Octopus-V2-2B是由斯坦福大学Nexa AI开发的一种先进的开源大型语言模型,具有20亿参数,专为Android API的功能调用定制。与需要详细描述潜在函数参数的检索增强生成(RAG)方法不同,Octopus-V2-2B采用了一种独特的功能性标记(functional tokens)策略,用于其训练和推理阶段。这种方法不仅使其达到了与GPT-4相当的性能水平,还大幅提高了推理速度,超越了基于RAG的方法,特别适用于边缘计算设备。
它能够在设备上直接运行,支持广泛的应用场景,从而推动Android系统管理和设备间协同工作的新方式。其快速和高效的推理能力,特别适合需要高性能和精确功能调用的场景,如智能家居控制、移动应用开发等。
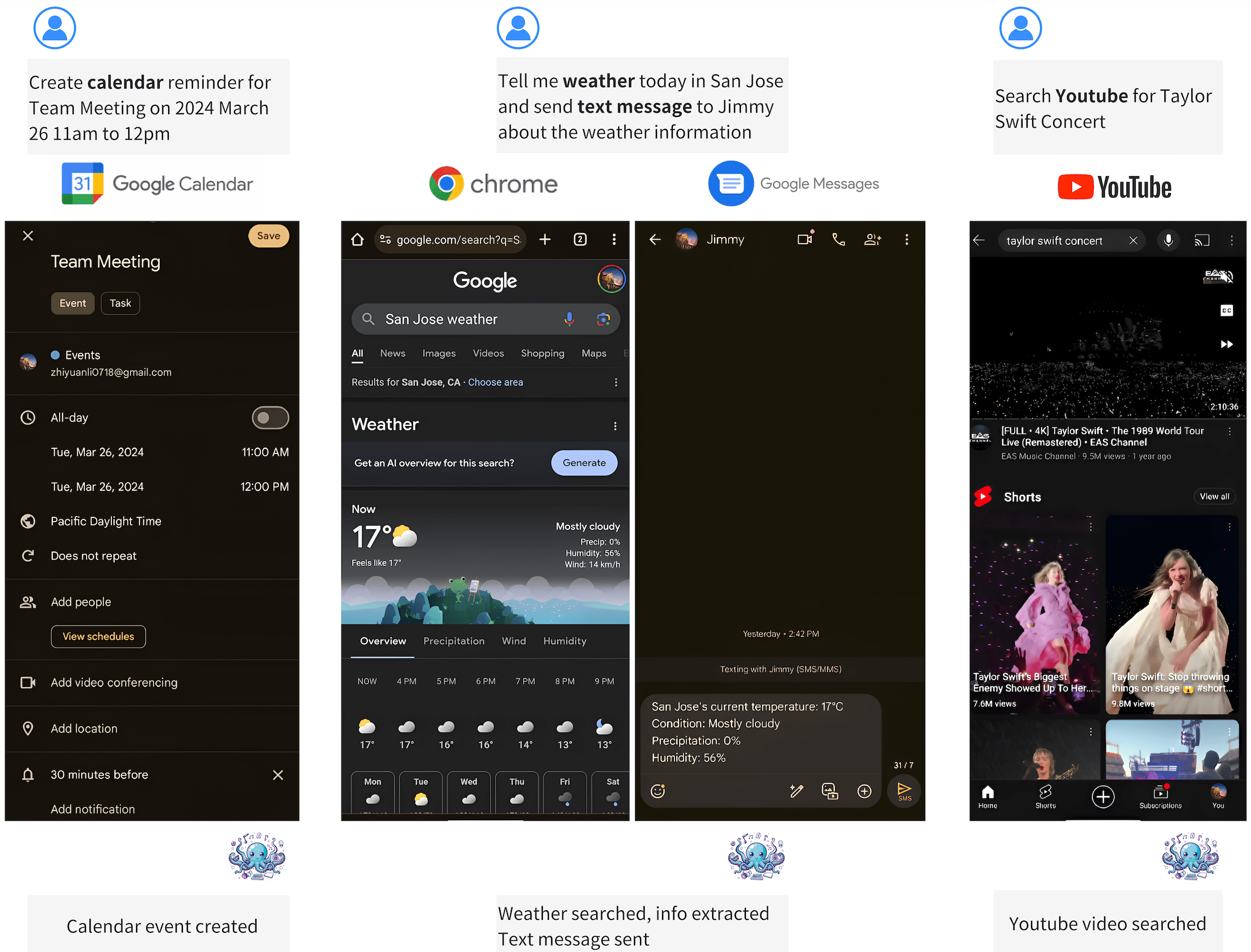
Octopus-V2模型在安卓手机上运行视频
直接通过文字指令就能指挥手机进行各种操作 如拍照、发邮件、设置闹钟、打开关闭勿扰模式等 今年AI手机有望有重大的飞跃…
技术细节:
- 功能令牌:引入了特定的令牌(如
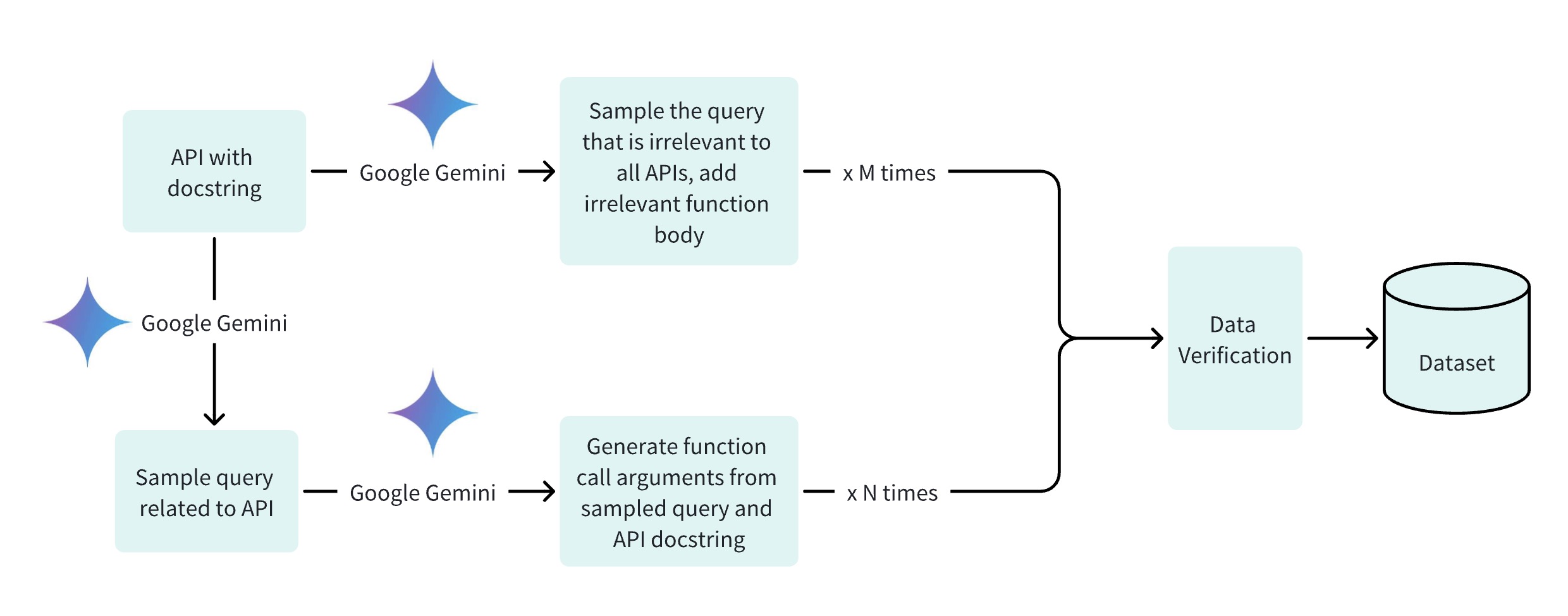
<func_1>)来代表每个支持的功能,并将这些令牌整合到了分词器中; - 数据集组装:为每个功能策划或生成了100到1000个数据点,将命令(如“take a photo”)转换成
<func2>; - 基于Gemma 2B模型,对模型进行了微调,使其能够熟练地识别合适的功能和参数来执行;
- 优化的模型被部署在边缘设备上,实现了高效的设备上代理创建。
洞见:
