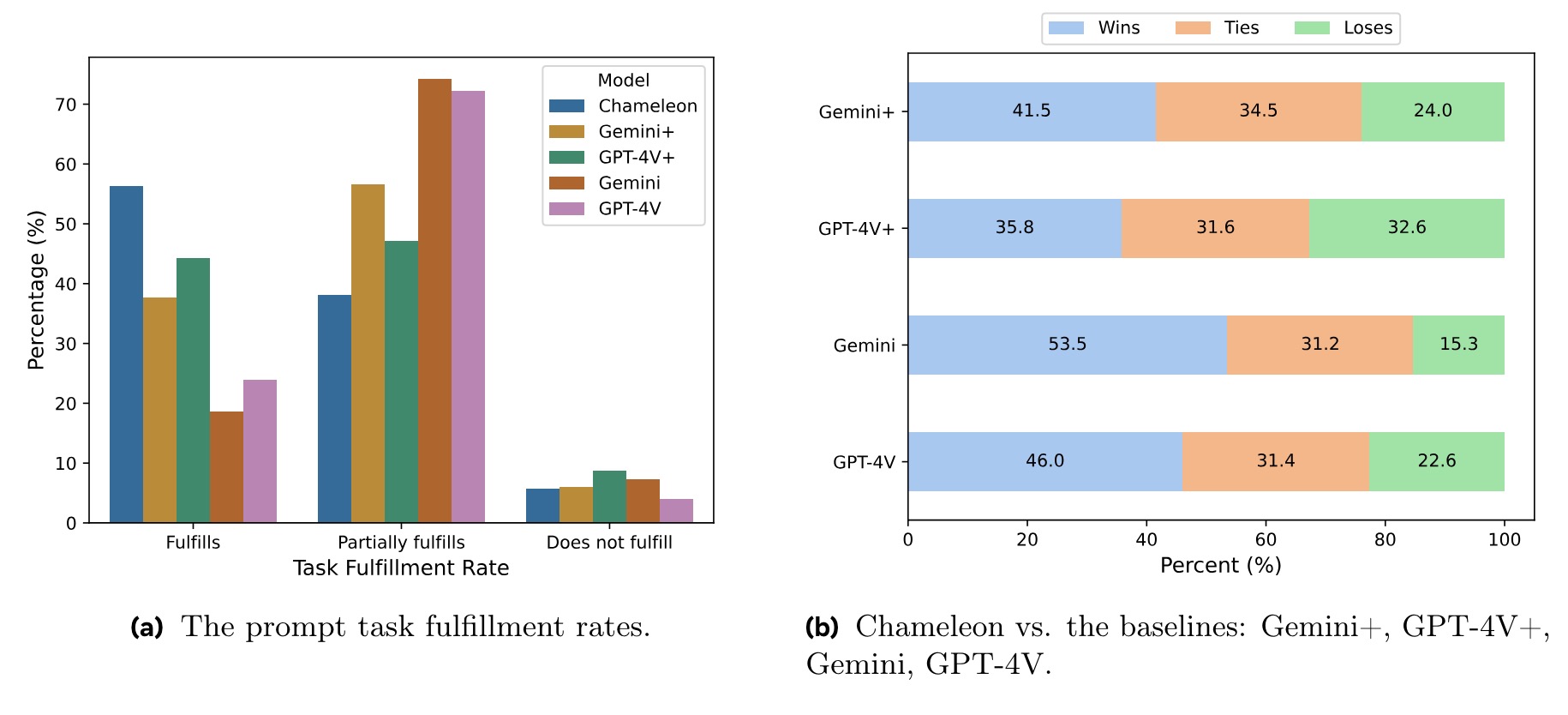
Chameleon 是由Meta的FAIR团队开发的一系列早期融合的基于令牌的混合模态模型。它可以同时处理图像和文本,并且可以理解和生成这两种类型的数据。换句话说,它可以阅读文字和图片,也可以创作新的文字和图片。Chameleon 可以在处理过程中无缝地在不同的数据类型之间切换。这意味着它可以在生成一段文字后,接着生成一张相关的图片,或者在描述一张图片的同时生成相关的文字。
它通过把图像和文字分解成小块(令牌),然后在一个统一的系统(transformer架构)中处理这些小块,实现了在图像和文字之间的无缝转换和理解。这使得它在许多需要同时处理图像和文字的应用中表现非常出色。

主要功能
1. 多模态理解与生成:Chameleon 能够理解和生成包含图像和文本的复杂内容。它可以在图像和文本之间无缝切换,实现多种任务的高效处理和生成。


2. 图像描述:能够根据输入的图像生成准确的描述性文字。这在自动生成图像标签、图像内容描述和辅助盲人用户的应用中非常有用。
- 例子:给模型一张风景图片,它可以生成描述这张图片的详细文字,如“图片中有一片美丽的湖泊,周围环绕着高山,天空中有几朵白云。”
3. 文本生成:可以生成连贯且有意义的文本内容。它可以扩展给定的文本开头,生成完整的段落或文章。
- 例子:给模型一个故事的开头,它可以续写整个故事,保持逻辑连贯和语言一致。
4. 视觉问答: 能够回答关于图像的问题。它可以根据图像内容提供准确的回答。
- 例子:给模型一张动物园的图片,并问“这张图片中有哪些动物?”模型可以回答“图片中有一只大象和一只长颈鹿。”


5. 图像生成: 能够根据文本描述生成图像。这对于需要根据文本生成视觉内容的应用非常有用,如广告创作和艺术生成。
- 例子:给模型一个描述,如“一个穿着红色连衣裙的小女孩在草地上奔跑”,模型可以生成对应的图像。
6. 混合模态生成:Chameleon 能够生成包含交替出现的图像和文本的长格式文档。这在创建多媒体内容、教育材料和复杂的报告时特别有用。
- 例子:生成一篇包含多个章节和插图的旅行日志,每个章节描述不同的景点,并配有相应的照片。


