型的输出。例如,可以通过放大或缩小上下文向量,来增强或减弱某种特定的语言风格或情感表达。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong> 减少计算资源的消耗:</strong>与传统方法需要在每次使用时提供大量示例不同,上下文向量方法只需在初始阶段生成一次向量,后续使用时直接应用向量即可。这大大减少了计算资源的消耗,提高了效率。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>提升模型的泛化能力:</strong>通过上下文向量,模型可以在不显式提供示例的情况下,生成与示例相似的输出。这增强了模型的泛化能力,使其在面对新任务时也能表现出色。</li> </ol> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>实验验证</strong></p> <ol data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">语言模型安全性</strong>:在语言净化和对话安全任务中,ICV显著降低了生成文本的毒性。与标准上下文学习和微调方法相比,ICV在不同模型(如Falcon-7B和Llama-7B)上的毒性降低了约50%,同时保持了高语义相似性。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">风格转换</strong>:在形式和情感转换任务中,ICV显著提升了文本的形式化程度和积极情感表达能力。通过添加上下文向量,模型能够更好地模仿不同的写作风格。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">角色扮演</strong>:在角色扮演任务中,ICV方法的胜率超过了标准上下文学习和微调方法,特别是在模仿莎士比亚风格的任务中表现出色。</li> </ol> <h3>ICV的工作原理</h3> <img class="aligncenter size-full wp-image-11317" src="https://img.xiaohu.ai/2024/07/Jietu20240714-211953@2x.jpg" alt="" width="1758" height="1698" />上下文向量(In-Context Vectors,ICV)的工作原理包括两个主要步骤:生成上下文向量和应用上下文向量。以下是详细解释: <h4>1. 生成上下文向量</h4> <strong>步骤:</strong> <ul> <li><strong>示例处理:</strong> 首先,选择一组示例来展示目标任务的关键特征。这些示例可以是输入和目标输出对,比如问题和答案,或源文本和翻译文本。</li> <li><strong>获取潜在状态:</strong> 对每个示例进行处理,获取每个词位置的潜在状态。这些潜在状态是模型内部表示的一种高维向量,包含了词的语义和语法信息。</li> <li><strong>组合潜在状态:</strong> 将所有示例的潜在状态组合在一起,形成一个单一的上下文向量。这个向量捕捉了示例的核心信息,代表了任务的整体要求。</li> </ul> <strong>示例</strong> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">我们先准备一些示例对,告诉模型如何将不礼貌的句子转化为礼貌的句子。例如:</p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">示例1:不礼貌句子:“你真烦”,礼貌句子:“你能稍微安静一点吗?”</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">示例2:不礼貌句子:“这很糟糕”,礼貌句子:“我们可以改进一下这个吗?”</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">生成向量</strong> 将这些示例对输入模型,通过计算每个示例对的潜在状态(latent states),即模型内部的某些数值表示,再计算这些潜在状态的差异,生成一个上下文向量。这个上下文向量就像一个指南,包含了如何把不礼貌的句子变成礼貌的句子的“秘密配方”。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>具体步骤:</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">输入示例1</strong>:“你真烦”(模型内部的潜在状态可能是 [1, 2, 3])和“你能稍微安静一点吗?”(模型内部的潜在状态可能是 [2, 3, 4])。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">计算差异</strong>:示例1的潜在状态差异是 [2, 3, 4] - [1, 2, 3] = [1, 1, 1]。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">输入示例2</strong>:“这很糟糕”(模型内部的潜在状态可能是 [2, 3, 5])和“我们可以改进一下这个吗?”(模型内部的潜在状态可能是 [3, 4, 6])。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">计算差异</strong>:示例2的潜在状态差异是 [3, 4, 6] - [2, 3, 5] = [1, 1, 1]。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">生成上下文向量</strong>:将这些差异平均,得到上下文向量 [1, 1, 1]。</li> </ul> <h4>2. 应用上下文向量</h4> <strong>步骤:</strong> <ul> <li><strong>潜在状态调整:</strong> 在实际任务中,将生成的上下文向量应用于模型的潜在状态。具体做法是将上下文向量加到模型的每一层的潜在状态上,确保模型在处理新的输入时,能够参考上下文向量提供的信息。</li> <li><strong>任务执行:</strong> 当模型接收到新的输入时,调整后的潜在状态会引导模型生成符合任务要求的输出。</li> </ul> <strong>示例</strong> <ul> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">应用向量</strong> 当我们遇到一个新句子,比如“不喜欢这个”(模型内部的潜在状态可能是 [1, 3, 2]),我们把这个句子输入模型,并应用之前生成的上下文向量 [1, 1, 1]。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">调整潜在状态</strong> 将潜在状态 [1, 3, 2] 和上下文向量 [1, 1, 1] 相加,得到新的潜在状态 [2, 4, 3]。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">生成结果</strong> 经过调整后的潜在状态,模型输出的句子就会更礼貌,比如“我们可以换个方式试试吗?”</li> </ul> <h5><strong>举例解释</strong></h5> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">为了更好地理解上下文向量的工作原理,我们可以通过一个例子来解释。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>例子:将负面评论转换为正面评论</strong></p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">传统的方法是给模型提供一些示例,例如:</p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">“这本书太糟糕了。” → “这本书非常精彩。”</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">“我讨厌这个产品。” → “我喜欢这个产品。”</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">模型通过这些示例学习如何将负面评论转换为正面评论。但是,这样的方法有几个缺点:</p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">需要在每次使用时提供这些示例,增加了计算量。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">模型的表现可能会因为示例的选择而不稳定。</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">而上下文向量的方法则不同:</p> <ol data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">生成上下文向量</strong>:首先,模型通过这些示例生成一个上下文向量,这个向量包含了如何将负面评论转换为正面评论的信息。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">应用上下文向量</strong>:在处理新的负面评论时,模型直接使用这个上下文向量来调整其状态,从而生成正面的回应。</li> </ol> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>工作示例</strong></p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">比如,我们要将“这道菜真难吃”转换为正面评论。使用上下文向量的方法,模型不需要再看到原来的示例,而是直接利用上下文向量生成新的评论:“这道菜非常美味。”