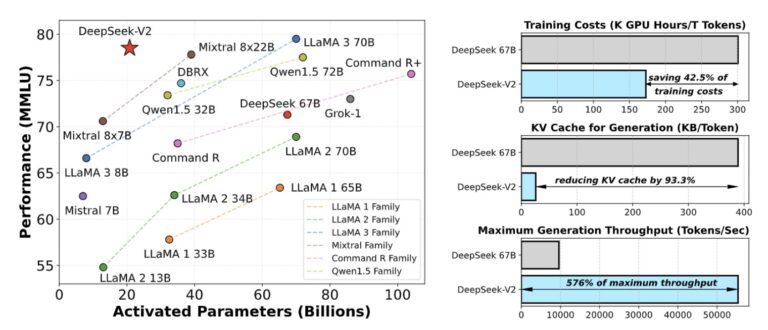
DeepSeek-V2,一个专家混合(MoE)语言模型,其特点是经济高效的训练和推理。它包含 2360 亿个总参数,其中每个token激活了 21 亿个参数。与 DeepSeek 67B 相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5%的训练成本,将 KV 缓存减少了 93.3%,并将最大生成吞吐量提高了 5.76 倍。
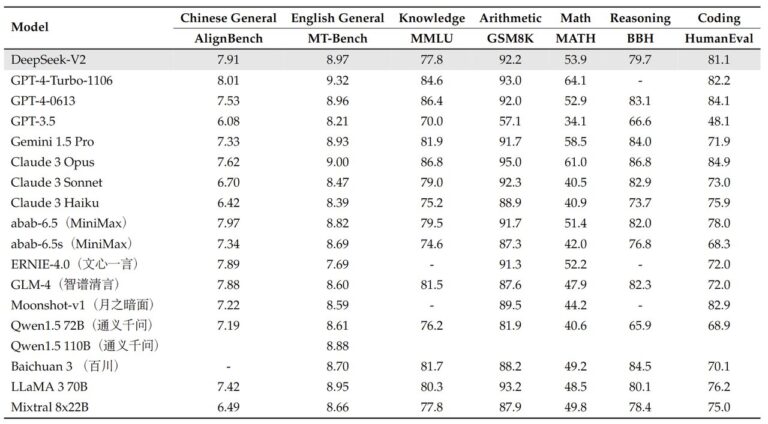
在 AlignBench 中排名前三,超越 GPT-4,接近 GPT-4-Turbo。 在 MT-Bench 中排名顶尖,与 LLaMA3-70B 不相上下,并且胜过 Mixtral 8x22B。 专注于数学、编码和推理。
DeepSeek-V2 完全开源,可免费用于商业用途。

🧮 236B参数,其中21B在生成过程中被激活
👨🏫 160位专家,其中有6位在生成中活跃
🚀 在英文基准测试中与 Mixtral 8x22B 匹配
🪟 128k上下文
🔠 在 8.1 万亿标记上训练
🌱 用于在 bf16 8x 80GB GPU 上进行推理
❌ 接受英语和中文语言训练

-
