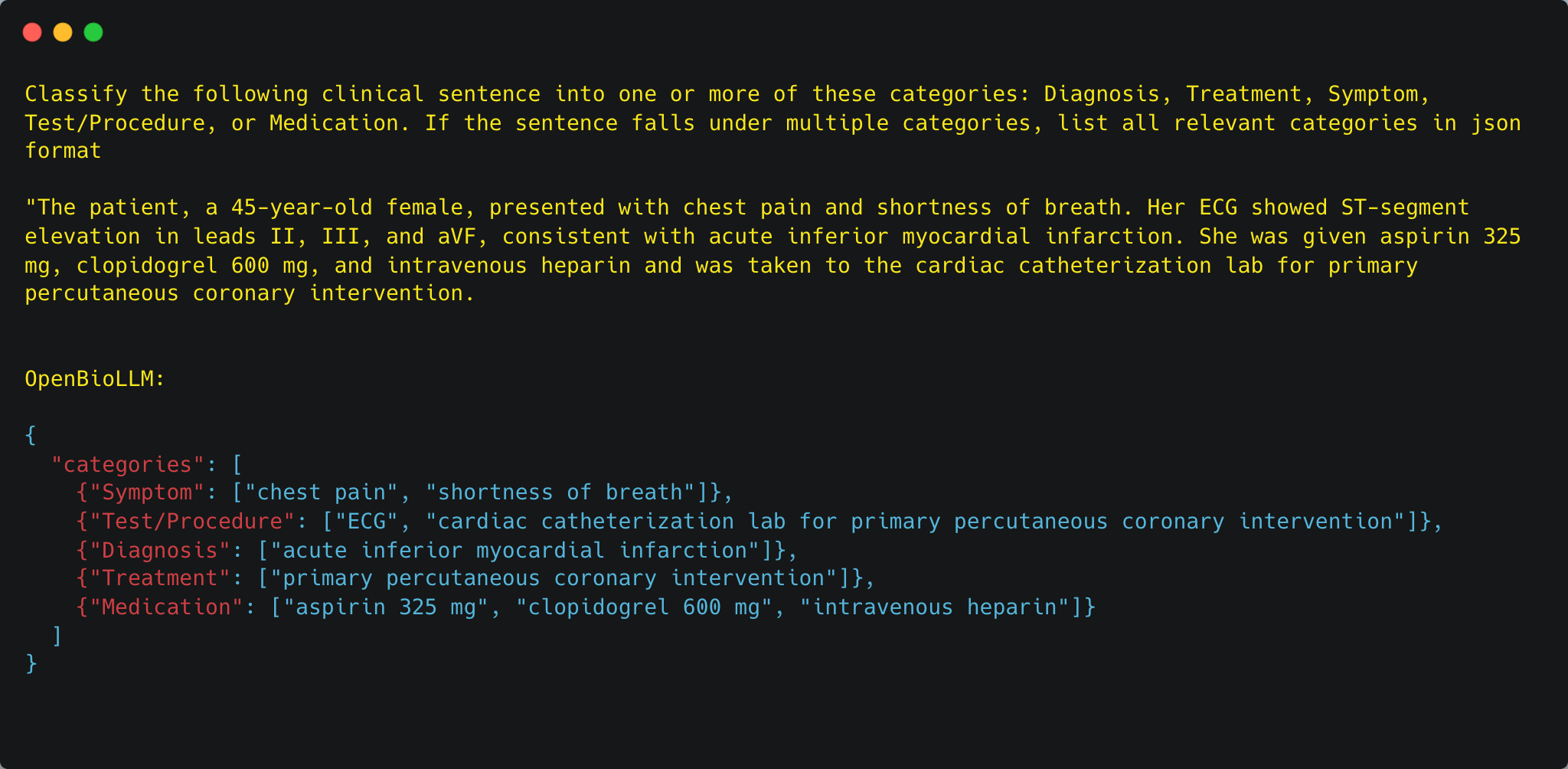
OpenBioLLM-8B 是一个为生物医学领域专门设计的高级开源语言模型,该模型由 Saama AI 实验室开发。
OpenBioLLM-8B 模型是基于 Meta-Llama-3-8B 的架构开发,针对生物医学领域的独特需求,OpenBioLLM-8B 在大量高质量的生物医学数据上进行了微调。这使得模型能够更准确地理解和生成与医学和生命科学相关的文本。
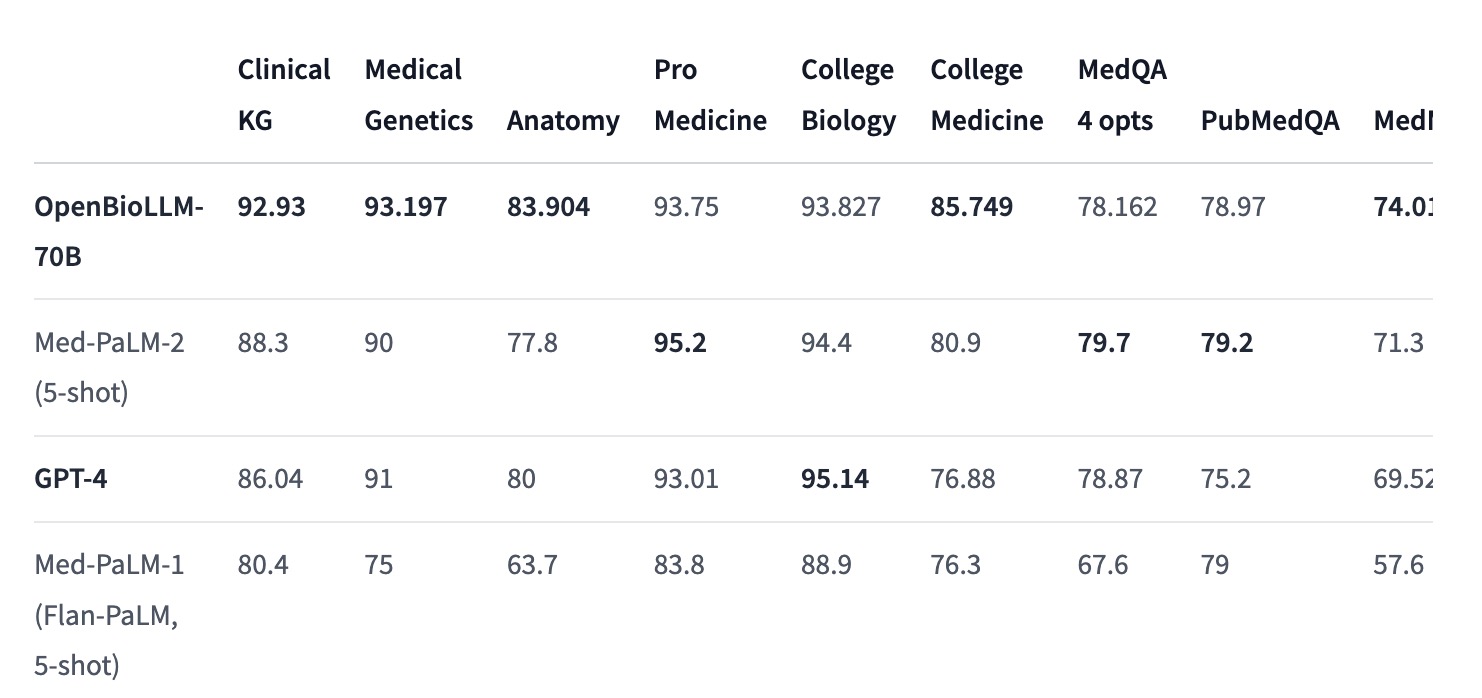
- OpenBioLLM-70B 在 9 个不同的生物医学数据集上的表现优于如 GPT-3.5 和 Meditron-70B 等更大模型,尽管参数数量较少。
- 在平均得分方面,OpenBioLLM-8B 达到了 72.50%,这反映了其在医学领域特有任务上的高效能力。
-
生物领域专用数据微调:
- 高质量生物医学数据:OpenBioLLM-8B 在大量精选的高质量生物医学数据上进行了微调,这些数据涵盖了广泛的医学和生命科学主题。这种精细的数据选择帮助模型学习和理解复杂的医学术语和概念,使其能够以高精度生成和理解与医学相关的文本。
-
训练技术的优化:
- 直接偏好优化(DPO):采用了直接偏好优化策略,这是一种利用用户偏好来指导语言模型训练的方法,通过这种策略,模型能够更好地根据实际应用场景调整其输出,以符合特定任务的需求。
- 数据集的策略使用:利用特定的排名数据集和自定义的医学指导数据集进行微调,这些数据集包含了与医学相关的高质量交互,进一步增强了模型在实际医学环境中的应用性。

训练方法
-
基于强大基础模型的微调:
- OpenBioLLM-8B 首先基于 Meta-Llama-3-8B 进行预训练,该模型已具备强大的语言理解和生成能力。
- 在此基础上,通过专门的微调过程,进一步训练模型以适应生物医学语言的特点和任务。
-
使用定制数据集:
- 医学指导数据集:这是一个特别为医学领域设计的数据集,包含了临床案例、医学研究和其他与健康相关的内容。这些数据帮助模型深入理解医学语言和临床情境。
- 排名和偏好数据集:使用特定的数据集如 Nectar 和 DPO 相关的数据来优化模型在特定医学问答任务上的表现。
主要功能
-
文本生成:生成准确的医学信息和建议,能够在各种医学文本生成任务中表现出色,如撰写病例报告、研究摘要等。
-
文本理解与分析:理解并分析复杂的医学文献,提取关键信息,支持医学研究和实践中的数据驱动决策。
-
问答系统:提供针对医学问题的精准回答,支持医学教育和临床决策过程。
-
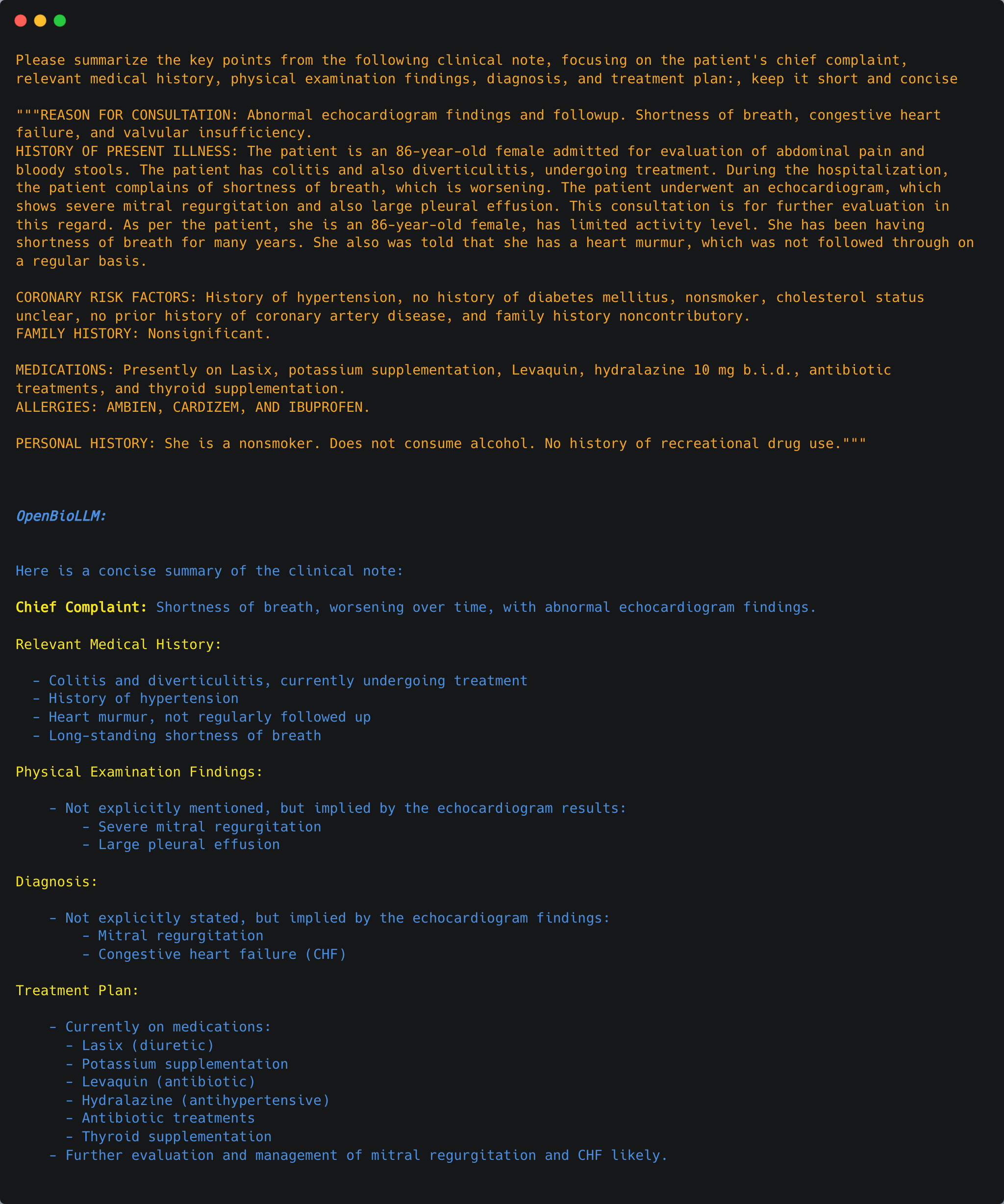
临床笔记总结:自动分析和总结临床笔记、电子健康记录(EHR)和出院小结,提取关键信息,形成结构化总结。

能力
-
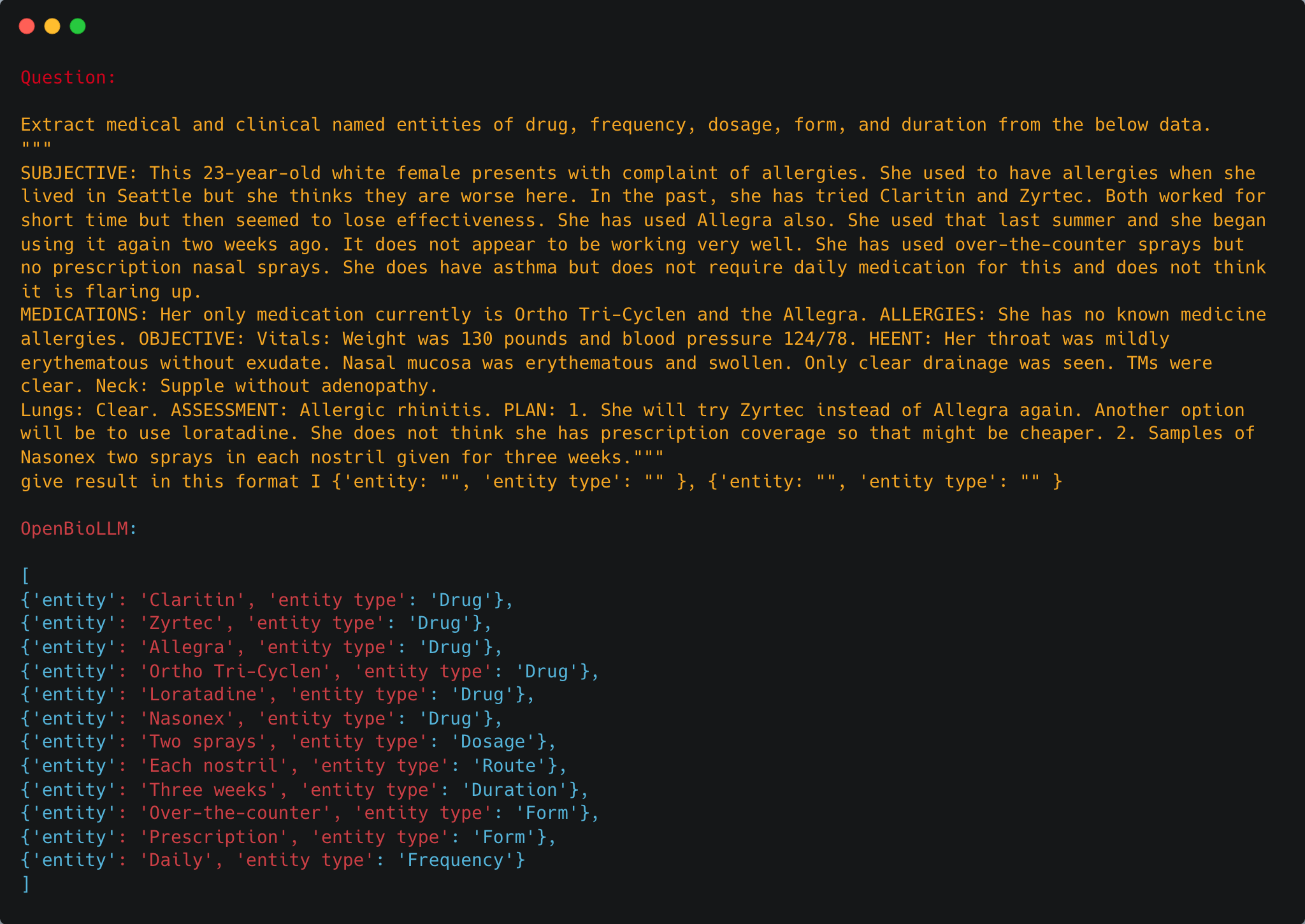
高级临床实体识别:识别和提取医学文本中的关键概念,如疾病、症状、药物、治疗程序和解剖结构,从而支持临床决策支持、药物警戒和医学研究。
-
生物标记提取:精确地识别并提取生物标记,这些标记对于疾病的诊断、治疗和预后至关重要。
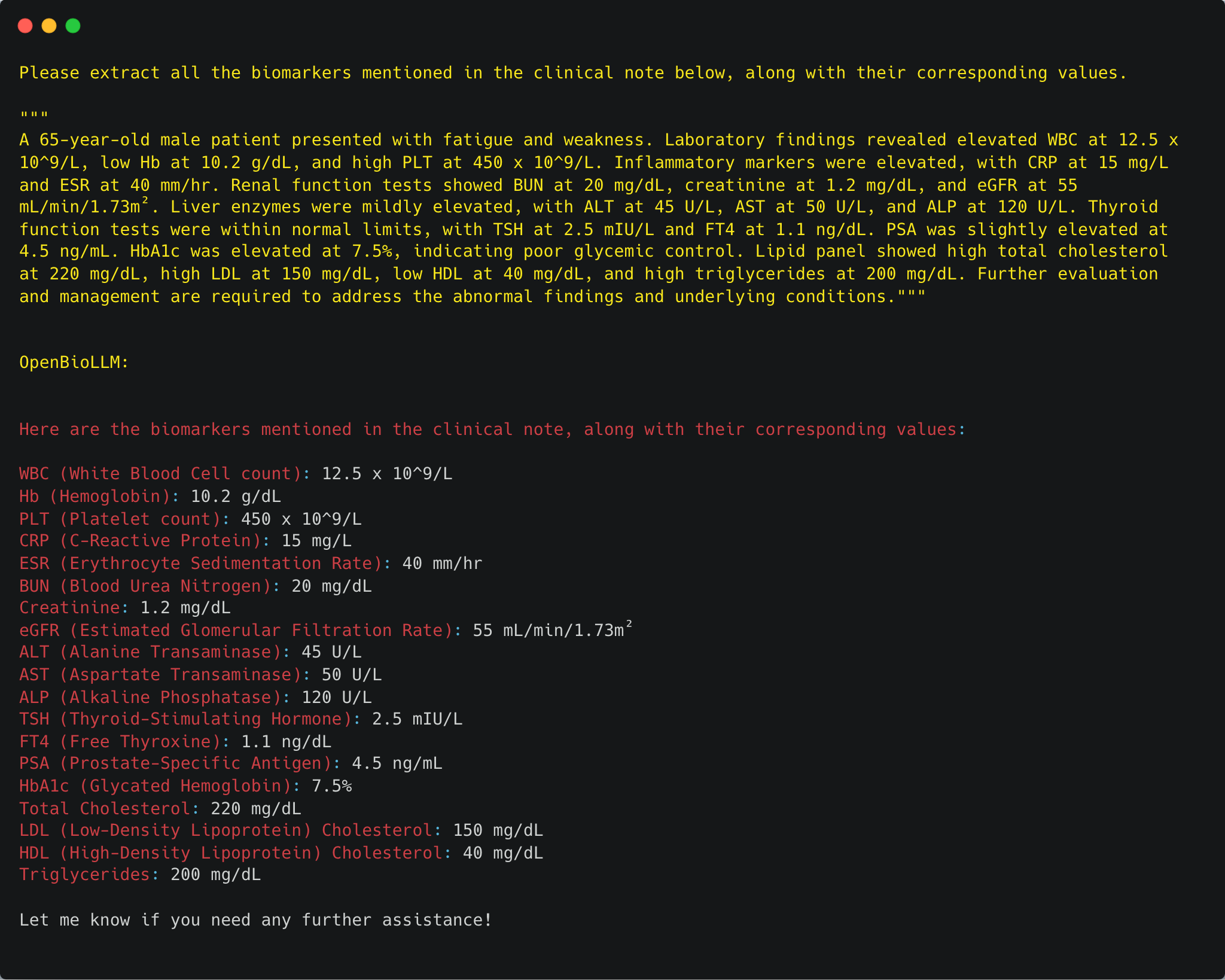
-
医学文档分类和情感分析:对医学文档进行分类,识别文档的情感倾向,这对于管理患者反馈和临床记录非常有用。