</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>上下文向量的本质原理</strong></p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">为了更好地解释上下文向量的本质原理,我们需要理解其工作机制:</p> <ol data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">获取示例的潜在状态</strong>:首先,模型会通过前向传递(forward pass)处理每一个示例,得到示例在模型中的潜在状态。这些潜在状态是模型在处理示例时内部生成的高维向量,代表了示例的深层特征。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">计算上下文向量</strong>:接着,模型会计算这些潜在状态之间的差异,生成一个上下文向量。这个上下文向量捕捉了从输入到输出示例的转变方向和幅度。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">应用上下文向量</strong>:当处理新问题时,模型不再需要示例本身,而是将上下文向量应用到新问题的潜在状态上,通过调整这些潜在状态来生成符合期望的输出。</li> </ol> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">具体来说,上下文向量通过调整模型的内部状态,使得模型能够在不显式提供示例的情况下,生成与示例相似的结果。这种方法不仅提高了效率,还增强了模型的泛化能力。</p> <h5 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong>优势</strong></h5> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">更好地学习示例</strong>:上下文向量让模型更容易理解并遵循提供的示例。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">容易控制</strong>:可以通过调整向量的大小,方便地控制模型的输出。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">减少计算量</strong>:通过移除不必要的示例,显著减少了计算资源的消耗。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">高效</strong>:相比于传统方法,使用上下文向量更加节省时间和计算资源。</li> </ul> <h3 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验和结果</h3> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">为了验证ICV方法的有效性,研究者进行了多项实验,并将ICV与传统的上下文学习方法和微调方法进行了比较。以下是实验的详细过程和结果总结。</p> <h4 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><img class="aligncenter size-full wp-image-11318" src="https://img.xiaohu.ai/2024/07/Jietu20240714-211935@2x.jpg" alt="" width="2372" height="1166" />实验设置</h4> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">任务类型</strong></p> <ol data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">语言去毒</strong>:将有毒言论转化为中性或无害的言论。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">写作风格转换</strong>:如从非正式语言转化为正式语言。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">角色扮演</strong>:模仿特定角色的语言风格,如莎士比亚的语言。</li> </ol> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">比较方法</strong></p> <ol data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">传统上下文学习(ICL)</strong>:直接在提示中添加示例。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">LoRA微调(FT)</strong>:通过低秩适配进行模型微调。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">ICV方法</strong>:通过生成和应用上下文向量调整模型潜在状态。</li> </ol> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">模型</strong> 使用流行的大型语言模型,如LLaMA和Falcon进行实验。</p> <h3 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">1. 语言去毒</h3> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验数据</strong> 使用ParaDetox数据集,包含有毒评论及其对应的无毒改写。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验过程</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">使用5个示例对生成ICV。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">在670个查询样本上进行测试。</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">结果</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">毒性降低</strong>:ICV显著减少了生成内容的毒性,效果优于ICL和LoRA微调。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">语义相似性</strong>:ICV保持了较高的语义相似性,生成的句子与参考句子的相似度更高。</li> </ul> <table data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <thead data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">方法</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">毒性 (%)</th> <th>ROUGE-1</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">BERT得分</th> </tr> </thead> <tbody data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">无上下文</td> <td>79.84</td> <td>72.60</td> <td>93.29</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">传统上下文学习</td> <td>73.09</td> <td>73.58</td> <td>93.51</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">LoRA微调</td> <td>52.78</td> <td>61.35</td> <td>90.03</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b" data-immersive-translate-paragraph="1">ICV (λ = 0.1)</td> <td>34.77</td> <td>65.76</td> <td>92.88</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">ICV (无配对, λ = 0.1)</td> <td>35.56</td> <td>64.76</td> <td>91.27</td> </tr> </tbody> </table> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">ICV方法显著减少了生成内容的毒性,毒性从无上下文时的79.84%降低到34.77%,相比传统上下文学习(ICL)的73.09%和LoRA微调(FT)的52.78%效果更好。同时,ICV方法保持了较高的语义相似性,ROUGE-1得分为65.76,BERT得分为92.88,高于LoRA微调(FT)的61.35和90.03。</p> <h3 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">2. 写作风格转换</h3> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验数据</strong> 使用Grammarly的Yahoo Answers Formality Corpus数据集,包含非正式和正式句子的配对。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验过程</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">使用5个示例对生成ICV。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">在1332个测试样本上进行评估。</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">结果</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">形式提升</strong>:ICV在提升句子形式上表现出色,比ICL和LoRA微调更为有效。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">情感转换</strong>:ICV在情感转换任务中表现优异,能够将负面评论有效转化为正面评论。</li> </ul> <table data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <thead data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">方法</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">形式准确率 (%)</th> <th>ROUGE-1</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">BERT得分</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">情感转换准确率 (%)</th> <th>ROUGE-1</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">BERT得分</th> </tr> </thead> <tbody data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">无上下文</td> <td>17.54</td> <td>81.54</td> <td>92.61</td> <td>35.81</td> <td>78.85</td> <td>95.59</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">传统上下文学习</td> <td>32.96</td> <td>83.85</td> <td>93.61</td> <td>63.42</td> <td>73.86</td> <td>95.00</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">LoRA微调</td> <td>21.99</td> <td>80.13</td> <td>92.86</td> <td>65.92</td> <td>66.91</td> <td>93.89</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b" data-immersive-translate-paragraph="1">ICV (λ = 0.1)</td> <td>48.30</td> <td>80.23</td> <td>92.81</td> <td>75.28</td> <td>68.27</td> <td>94.32</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">ICV (无配对, λ = 0.1)</td> <td>36.30</td> <td>78.17</td> <td>91.81</td> <td>67.13</td> <td>65.10</td> <td>93.42</td> </tr> </tbody> </table> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">ICV在提升句子形式和情感转换任务中表现出色。在形式转换任务中,ICV的准确率从无上下文时的17.54%提升到48.30%,优于传统上下文学习(ICL)的32.96%和LoRA微调(FT)的21.99%。在情感转换任务中,ICV的准确率从无上下文时的35.81%提升到75.28%,也显著优于传统上下文学习(ICL)的63.42%和LoRA微调(FT)的65.92%。</p> <h3 data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">3. 角色扮演</h3> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验数据</strong> 使用莎士比亚的《罗密欧与朱丽叶》进行评估,比较模型在模仿莎士比亚语言风格方面的表现。</p> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">实验过程</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">使用10个示例对生成ICV。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">在585个测试样本上进行评估。</li> </ul> <p data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">结果</strong></p> <ul data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">风格匹配</strong>:ICV在模仿莎士比亚语言风格方面表现优异,生成的句子更符合莎士比亚的语言风格。</li> <li data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"><strong data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">任务灵活性</strong>:通过向量算术,ICV能够灵活地组合不同的任务,例如同时提升安全性和减少礼貌性。</li> </ul> <table data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <thead data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">方法</th> <th data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">获胜率 (%)</th> </tr> </thead> <tbody data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">传统上下文学习</td> <td>24.3</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b">LoRA微调</td> <td>25.7</td> </tr> <tr data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b"> <td data-immersive-translate-walked="1c0e52b6-972c-4136-8dd6-aa85a7472c7b" data-immersive-translate-paragraph="1">ICV (λ = 0.1)</td> <td>50.0</td> </tr> </tbody> </table> ICV在模仿莎士比亚语言风格方面表现优异,生成的句子更符合目标风格。ICV的获胜率达到50.0%,显著高于传统上下文学习(ICL)的24.3%和LoRA微调(FT)的25.7%。此外,通过向量算术,ICV能够灵活地组合和应用不同任务,提高了模型的适应性和灵活性。 <h5>结论</h5> 进一步分析表明,随着示例数量的增加,ICV的有效性也在增加,因为它不受上下文长度限制。这允许包含更多示例,进一步提高性能。该方法在应用于Transformer模型的所有层时效果最佳,而不是单个层。此层特定的消融研究证实,ICV在整个模型中最大化了性能,凸显了其对学习的全面影响。 <p data-immersive-translate-walked="99c60c18-1298-4750-9128-5d23c58dd9b2">在实验中,ICV方法应用于各种LLM,包括LLaMA-7B、LLaMA-13B、Falcon-7B和Vicuna-7B。结果一致表明,ICV不仅在单个任务上提高了性能,还通过简单的向量算术运算增强了模型处理多任务的能力。这展示了ICV方法在适应LLM多种应用方面的多功能性和鲁棒性。</p> <p data-immersive-translate-walked="99c60c18-1298-4750-9128-5d23c58dd9b2">查看 <strong data-immersive-translate-walked="99c60c18-1298-4750-9128-5d23c58dd9b2"><a href="https://arxiv.org/abs/2311.06668" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="99c60c18-1298-4750-9128-5d23c58dd9b2">论文</a> 和 <a href="https://github.com/shengliu66/ICV" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="99c60c18-1298-4750-9128-5d23c58dd9b2">GitHub</a></strong></p>






{kind=link}








