

Cohere 最近推出了其最新的基础模型 Rerank 3,专为提升企业搜索和检索增强生成(RAG)系统而设计。这个模型能与任何数据库或搜索索引兼容,并可以轻松集成到已有的带有原生搜索功能的应用程序中。Rerank 3 旨在通过一种高效且成本低廉的方式改善搜索性能和检索准确性。
解决的问题
Rerank 3 主要解决以下几个问题:
-
搜索质量提升:对于长文档或含有复杂数据结构的文档,传统搜索系统往往难以准确理解和索引其内容,导致搜索结果不准确或不相关。
-
多语言和多格式数据处理:多语言环境和各种半结构化数据格式(如 JSON、电子邮件等)的搜索一直是企业搜索领域的难题。
-
成本和效率:在保持或提升搜索精度的同时,降低企业的总拥有成本(TCO)和操作延迟。
功能特点
-
高级搜索能力:
- 支持长达 4k 字符的上下文长度,显著提高了长文档的搜索质量。
- 能够处理多方面和半结构化数据,如电子邮件、发票、JSON 文档、代码和表格。
- 支持 100 多种语言,提高了多语言数据的搜索准确性。
-
提升企业搜索性能:
- 通过对多方面数据进行基于所有相关元数据字段的排序,增强了搜索的相关性和准确性。
- 优化代码和文档检索功能,提升了搜索系统在处理专业或技术性较强的内容时的效率。
-
成本效率和低延迟:
- 结合 RAG 系统使用时,可以减少传递给生成模型的文档数量,从而在不增加延迟的情况下提高响应的准确性,显著降低成本。
- 与 Cohere 的高效 Command R 系列模型结合使用,进一步降低了总拥有成本。
- 与其他生成型大语言模型(LLM)相比,使用 Rerank 3 的系统运行成本可以降低 80% 至 93%。
- 低延迟操作:在处理短文或长文时,Rerank 3 显示出比前一版本(Rerank 2)高达 3 倍的延迟改进,对于需要快速响应的商业领域(如电子商务或客户服务)尤其重要。
-
易于集成和扩展:
- Rerank 3 已在 Elasticsearch 的推理 API 中原生支持,便于在现有的企业系统中集成和部署。
- 提供强大的语义重排能力,改善了关键词和向量搜索的效率和精确度。

通过这些功能,Rerank 3 不仅提升了企业搜索的效率和准确性,也为企业减少了运维成本,特别是在多语言和复杂数据环境下,提高了搜索系统的适用性和可靠性。
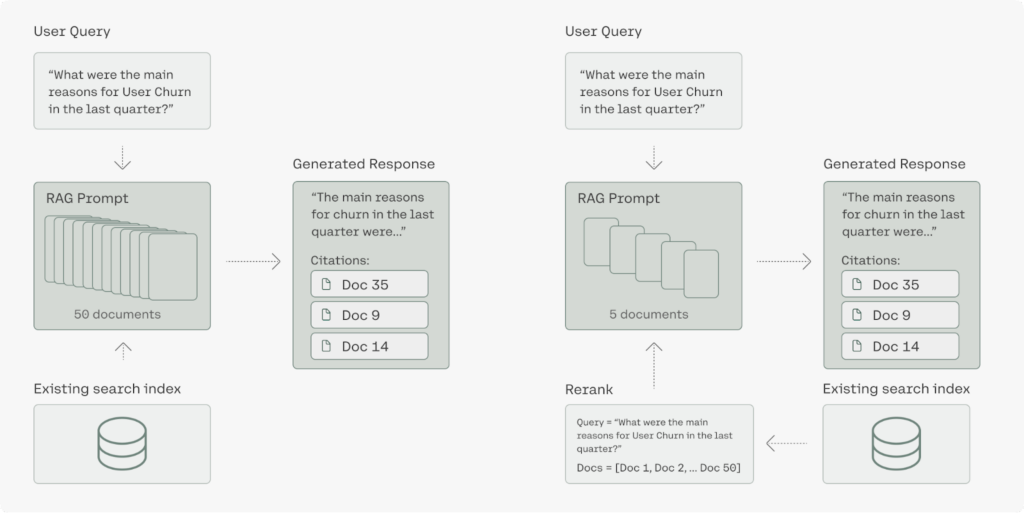
性能更强、效率更高的 RAG
Rerank 3 对检索增强生成(RAG)系统的性能提升具有重要影响