7. 常识推理和阅读理解:Chameleon 具备强大的常识推理能力和阅读理解能力,可以在阅读文本后回答相关问题,进行常识性推理。
- 例子:阅读一段关于历史事件的文字,并回答“这个事件发生在哪一年?”
8. 数据查询与分析:Chameleon 可以从复杂的数据集或文本中提取有用的信息,进行数据查询与分析。
- 例子:给模型一份财务报告,要求它总结关键的财务指标和趋势。
技术原理和创新
Chameleon 通过统一的令牌表示和早期融合的 Transformer 架构,实现了对图像和文本的无缝处理和生成。通过引入查询-键规范化和修订的层规范化技术,模型在大规模数据上的训练过程保持了稳定性。自回归生成方法使得模型能够生成连续的图像和文本序列,适用于各种复杂的多模态任务。
Chameleon 的技术原理包括以下几个关键点:
- 早期融合架构 (Early-Fusion Architecture):
- Chameleon 使用早期融合的方法,将图像和文本数据从一开始就结合在一起进行处理。具体来说,它将图像量化为离散的令牌,类似于将文本拆分为单词,然后使用相同的 transformer 架构来处理这些图像和文本令牌序列。
- 统一的令牌表示:
- Chameleon 将图像和文本都表示为统一的令牌(tokens)。图像被转换为离散的像素块令牌,文本被分解为单词或子词令牌。这样,图像和文本可以在同一个模型中进行统一处理,无需单独的图像或文本编码器。
- Transformer 架构:
- Chameleon 使用 Transformer 架构,这是一种广泛用于自然语言处理和计算机视觉的深度学习模型。Transformer 模型通过自注意力机制来处理输入数据的序列,无论这些序列是文本还是图像令牌。
- 查询-键规范化 (Query-Key Normalization, QK-Norm):
- 为了在混合模态环境中保持训练稳定,Chameleon 引入了查询-键规范化。这种技术通过对 Transformer 中的查询和键向量进行规范化,控制输入到软最大化(softmax)操作的值的增长,从而防止训练过程中的不稳定。
