
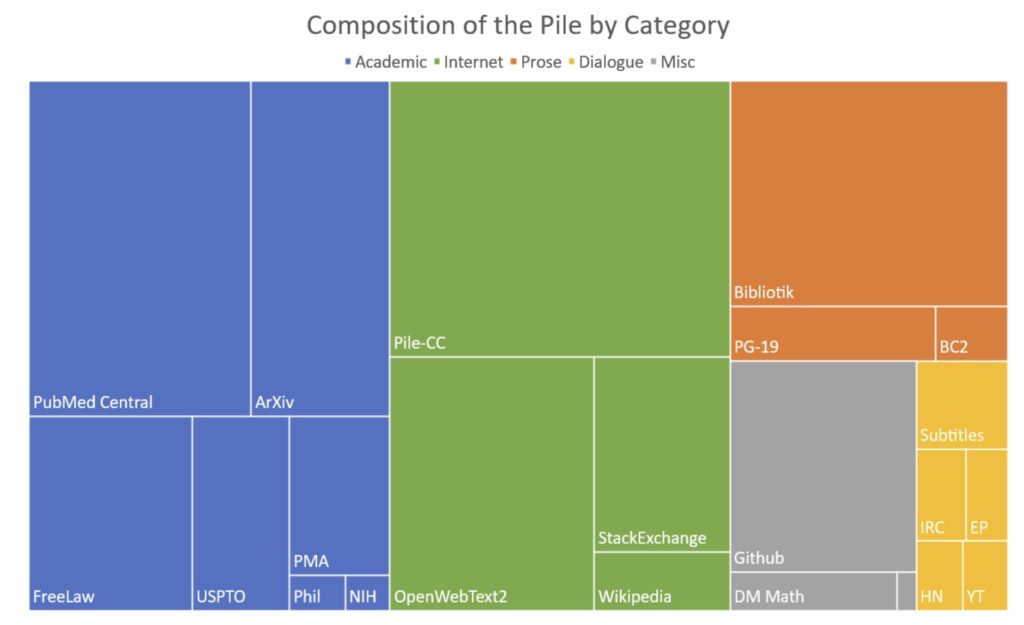
The Pile是一个由EleutherAI提供的825 GiB大小的多样化、开源语言建模数据集,它由22个较小的、高质量的数据集组合而成。这个数据集的目的是为了提高大型模型的跨域知识以及下游泛化能力,通过增加数据来源的多样性来实现。模型在The Pile上的训练不仅在传统的语言建模基准测试中表现出适度的改进,而且在Pile BPB(每字节比特数)上也显示出显著的改进,这是一个衡量模型在不同领域(包括书籍、GitHub仓库、网页、聊天记录、医学、物理、数学、计算机科学和哲学论文)理解能力的指标。
数据集特点
-
庞大的规模:总计达825.18GiB的数据量,提供了一个极为丰富的文本资源,用于训练大规模语言模型。