模型概述: DeepSeek-V2-Chat是一个先进的Mixture-of-Experts(MoE)语言模型,具有高效的训练和推理能力,总参数量为2360亿,每个token激活21亿参数。与之前的版本相比,该模型在性能方面显著提升,并降低了训练成本、KV缓存需求以及生成开销。
-
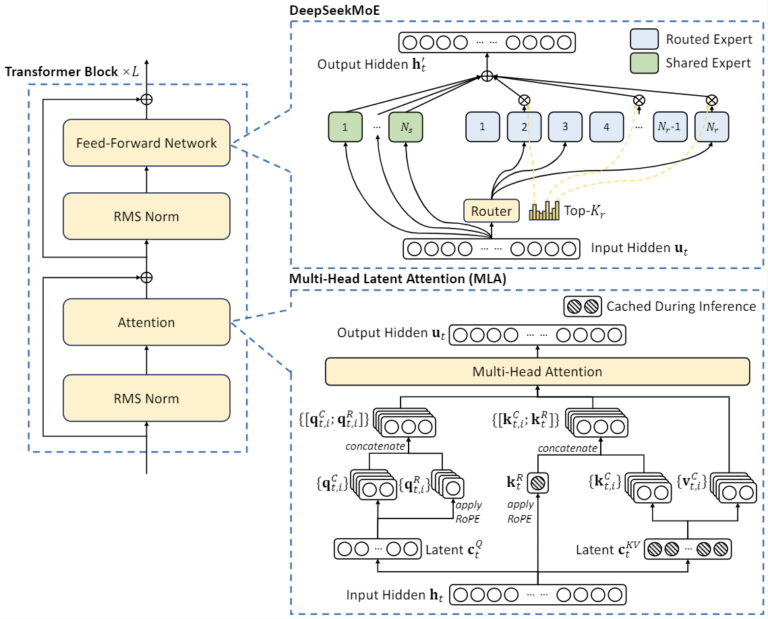
总体架构:
- Mixture-of-Experts(MoE)结构: DeepSeek-V2-Chat基于混合专家的设计,允许每个输入token仅激活部分参数,大幅降低内存使用并提高计算效率。
- 参数规模: 总参数量达到2360亿,但每个token激活21亿参数,从而实现性能与资源利用的平衡。
- 长上下文窗口: 支持长达128K的上下文窗口。
-
性能优势:
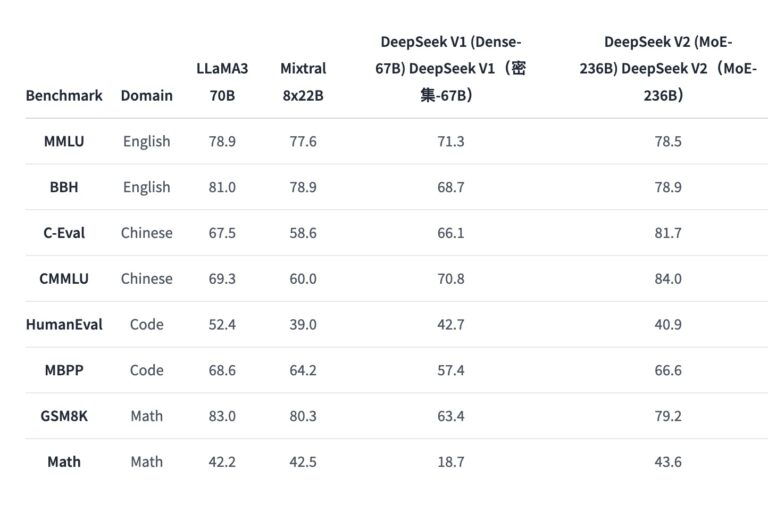
- 与Dense模型DeepSeek 67B相比,DeepSeek-V2在多项标准基准测试中表现更强。
- 减少训练成本42.5%,KV缓存降低93.3%,并将最大生成吞吐量提高5.76倍。
-
数据训练: DeepSeek-V2在包含8.1万亿token的多样化高质量语料库上进行预训练,并通过监督微调(SFT)和强化学习(RL)来充分发挥模型潜力。

评估结果
-
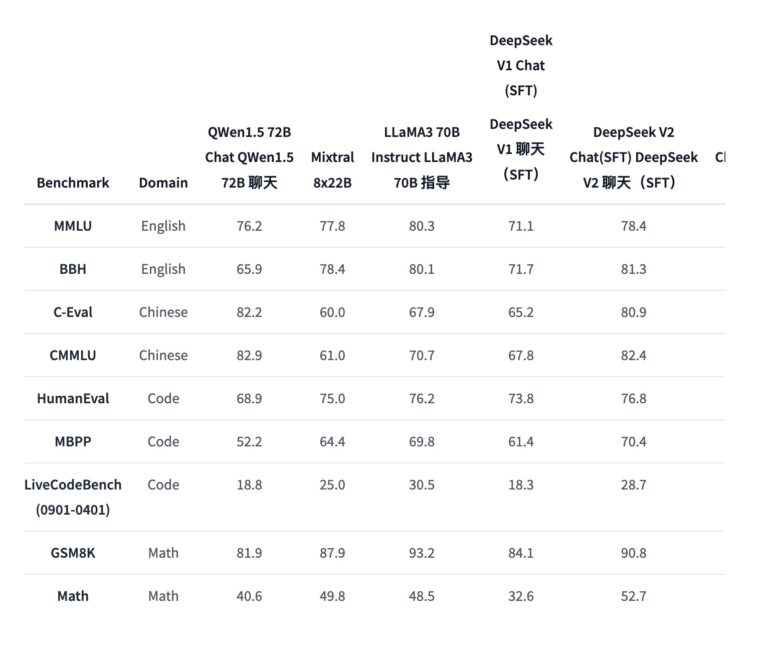
标准基准测试:
- MMLU(英语): 用于多任务推理和知识评估。DeepSeek-V2在该基准上达到了78.5分。
- BBH(英语): 包含一系列复杂的推理任务。DeepSeek-V2的成绩为78.9分。
- C-Eval(中文): 中国大型学术基准。DeepSeek-V2在这项测试中得分81.7。
- CMMLU(中文): 中文多任务推理基准,DeepSeek-V2取得84.0分。
-
代码和数学基准:
- HumanEval(代码): 用于评估编程能力,DeepSeek-V2得分为40.9。
- MBPP(代码): 以Python编程任务为主,模型得分66.6。
- GSM8K(数学): 小学生级别的数学题目,DeepSeek-V2得分79.2。
- Math(数学): 包含各类数学题目,DeepSeek-V2达到了43.6的分数。
-
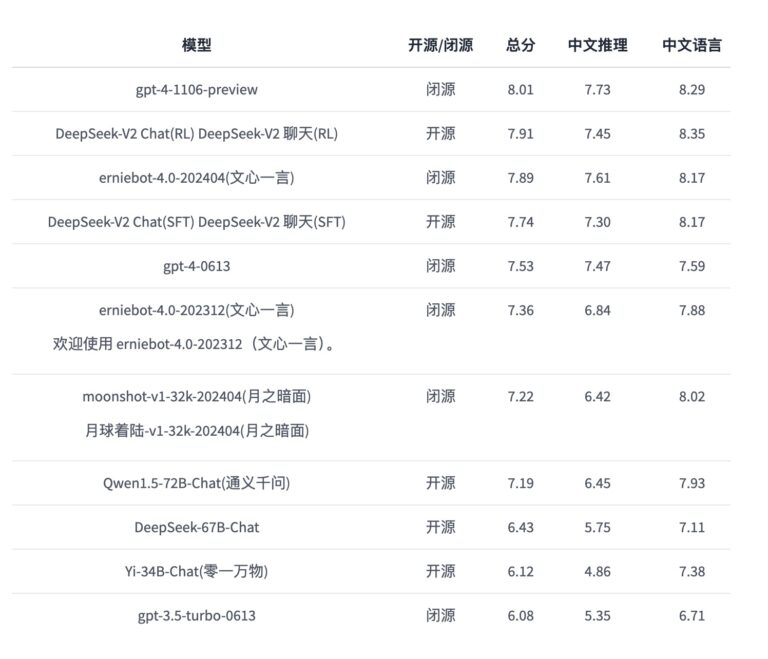
对话生成基准:
- AlpacaEval 2.0和MTBench(英语): 这两项评估了DeepSeek-V2-Chat-RL在英语对话生成中的竞争力。
- AlignBench(中文): 专门用于评估中文对话生成能力。在此基准上,DeepSeek-V2-Chat-RL取得了7.91的高分。
-
长上下文窗口评估:
- Needle in a Haystack(NIAH): 评估了模型在长达128K的上下文窗口中的性能,DeepSeek-V2在各长度测试中表现稳定。
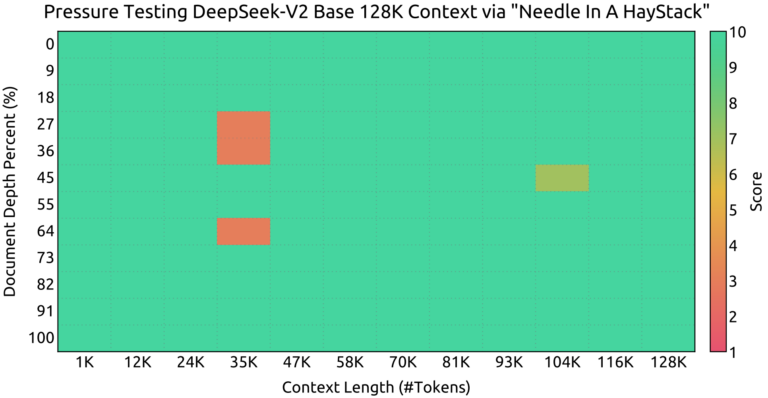
- Needle in a Haystack(NIAH): 评估了模型在长达128K的上下文窗口中的性能,DeepSeek-V2在各长度测试中表现稳定。
-
代码基准:
- LiveCodeBench: 专注于实时编码挑战。DeepSeek-V2的Pass@1得分高于许多其他模型,证明其在实时编码任务中的有效性。
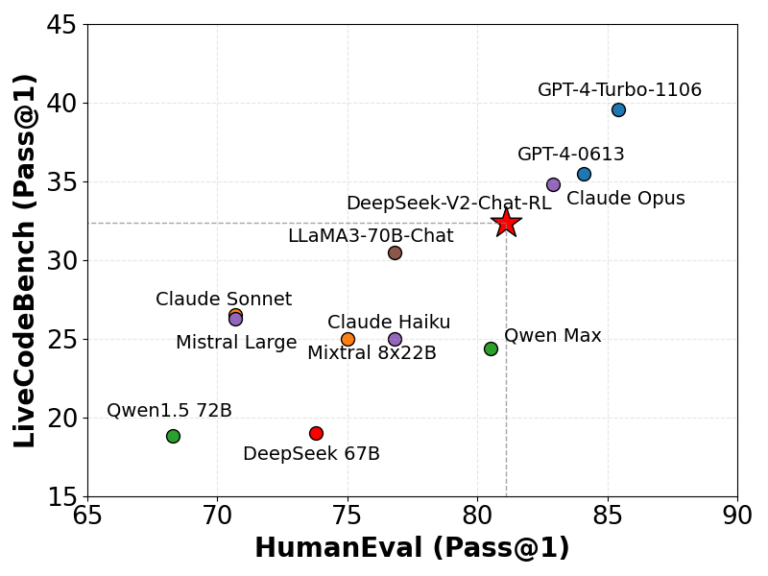
- LiveCodeBench: 专注于实时编码挑战。DeepSeek-V2的Pass@1得分高于许多其他模型,证明其在实时编码任务中的有效性。





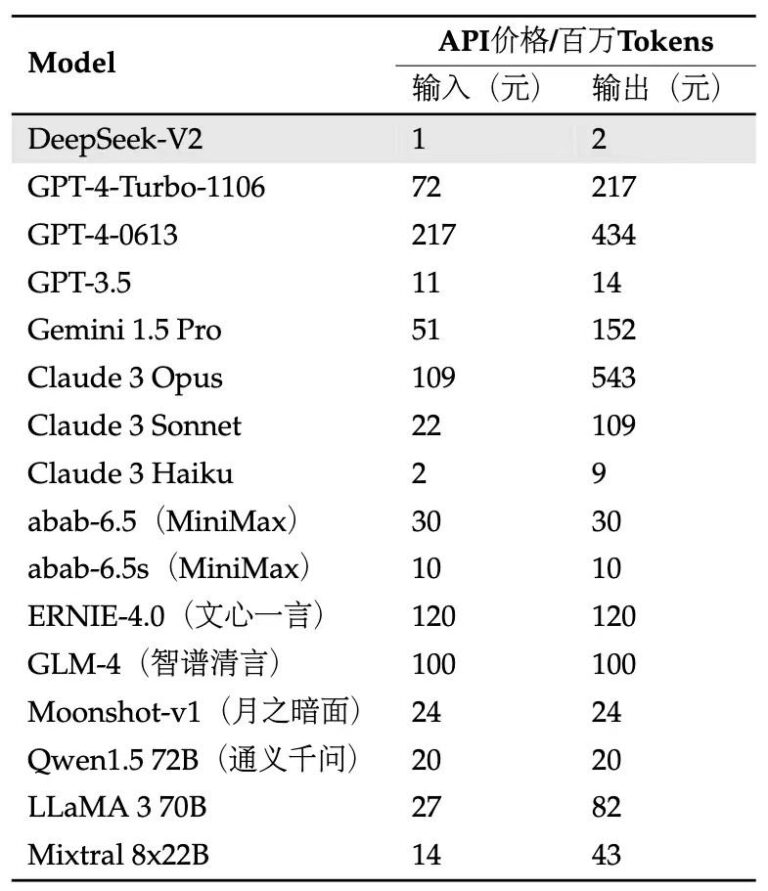
价格很美丽

模型下载:
| DeepSeek-V2 | 128k | 🤗 HuggingFace |
| DeepSeek-V2-Chat(RL) | 128k | 🤗 HuggingFace |
Huggingface:https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat