
Google开发出一种名为“Infini-attention”的新型注意力技术,旨在有效扩展基于Transformer的大语言模型(LLMs)以处理无限长的输入,同时限制内存和计算资源的使用。这项技术通过在标准注意力机制中引入压缩记忆(compressive memory)来实现,整合了局部掩码注意力和长期线性注意力机制于单个Transformer块中。
Infini-attention技术能够使大语言模型有效处理无限长的输入,同时不增加内存和计算资源的占用和消耗。
该技术解决的主要问题是传统的基于Transformer的大语言模型(LLMs)在处理极长序列时遇到的内存和计算资源限制。传统Transformer模型中的注意力机制在处理长序列时会面临内存使用量和计算时间呈二次方增长的问题,这限制了模型处理长文本能力,使得在资源有限的情况下难以有效扩展到长序列任务上。
解决的问题:
- 内存和计算效率:传统模型在处理长序列数据时,其内存和计算需求随序列长度呈二次方增长,导致长序列任务变得不切实际。
- 长期依赖捕获能力:长序列数据处理需要模型能够有效捕获和处理长期依赖信息,而现有Transformer结构在此方面受到其固有设计的限制。
Infini-attention成果:
- 无限长输入处理能力:提出的Infini-attention技术能够使大型语言模型有效处理无限长的输入,同时保持内存和计算资源的使用在一个有界的范围内。
- 高效的压缩记忆机制:通过引入压缩记忆到标准的注意力机制,该技术能够在不牺牲性能的情况下显著减少模型对内存的需求。实验显示,在处理长上下文语言建模任务时,内存大小的压缩比率达到了114倍。
- 优越的性能:在多个长序列任务上,如1M序列长度的密钥上下文块检索和500K长度的书籍摘要任务,经过Infini-attention处理的模型表现出色,甚至达到了新的状态(SOTA)。
- 支持快速流式推理:引入的内存参数极少,使得模型能够支持快速流式推理,提高了模型的实用性和灵活性。
- 模型扩展性:通过Infini-attention,传统的大型语言模型可以通过持续的预训练和微调自然扩展到无限长的上下文处理,且引入的内存参数极少,支持快速流式推理。
技术方法
“Infini-attention”技术通过引入一种新型的注意力机制来处理无限长的输入,主要特点和方法包括:
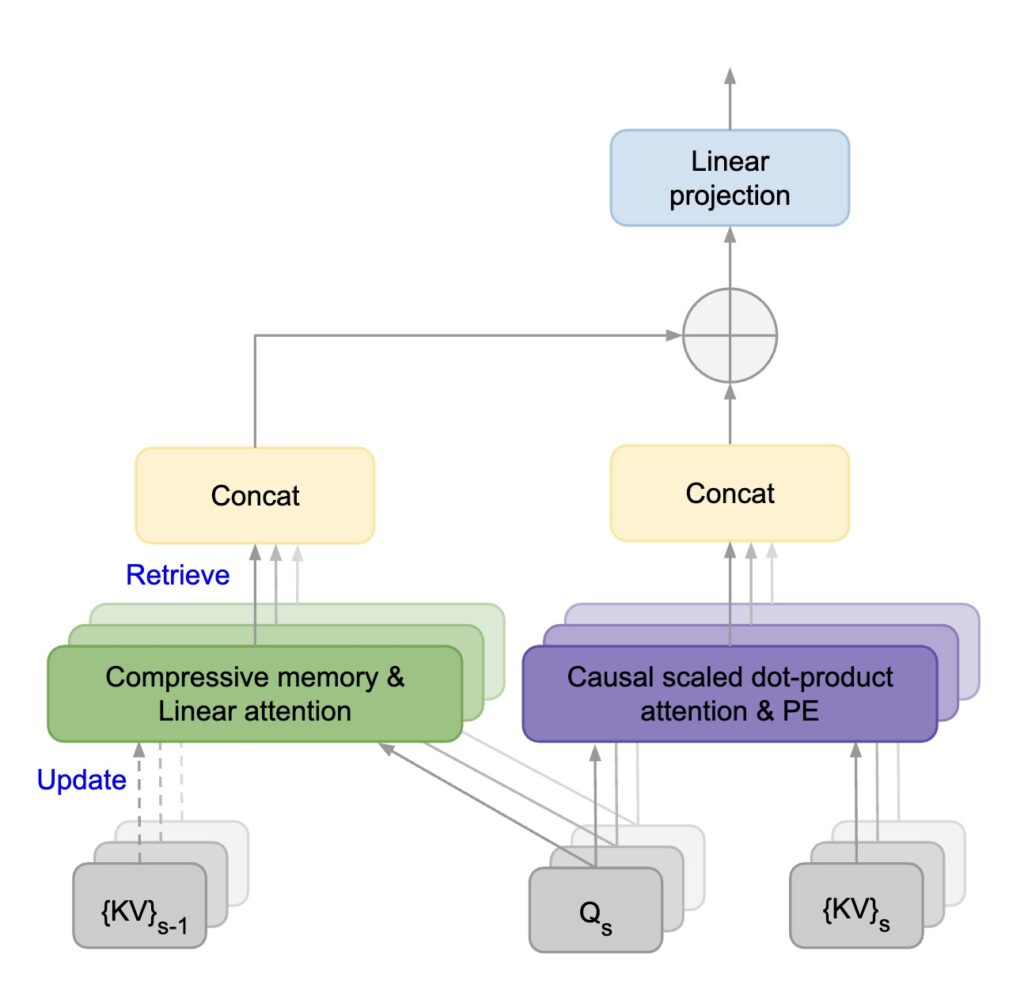
- 压缩记忆机制:这是Infini-attention的核心组成部分,允许模型以有界的内存和计算成本处理长期依赖信息。压缩记忆通过维持一组固定数量的参数来存储和回忆长期信息,而不是随输入序列长度线性增长。该技术通过引入压缩记忆到标准的注意力机制中,使模型能够在有限的内存中存储长期的上下文信息。这种压缩记忆不是简单地存储过去的所有输入,而是以一种高效的方式压缩这些信息,确保了既能回忆重要的长期信息,又不会随着输入序列的增长而导致内存使用急剧增加。