- 特殊令牌减少错误:为每个功能分配一个独特的令牌,显著降低了功能选择的错误率,去除了超过95%的上下文。
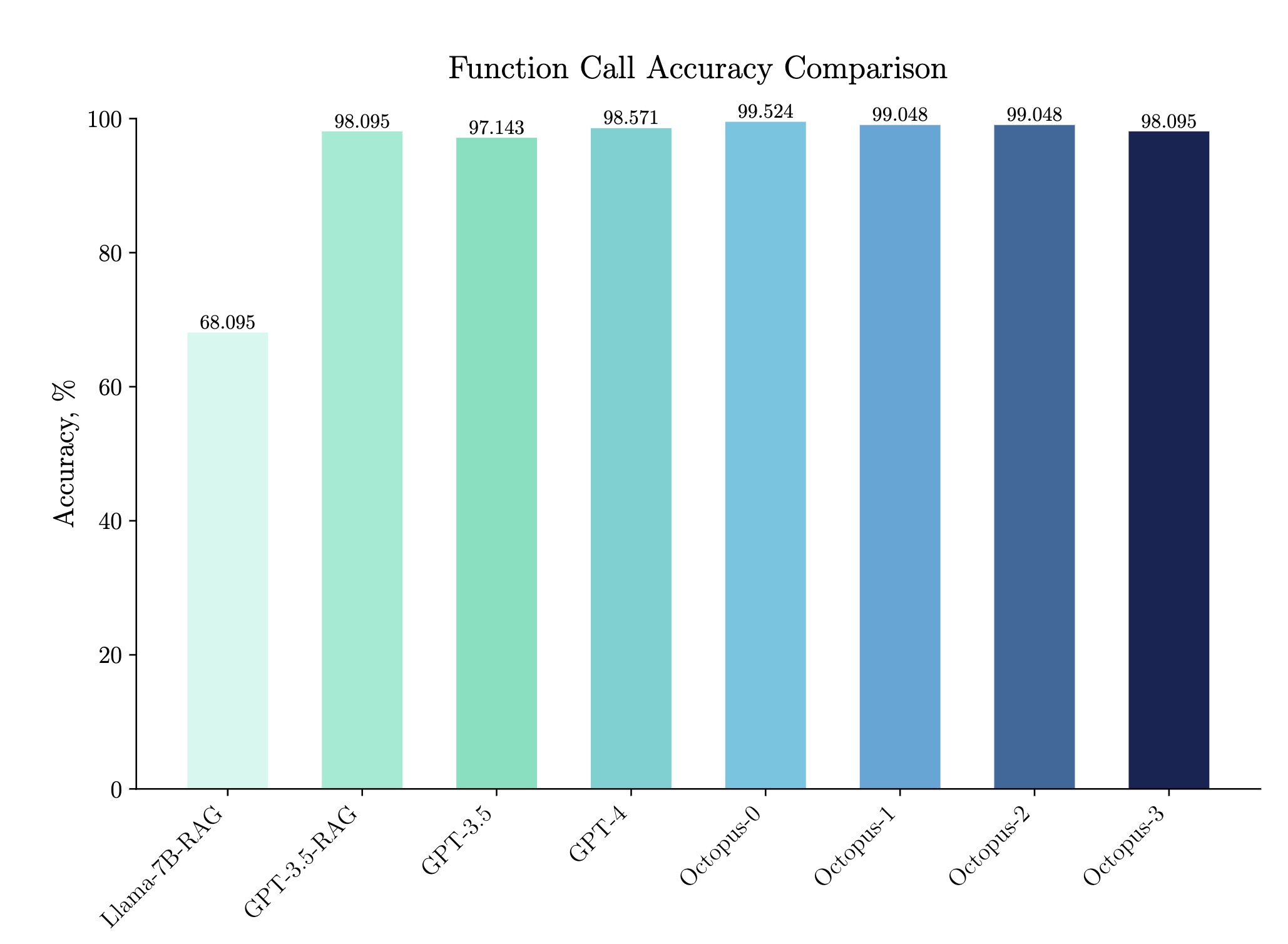
- 卓越的准确性:即使每个功能只有100个样本,也达到了惊人的98.095%的准确率。
- 响应时间的提升:与基于RAG的Llama-7B功能调用相比,他们的方法在延迟上显示了35倍的改进。
- 在设备上的工作时间:对于典型查询,处理时间在1.1到1.7秒之间。它可以在汽车、耳机、手机、PC等设备上部署。
- 实际应用:Octopus v2能够转变智能设备,实现与地图、外卖等各种服务的无缝互动。

功能特点
- 高精度的功能调用:Octopus v2通过引入功能性标记(functional tokens),能够准确地选择和调用正确的函数,提高了功能调用的准确性。
- 优化的延迟:相比传统的基于RAG的功能调用方法,Octopus v2大幅减少了延迟,提高了推理速度,适合实时应用。
- 上下文长度减少:通过其独特的设计,Octopus v2在进行功能调用时所需的上下文长度减少了95%,这意味着它能够更快地处理请求,同时减轻了设备的负担。
- 设备上运行:Octopus v2专为边缘设备设计,能够直接在设备上运行,无需依赖云计算资源,这样既保护了用户隐私,也减少了使用成本。

优势
- 隐私保护和成本效益:由于能够在设备上直接运行,Octopus v2避免了数据在云端处理可能引起的隐私问题,同时减少了因依赖云服务而产生的成本。
- 适应多种边缘设备:Octopus v2的设计考虑了边缘设备的多样性和限制,能够在不同的设备上高效运行,包括智能手机、车载系统、VR头盔等。
