
LLaVA++项目旨在通过扩展原有的LLaVA(Language and Vision Assistant)模型,集成先进的语言模型Phi-3和Llama-3,并赋予它们视觉处理能力。这些模型原本是为了优化语言处理任务而设计,通过此项目的改造,它们现在也能理解和生成与图像相关的内容。
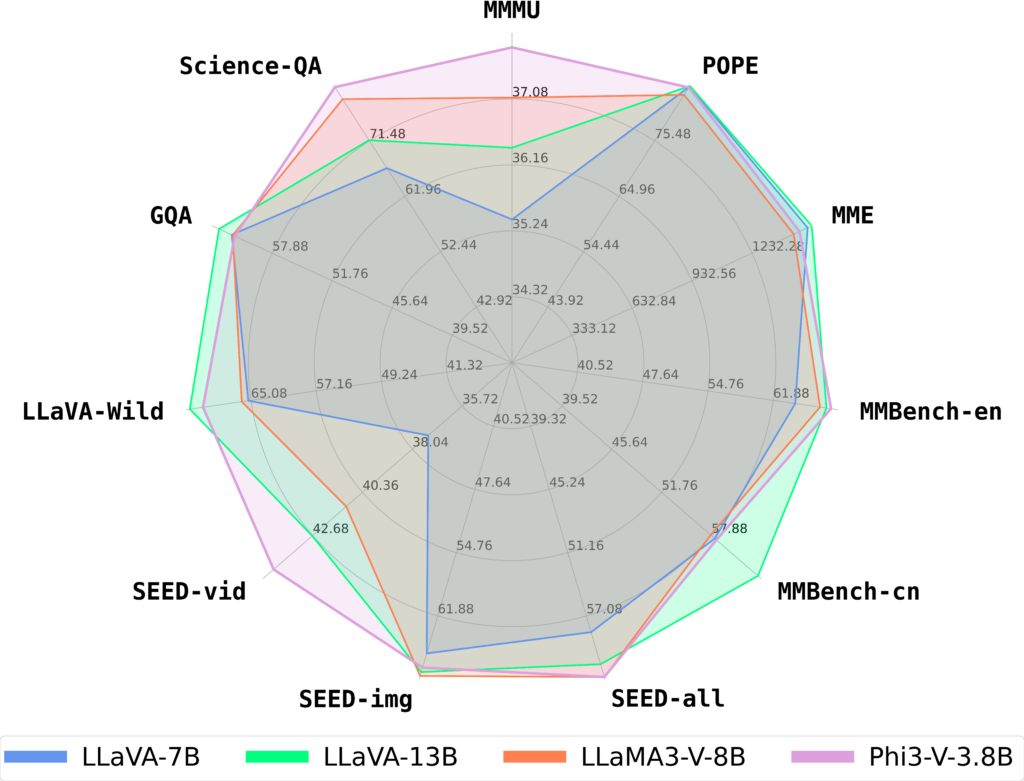

LLaVA++项目旨在通过扩展原有的LLaVA(Language and Vision Assistant)模型,集成先进的语言模型Phi-3和Llama-3,并赋予它们视觉处理能力。这些模型原本是为了优化语言处理任务而设计,通过此项目的改造,它们现在也能理解和生成与图像相关的内容。