- 局部与长期注意力的结合:Infini-attention在单个Transformer块中结合了局部掩码注意力(处理短期依赖)和长期线性注意力(处理长期依赖),允许模型同时捕获长距离和短距离上下文信息。局部掩码注意力负责捕捉近距离的依赖关系,而长期线性注意力则处理更远距离的依赖。这种设计使模型能够同时理解近期和远期上下文,增强了模型对长序列数据的处理能力。
- 流式处理能力:利用压缩记忆和改进的注意力机制,Infini-attention支持对极长输入数据的流式处理,即使在有限的内存和计算资源下,也能高效处理。得益于压缩记忆和结合了局部与长期注意力的设计,Infini-attention支持以流式方式处理极长的输入序列。即使是非常长的文本,也可以分段输入模型进行处理,每一段的处理都会考虑到之前所有段的上下文信息,从而保持了连贯性和上下文的完整性。
实验结果
Infini-attention技术的有效性通过一系列实验得到了验证:
- 长上下文语言建模:在使用“Infini-attention”技术的情况下,模型在处理长序列数据时所需的内存压缩率达到了114倍。这意味着,与传统方法相比,“Infini-attention”能够在大幅减少内存使用的同时,仍然保持或甚至超过基线模型(即传统未经优化处理长上下文能力的模型)的性能。这种性能指的是模型在理解和生成语言方面的能力,包括但不限于正确预测下一个词、理解复杂句子结构和上下文含义等。
- 1M序列长度的密钥上下文块检索任务:当“Infini-attention”技术应用于一个规模为1B(1B,即十亿)参数的大语言模型时,这个模型的处理能力得到了显著扩展,能够自然处理长达100万(1M)个序列长度的数据。并且,在这个扩展后的处理能力上,模型在一个特定的任务——密钥检索任务中表现出色。密钥检索任务可能是一个测试模型能否从非常长的文本中准确找出特定信息(如一个“密钥”)的任务。
- 500K长度的书籍摘要任务:当“Infini-attention”技术应用于更大规模,8B(,即80亿)参数的大语言模型时,这个模型能够处理长达50万(500K)个序列长度的书籍摘要任务,并且在这个任务上达到了新的最佳状态(State Of The Art,SOTA)。这表明“Infini-attention”不仅提高了模型处理长文本的能力,还提升了模型在特定任务上的性能,使其能够生成更准确、更高质量的内容摘要。
- 模型性能:在不同的实验设置下,Infini-attention不仅展示了在处理长序列时的高效性和准确性,而且在内存使用和计算资源上表现出显著的优势,实现了对长期上下文信息的有效建模和利用。