- 提高功能调用的准确性和速度:通过创新的方法优化了功能调用的精度和响应速度,对于需要快速反应的应用场景尤为重要。
- 减少能源消耗:在保持高性能的同时,Octopus v2还能有效降低设备的能源消耗,延长电池寿命。
性能
- 延迟:在基准测试中,Octopus-V2-2B展示了显著的推理速度,其速度是单个A100 GPU上“Llama7B + RAG解决方案”的35倍。与依赖A100/H100 GPU集群的GPT-4-turbo(gpt-4-0125-preview)相比,Octopus-V2-2B快了168%。
- 准确性:Octopus v2在功能调用的准确性上超过了包括GPT-4等现有的解决方案,准确率在各类基准测试中接近100%。其功能调用准确率比“Llama7B + RAG解决方案”高出31%。在基准数据集中,其功能调用准确率与GPT-4和RAG + GPT-3.5相当,分数在98%到100%之间。
- 效率:通过有效减少所需的上下文长度和优化推理速度,Octopus v2在不牺牲准确性的前提下提供了高效的性能,特别适合在资源受限的设备上运行。
模型架构及技术原理
Octopus v2使用了Google Gemma-2B模型作为其预训练模型的基础。在此基础上,通过引入特殊的功能性标记(functional tokens)和进行细致的微调,Octopus v2能够理解和执行软件应用中的函数调用,从而实现了在设备上运行时更高的准确性和更低的延迟。这种方法有效地将Google Gemma-2B模型转化为一个更适合在边缘设备上使用的高性能语言模型,同时节省了上下文长度并优化了性能。

- 预训练模型选择: Octopus v2选择了Google Gemma-2B模型作为预训练基础,这是因为Gemma-2B提供了强大的语言理解和生成能力,是构建高性能语言模型的理想起点。
- 功能性标记引入: 为了提高模型在函数调用任务上的性能,Octopus v2引入了功能性标记(functional tokens)。这些标记代表了不同的软件操作或功能,使得模型能够通过识别这些标记来准确执行特定的函数调用。
- 模型微调: 在预训练模型的基础上,通过对模型进行细致的微调来适应具体的函数调用任务。这一步骤涉及将功能性标记及其对应的函数描述加入训练数据中,训练模型以理解和映射这些标记到相应的软件操作上。
- 减少上下文长度: 通过优化模型的输入处理方式,Octopus v2能够在进行函数调用时显著减少所需的上下文长度。这是通过直接使用功能性标记来指代复杂的函数调用过程,从而减轻模型处理负担并加快响应速度。
- 提高执行效率: 微调后的Octopus v2模型能够快速准确地识别功能性标记,并映射到正确的函数执行过程,无需处理冗长的自然语言指令。这不仅提高了函数调用的准确性,也大大缩短了执行时间,降低了设备上的运算需求。
- 边缘设备部署: 优化后的模型特别适合在边缘设备上部署,如智能手机、汽车、智能家居设备等。这些设备通常资源有限,但通过Octopus v2,它们能够本地执行复杂的语言处理任务,实现快速响应和高度隐私保护。
- 实现多样化应用: 凭借其在设备上执行的能力,Octopus v2可以支持多种应用场景,包括但不限于智能家居控制、车载系统交互、离线语音助手等。