

FILM-7B (FILl-in-the-Middle),是一个专注于提高大语言模型(LLM)在长上下文信息利用方面性能的研究项目。
该项目由微软、北京大学、西安交通大学共同研究。FILM-7B 是一个基于Mistral-7B模型的改进版本,旨在通过特定的训练方法解决长上下文中的信息利用问题。
FILM-7B 能够有效处理和理解长篇幅的文本,比如书籍、研究报告、或者长篇新闻文章。这使得它在需要深入文本分析和理解的领域,如学术研究和内容审核,表现出色。
模型能在包含大量信息的数据集中准确地找到用户需要的信息。这一能力使其在法律文档分析、技术文档管理等领域非常有用,特别是在需要从大量文本中提取特定数据或事实的情况。
解决的问题
FILM-7B解决的主要问题是大语言模型在处理长上下文时常见的“丢失在中间”挑战,即模型往往能理解上下文的开始和结束部分的信息,但对中间部分的信息处理不足。这一问题在长上下文的理解和信息检索任务中尤为突出,严重影响了模型的实用性和效率。通过IN2训练,FILM-7B显著提高了模型在长上下文中的信息利用效率和精确度。
-
位置偏见问题:
- 传统的大型语言模型(LLM)通常在处理长上下文信息时会存在位置偏见,即模型往往重视上下文的开头和结尾部分的信息,而忽略中间部分。这种偏见会导致模型在需要全面理解整个上下文以提取或推理信息时效果不佳。
-
长上下文的信息整合和推理能力不足:
- 在处理涉及大量数据或复杂信息结构的任务时,传统模型往往难以有效地整合和推理跨越多个数据段的信息。这限制了模型在某些实际应用中的效用,例如在法律、医疗或科学研究文献中查找和整合信息。
-
提高长上下文任务的性能:
- 随着数据量的增加和任务需求的多样化,需要模型能够更好地处理更长的上下文,以提高在实际应用中的表现和准确性。
通过引入IN2训练,研究人员能够显著提升语言模型在这些领域的表现,尤其是在处理长上下文和需求复杂信息处理的任务上。这种训练方法通过创新的数据生成和训练技术,使模型更好地理解和使用上下文中的信息,不再仅仅侧重于文本的开始或结束部分。
FILM-7B在多个探针任务和真实世界长上下文任务中显示出了卓越的性能,如NarrativeQA和MMLU测试。这证明了IN2训练方法不仅能够改善模型在探针任务中的表现,还能将学习到的能力推广到现实世界的应用场景中。此外,FILM-7B在短上下文任务上的表现也保持稳定,说明增强长上下文处理能力并不会损害模型在传统短上下文任务中的表现。
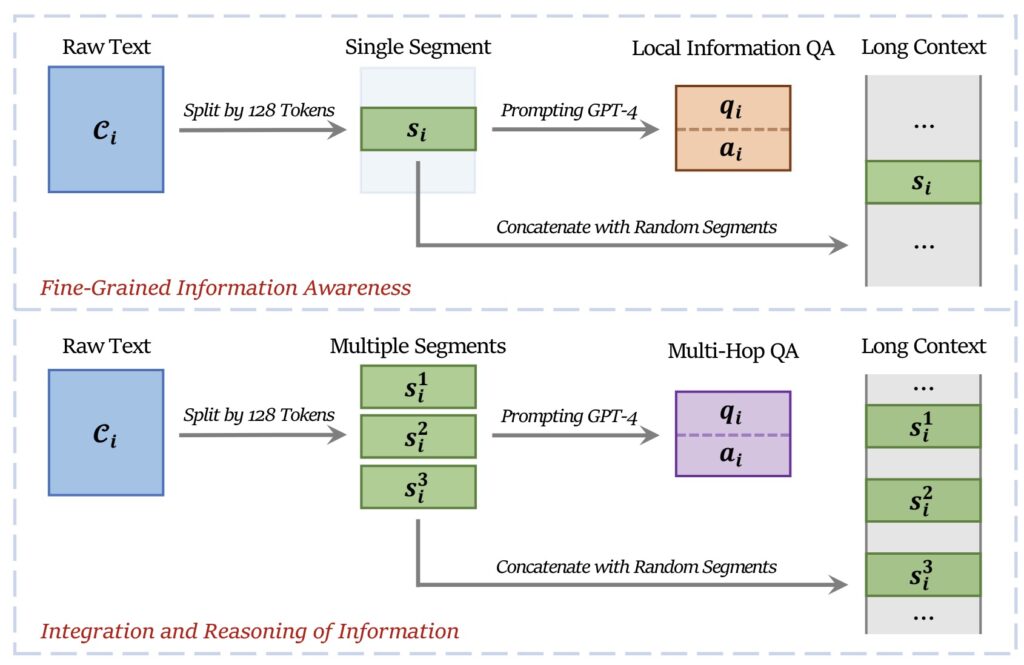