-
高质量的响应:Rerank 3 提升了对 RAG 性能的关键因素,包括响应的质量和延迟。该模型能够隔离出对用户问题最相关的文档,从而提高整体的响应精度。这样的高精度语义重排确保在生成阶段,只有少数、更高质量的文档被传递给大型语言模型(LLM)进行内容生成。
-
延迟改进:与先前版本的 Rerank 模型相比,Rerank 3 在短文档长度的情况下延迟降低了 2 倍,而在长上下文长度的情况下延迟改进高达 3 倍。这种延迟的显著降低对于需要快速响应的业务领域,如电子商务或客户服务,至关重要。
-
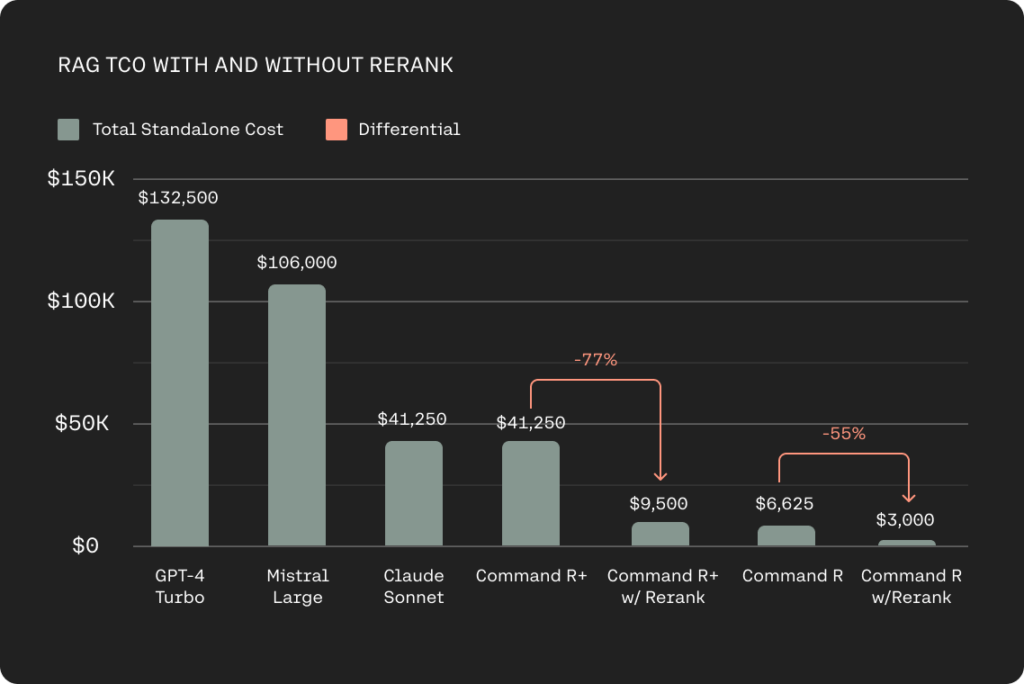
成本效率:在 RAG 系统中,检索步骤至关重要。通过 Rerank 3 加入 RAG 系统,用户可以向 LLM 传递更少的、更相关的文档进行基于内容的生成,同时维持总体的精确度,并且不增加延迟。这一效应使得与 Rerank 一起运行 RAG 的成本比使用其他生成型 LLMs 在市场上的成本降低了 80-93%,与 Rerank 和 Command R 一起使用时的节省成本可达 98%。
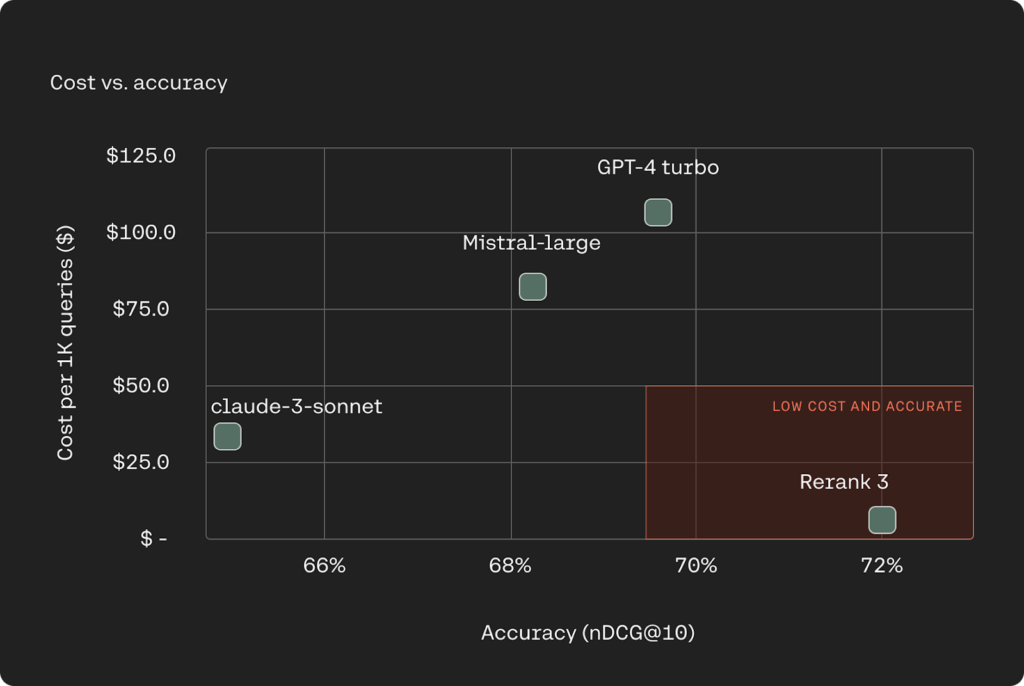
-
独立成本:基于 1M RAG 提示的推理成本进行计算,每个文档包含 250 个令牌,每个输出包含 250 个令牌,不使用 Rerank 的成本与使用 Rerank 的成本进行了对比。在使用 Rerank 的场景中,只处理 5 份文档的成本显著低于传统方法。
