DrEureka 利用大语言模型(LLMs)自动化从仿真环境到真实世界的技术转移。这个项目解决了一个常见问题:传统上,将机器人在仿真环境中学到的技能转移到现实世界中,需要大量的人工设计和调整,这个过程既耗时又耗力。
DrEureka 的主要创新点是自动生成奖励函数和调整仿真环境中的物理参数,这些都是帮助机器人技能顺利迁移到真实环境中的关键步骤。通过这种方式,DrEureka 能够在没有人为干预的情况下,完成从仿真到现实的转换。
也就是可以帮助机器人更好地从电脑模拟训练中学到的技能自动转移到真实世界当中。
它主要通过两种方式工作:
- 自动生成奖励函数:DrEureka 利用大语言模型(LLMs)自动化生成奖励函数,这是控制和指导机器人学习特定任务的关键。自动生成的奖励函数能够根据任务的需求调整,使机器人能更有效地学习所需的技能。
就像电子游戏中的得分系统,DrEureka 可以自动生成奖励规则,这些规则告诉机器人在模拟训练中哪些行为是好的,应该学习。 - 自动调整模拟环境:DrEureka 能自动配置仿真环境中的域随机化参数。域随机化是一种技术,通过在仿真训练中引入物理参数的变化(如摩擦力和重力的随机调整),增强机器人在现实世界中的适应性和鲁棒性。
也就是DrEureka 能自动调整模拟环境的设置,比如地面的滑动程度或重力大小,这样机器人学到的技能就能更好地适应现实世界的各种情况。
实际应用中,DrEureka 在处理复杂任务(如四足动物的行走和灵巧操作)时表现出色,还能解决新的挑战性任务,例如让机器人在瑜伽球上行走和保持平衡。


这项技术的好处是减少了人们手动调整和设计这些复杂设置的工作,让机器人的训练过程更快、更有效。
技术方法
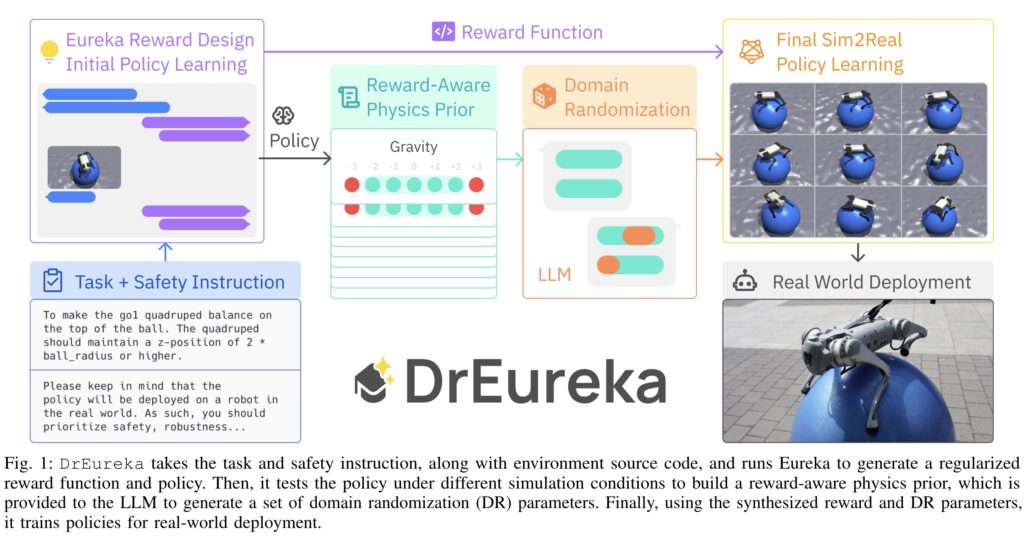

- 利用大语言模型(LLMs)生成奖励函数:
- DrEureka 使用先进的语言模型(如GPT-4)来自动化生成奖励函数。这些奖励函数是仿真训练中用来指导机器人行为的规则,它们定义了什么样的行为是好的,应该被机器人学习。
- 这一步骤消除了传统上需要人工设计和调整奖励函数的繁琐过程,实现了自动化生成。
- 域随机化(Domain Randomization, DR):
- 域随机化是一种技术,通过在仿真训练中引入物理参数(如摩擦力、重力等)的随机变化,来增强机器人在真实世界中的适应性和鲁棒性。
- DrEureka 自动配置这些参数,以确保机器人在仿真训练中面对的情况与现实世界尽可能相似,从而提高其应对真实环境的能力。
- 安全指导和反馈机制:
- 为确保生成的奖励函数和域随机化参数不仅有效,而且安全,DrEureka 引入了安全指导机制。这意味着在生成奖励函数时,会考虑到机器人操作的安全性,避免可能导致危险行为的奖励设置。
- 此外,DrEureka 通过模拟不同的物理条件来测试策略,生成所谓的“奖励感知物理先验”,这帮助进一步细化域随机化参数。
- 反馈循环和迭代优化:
- DrEureka 项目不仅在初始阶段使用语言模型生成策略,还在后续的测试和应用中不断收集反馈,优化奖励函数和域随机化设置。
- 这个过程中,系统能够学习哪些设置最有效,并据此调整,以提高最终部署在真实环境中的性能。
实验应用
DrEureka 在实验和应用方面展示了其独特优势和多样性,主要包括以下几个方面:
1. 复杂任务的应用示例
- 四足动物行走:DrEureka 在四足动物行走任务中被测试,这是机器人动力学和平衡控制的一个典型挑战。通过自动生成的奖励函数和调整好的仿真参数,DrEureka 训练出的机器人在现实世界的多种地形上都能稳定行走,显示出高度的适应性和鲁棒性。
- 灵巧手操作:在手部灵巧操作任务中,DrEureka 显示了如何控制机器人手去进行精确操作,如旋转一个立方体。这项技术在仿真中得到了训练和优化,并成功转移到了真实的操作环境中。
2. 新颖和创新任务
- 在瑜伽球上行走:DrEureka 的一个创新应用是让四足机器人在瑜伽球上保持平衡并行走。这个任务展示了该技术在处理高度不确定和动态变化的环境中的能力。这种任务在传统方法中很难实现,因为它要求机器人在极不稳定的表面上保持平衡,而这正是DrEureka 所擅长的。
3. 实验验证和优化
- 域随机化的优化:DrEureka 在多个实验中展示了如何通过自动调整仿真环境的物理参数(如摩擦力和重力)来优化域随机化策略。这确保了机器人在仿真训练中学到的技能能够有效转移到复杂多变的真实世界环境中。
- 安全和效率的提升:在所有实验中,DrEureka 都强调了安全性的重要性,通过在生成奖励函数时加入安全指导,确保了机器人操作的安全性。同时,自动化的流程显著提高了实验的效率。
4. 广泛的适用性
- DrEureka 的技术不仅适用于具体的机器人任务,还能广泛应用于任何需要仿真到现实转换的场景。这包括自动驾驶汽车的测试、工业机械手的精准操作等领域。