技术方法
FILM-7B 使用的关键方法是信息密集型 INformation-INtensive (IN2) 训练,这是一种创新的数据驱动解决方案,专为改善大型语言模型在处理长上下文时的性能设计。以下是IN2训练方法的核心组成和执行细节:
1. 长上下文数据的合成
FILM-7B的训练依赖于合成的长上下文问答(QA)数据集,这些数据集专门设计来模拟真实世界中信息分布广泛的场景。具体方法如下:
- 从广泛的自然语言文本中抽取多个短段(大约128个令牌),这些短段被随机组合成一个长上下文,长度范围从4K到32K令牌。
- 在这个长上下文中,信息的重要部分被分布在不同的位置,以模拟现实世界中信息可能出现在任何位置的情况。
2. 问答对生成
- 使用先进的语言模型(如GPT-4-Turbo)根据长上下文生成相关的问答对。
- 这些问答对旨在测试模型是否能准确识别和处理长上下文中某个特定位置的信息,包括细粒度信息感知和多点信息整合。
3. IN2 训练策略
IN2训练策略的核心在于强化模型对长上下文中各个位置信息的处理能力,以及提高其在长上下文中整合和推理多段信息的能力。具体训练步骤包括:
- 使用上述合成的问答对作为训练数据,其中问题设计来要求模型从长上下文中提取和整合关键信息。
- 通过最小化答案预测的损失来优化模型,使其能够更好地处理分布在长上下文中的信息。
4. 性能评估与探针任务
为了评估FILM-7B模型的性能,设计了多种探针任务,这些任务覆盖了不同的上下文风格(文档、代码、结构化数据)和信息检索模式(前向、后向和双向检索)。这些探针任务的目的是测试模型在不同场景下对长上下文的处理能力。
- 文档句子检索:测试模型在文档风格上下文中的双向检索能力。
- 代码功能检索:评估模型在代码上下文中的后向信息检索能力。
- 数据库实体检索:考察模型在结构化数据上下文中的前向信息检索能力。
这些任务不仅涵盖了不同的上下文类型,还包括了前向、后向和双向等不同的信息检索模式,以全面考验模型的长上下文信息处理能力。
除了探针任务之外,FILM-7B还在多个真实世界的长上下文任务上进行了评估,这些任务包括:
- NarrativeQA:要求模型回答基于长篇故事或书籍内容的问题。
- MMLU (Massive Multitask Language Understanding):一系列涵盖广泛领域的问题,测试模型的多任务语言理解能力。
- 其他基于长文档的问答和总结任务:例如,从政府报告中提取关键信息或从多个新闻文章中生成综合新闻摘要。
在这些任务中,FILM-7B需要展示其在处理大量信息并从中提取和整合关键知识的能力。


举例解释其工作原理
理解 FILM-7B 的工作原理可能有些复杂,因为它涉及到对模型的训练方法和数据处理方式的深入理解。让我通过一个更具体的、简化的例子来帮助你理解 FILM-7B 如何训练以及它如何提高处理长上下文的能力。
例子:读书笔记
假设你正在读一本关于第二次世界大战的书,这本书非常厚,包含了许多章节,每个章节详细描述了不同的历史事件和人物。现在,我们想训练一个模型,使其能够理解整本书的内容,并能回答关于书中任何部分的问题。
步骤1:创造训练数据
- 分割:首先,我们将整本书分割成许多小段,每段大约包含100-150词。
- 合成:然后,我们随机选择这些段落,合成一个长的文本块,长度可能在几千到几万词之间。
步骤2:生成问题和答案
- 问题生成:针对合成的长文本块,我们设计一系列问题。比如,一个问题可能是:“在描述诺曼底登陆的部分,哪位将军扮演了关键角色?”
- 答案提供:基于文本内容,我们或使用先进的语言模型自动生成答案,或手动提供答案。
步骤3:训练模型
- 模型训练:使用这些问题和答案对来训练 FILM-7B 模型。训练的目的是使模型学会从长文本中精确地提取信息,即使这些信息分散在数千词的文本中。
- 损失优化:模型在训练过程中尝试预测正确的答案,通过最小化预测错误(损失)来逐步改进其性能。
步骤4:评估模型
- 测试:在模型训练完成后,我们会用类似的但未见过的新问题来测试模型,看它是否能准确回答关于书中任何部分的问题。
- 性能分析:如果模型能在这些测试中表现出高水平的准确性,这表明它已成功学会了从长上下文中提取和利用信息。
通过这种 IN2 训练方法,FILM-7B 模型不只是记住文本的开头和结尾,它能够有效地理解和回忆整个长文本的内容。这种能力使得模型在需要处理长文章、报告或书籍等场景时特别有用,如学术研究、法律审查或任何需要深入分析大量文本数据的应用。
评估结果
在性能评测中,FILM-7B模型展示了其在处理长上下文信息方面的显著提升,尤其是在多种探针任务和真实世界长上下文任务中的表现。以下是具体的评测结果,这些结果证明了IN2训练方法对模型性能的积极影响。
探针任务的性能评测结果
-
文档句子检索:
- FILM-7B能够准确地从长文档中检索出含有关键信息的句子,展示了其优于传统大型语言模型的双向检索能力。在具体的评分指标上,FILM-7B的准确率高于基线模型Mistral-7B和其他商业模型如GPT-4-Turbo。

- FILM-7B能够准确地从长文档中检索出含有关键信息的句子,展示了其优于传统大型语言模型的双向检索能力。在具体的评分指标上,FILM-7B的准确率高于基线模型Mistral-7B和其他商业模型如GPT-4-Turbo。