- 层规范化与 dropout (Layer Normalization and Dropout):
- 在 Transformer 层中,Chameleon 使用修订的层规范化和 dropout 技术来进一步稳定训练过程。层规范化有助于控制激活值的范围,而 dropout 则有助于防止过拟合。
- 自回归生成 (Autoregressive Generation):
- Chameleon 采用自回归生成方法,即在生成每个新的令牌时,使用之前已经生成的令牌作为输入。这种方法适用于生成连续的文本和图像序列。
- 数据预处理与训练:
- 在预训练阶段,Chameleon 使用了大规模的文本和图像数据集进行训练。数据包括来自公共数据源的文本和图像对,并进行了一系列的数据增强和过滤操作,以确保模型能够学习到高质量的表示。
- 在微调阶段,模型在精心挑选的高质量数据集上进行了监督微调,进一步提升了模型在特定任务上的表现。
评估结果
Chameleon 模型在多个任务上进行了广泛的评估,包括视觉问答、图像描述、文本生成和图像生成任务。
- Chameleon在一系列任务中进行了评估,包括视觉问答、图像描述、文本生成、图像生成和长格式混合模态生成。
- Chameleon展示了广泛的通用能力,包括在图像描述任务中达到最先进的性能,在仅文本任务中超过了Llama-2,并与Mixtral 8x7B和Gemini-Pro等模型竞争,在单一模型中执行复杂的图像生成任务。
- 在人类评判的新长格式混合模态生成评估中,Chameleon的表现匹配或超过了包括Gemini Pro和GPT-4V在内的更大模型。


以下是一些具体的评估结果:
1. 图像描述(Image Captioning)
- 数据集:MS-COCO 和 Flickr30k
- 评估指标:CIDEr 分数
- 结果:
- 在 MS-COCO 数据集上,Chameleon-34B 模型在2-shot设置下获得了120.2的CIDEr分数,超过了Flamingo-80B(32-shot设置,113.8分)和IDEFICS-80B(32-shot设置,116.6分)。
- 在 Flickr30k 数据集上,Chameleon-34B 模型在2-shot设置下获得了74.7的CIDEr分数,与Flamingo-80B和IDEFICS-80B的32-shot设置下的分数相当。
2. 视觉问答(Visual Question Answering)
- 数据集:VQA-v2
- 评估指标:准确率
- 结果:
- Chameleon-34B 在2-shot设置下的准确率为66.0%,接近Flamingo-80B和IDEFICS-80B的32-shot设置下的性能。
- 在微调后的多任务模型(Chameleon-34B-MultiTask)上,准确率达到69.6%,接近IDEFICS-80B-Instruct和Gemini Pro,但稍逊于Flamingo-80B-FT、GPT-4V和Gemini Ultra等较大的模型。
3. 文本生成(Text Generation)
- 评估任务:常识推理、阅读理解、数学问题和世界知识
- 评估指标:各任务的准确率
- 结果:
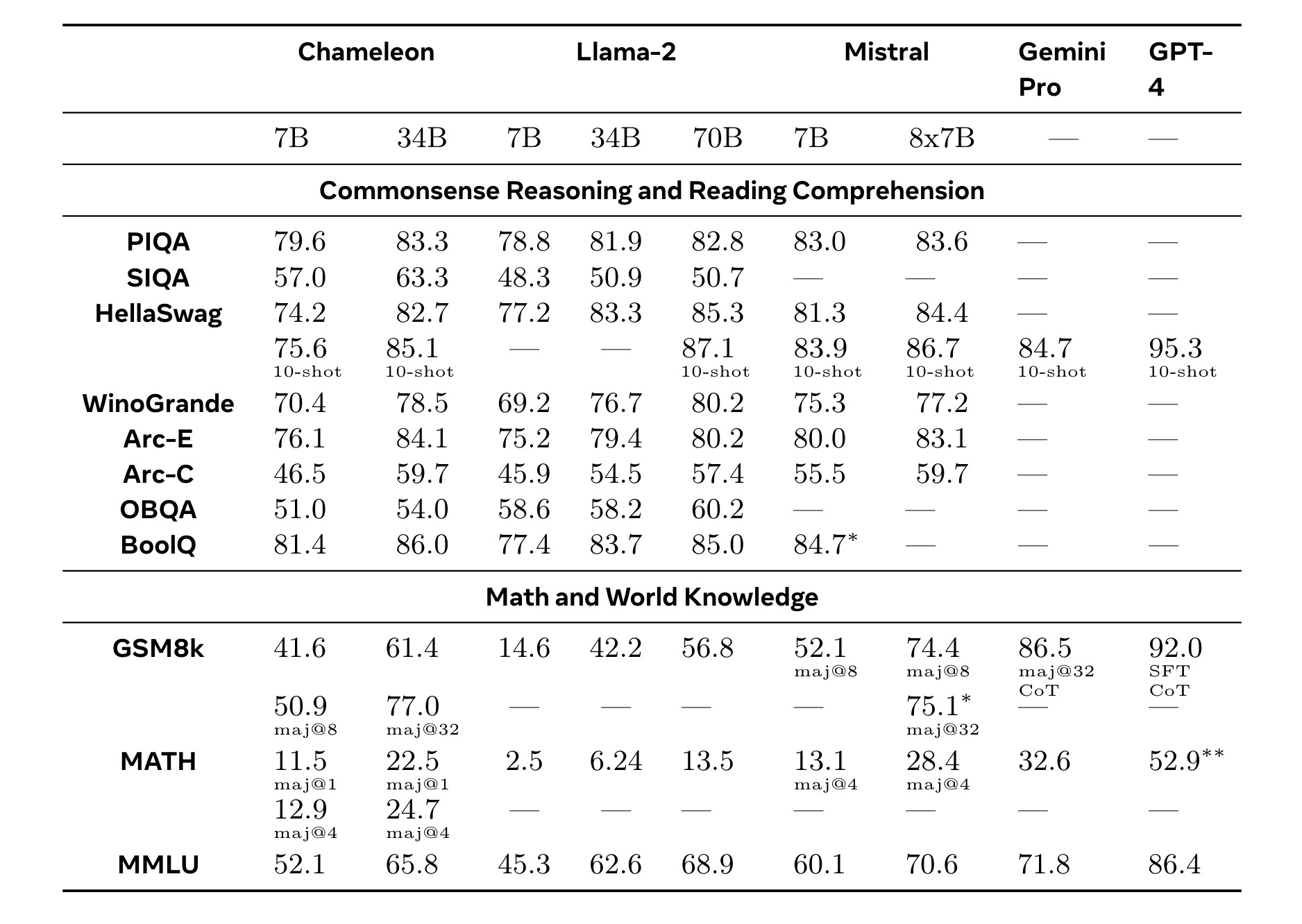
- 在常识推理和阅读理解任务(如PIQA、SIQA、HellaSwag、WinoGrande、ARC-Easy、ARC-Challenge、OpenBookQA和BoolQ)上,Chameleon-34B 的表现优于相应的Llama-2模型,并在5/8任务上超过了Llama-2 70B。
- 在数学任务(如GSM8k和MATH)上,Chameleon-34B 在8-shot设置下的表现优于Llama-2 70B,并接近Mixtral 8x7B的性能。

4. 混合模态生成(Mixed-Modal Generation)
- 任务:生成包含交替出现的图像和文本的长格式文档
- 评估方式:人类评估和自动评估
- 结果:
- 在人类评估中,Chameleon-34B的响应被认为比Gemini Pro和GPT-4V的响应更好,分别在60.4%和51.6%的对比中获得了偏好。
- Chameleon 在处理混合模态内容时表现出色,特别是在需要生成和理解包含图像和文本的复杂任务中。