Stability AI 开源其Stable Diffusion 3 Medium 模型,该模型是其迄今为止最先进的文本到图像开放模型,包含 20 亿个参数。
Stable Diffusion 3 Medium 模型的尺寸较小,这使得它能够在消费级 PC 和笔记本电脑以及企业级 GPU 上良好运行。同时,它的这种尺寸特点也使其有潜力成为文本到图像模型的下一个标准。
主要特性与功能:
- 图像质量改进:该模型在图像质量上有显著提升,能够生成更高质量、更细腻的图像。
- 复杂提示理解:改进了对复杂文本提示的理解能力,能够更准确地将文本描述转换为图像。
- 资源效率:在资源使用方面进行了优化,能够在更少的计算资源下实现较高的性能。


模型介绍:
- 模型名称:Stable Diffusion 3 Medium
- 模型类型:多模态扩散变压器 (MMDiT) 文本到图像生成模型
- 技术详情:使用三个固定的预训练文本编码器(OpenCLIP-ViT/G、CLIP-ViT/L 和 T5-xxl)
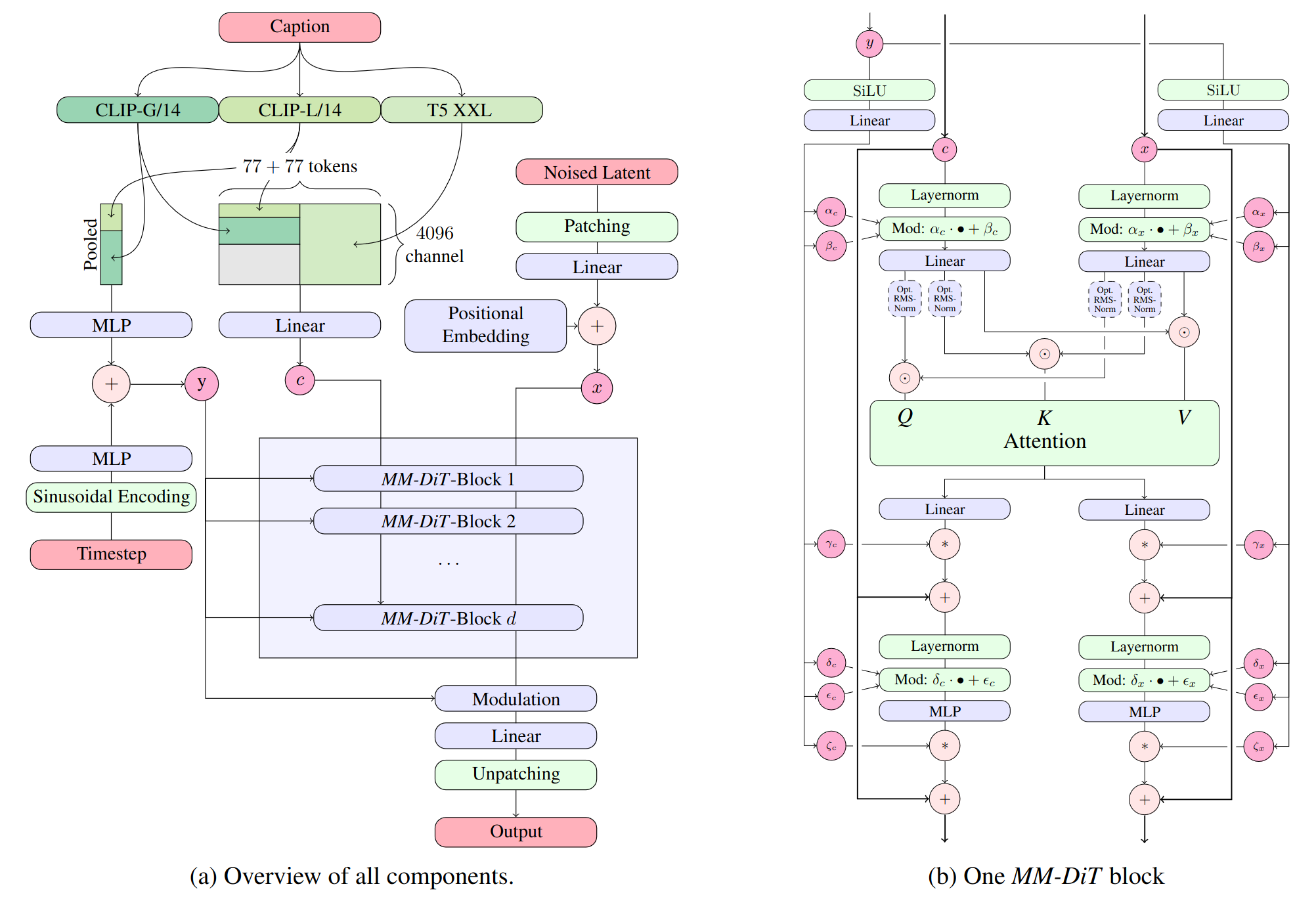

- 预训练数据:模型在 10 亿张图像上进行了预训练,这些图像包括合成数据和过滤的公开数据。
- 精调数据:精调数据包括 3000 万高质量美学图像和 300 万偏好数据图像,重点关注特定视觉内容和风格。
要尝试 Stable Diffusion 3 模型,可以使用 Stability Platform 上的 API ,在 Stable Artisan 上注册免费的三天试用,并通过 Discord 尝试 Stable Artisan。


模型下载:https://huggingface.co/stabilityai/stable-diffusion-3-medium
- 技术报告:技术报告链接
- GitHub 资源: