

Recraft推出了其最新的图像生成模型——Recraft V3。通过引入设计语言思维,Recraft V3能够在图像生成领域超越所有主要竞争对手。
Recraft V3能够在生成图像时精确处理复杂长文本描述,而不仅限于几个关键词。模型可理解并响应长句提示,从而生成包含多个对象、特定颜色、精确布局的场景。
模型生成的图像注重解剖学细节,比如正确的手指数量、自然的身体比例、准确的背景与前景物体的空间关系,确保生成的图像具有高度的真实感和一致性。
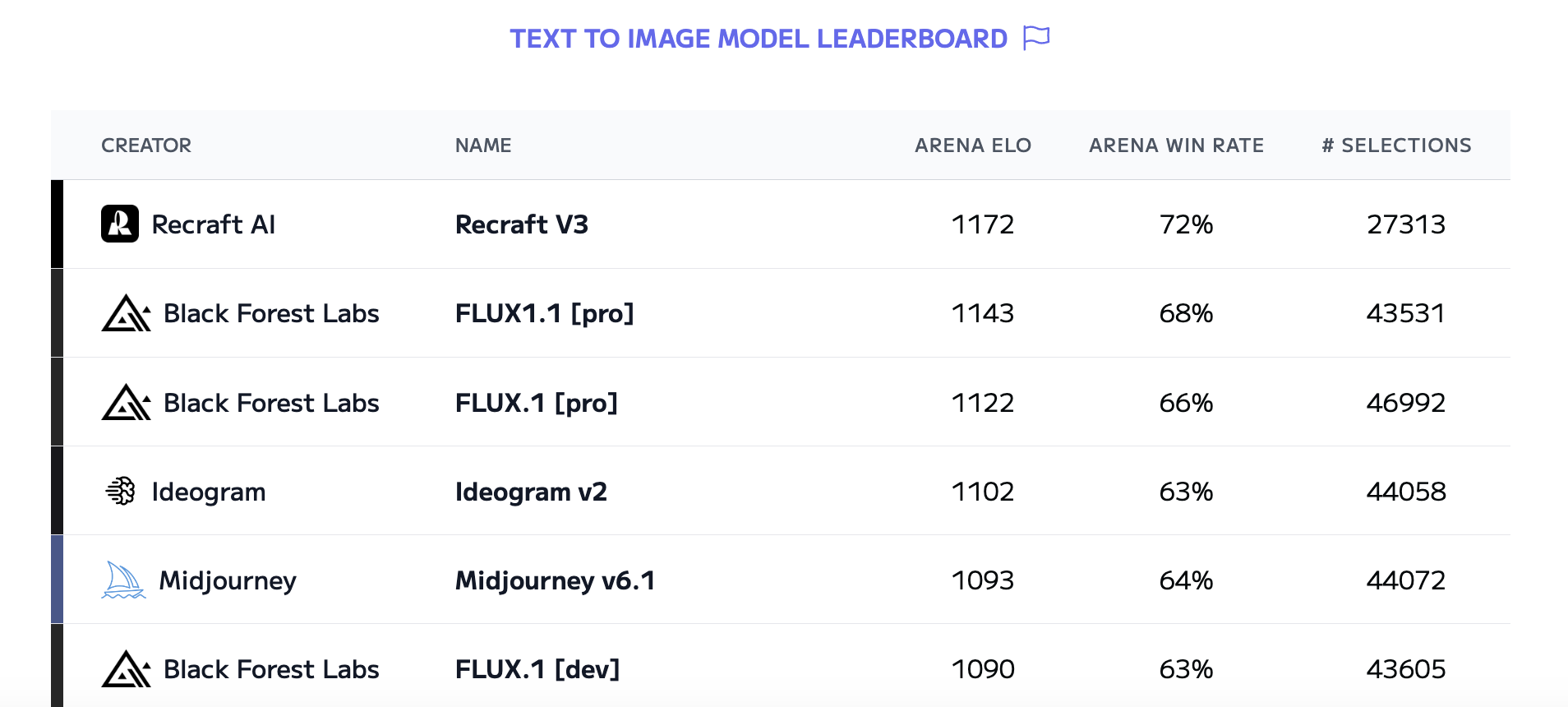
Recraft V3 在 Hugging Face 的文本到图像模型人工分析排行榜。以 1172 的 ELO 评级获得第一名。Recraft 的新模型显示出比 Midjourney、OpenAI 和所有其他主要图像生成公司的模型更高的质量。

主要特点和优势
1. 高精度的文本生成和复杂场景理解
- 长文本生成:Recraft V3 支持处理长文本提示,不仅可以识别和生成单词或简单短语,还能理解复杂的描述。可以在图像中展现提示中的细节,包括对象的数量、颜色和具体位置,适合复杂场景需求。


- 解剖学准确性:模型能够生成符合解剖学真实的图像,包括正确的身体比例、手指数量、肢体姿态和背景与主体的空间关系。这种精确性尤其适合需要高度真实感的图像应用。






2. 高水准的美学效果
- 美学训练:Recraft V3在图像美学上经过精细训练,生成的图像具备视觉吸引力,与高质量的摄影作品媲美。这项特性让Recraft在需要视觉吸引力的应用(如品牌广告、创意内容)中具备优势。
- 风格一致性:支持用户定义一组图像以确定品牌风格,然后进行微调,无需重新训练模型。用户可以通过设置参考图像,确保所有生成内容与品牌调性和视觉标准一致。

3. 强大的设计控制功能
- 精确位置和大小控制:Recraft V3 允许用户在图像中精确设置文本和其他元素的位置和大小,方便设计师自由排列图像组件,满足特定设计布局需求。该功能对需要严格控制排版的项目(如广告、海报设计等)尤为适合。


- 矢量图生成:Recraft V3 支持生成清晰的矢量图,从简单的图标到复杂的艺术作品均可实现。矢量图可以无限缩放,适合标志、UI图标和需要高分辨率的场景。

- 复合图像生成:模型支持图像和文本的组合生成,使用户能够生成包含多个对象的复杂图像。用户还可以将多个图像叠加,以生成高度自定义的设计。


4. 全面的图像编辑工具
- AI编辑功能:Recraft V3 提供了全面的编辑工具,包括AI橡皮擦、区域修改、背景移除、AI放大器、inpainting(图像补全)和outpainting(扩展生成)等功能,为用户提供了图像生成和后期编辑的一站式解决方案。
- 扩展生成(Outpainting)和补全生成(Inpainting):在图像的现有内容之外进行拓展或对现有内容进行补全,适合需要调整或扩展场景的应用。


5.API 与企业集成
- API功能:Recraft V3 的API允许开发者将AI图像生成和设计功能嵌入现有的企业系统中。API支持生成带有品牌风格的图像、矢量化、背景移除、图像质量提升等功能,便于批量处理图像生成需求。
- 品牌一致性:API可以保持品牌视觉一致性,通过指定品牌颜色和样式来确保每张图像的风格统一,适合企业对品牌形象的统一要求。

应用场景

Recraft V3被设计为适用于各类设计领域的通用AI工具,典型的应用场景包括:
- 品牌设计:企业可以快速生成品牌风格统一的图像,用于宣传材料、包装设计、社交媒体图像等。通过API支持自定义品牌风格,确保视觉形象的连贯性。
- 电商图片优化:通过AI背景移除和矢量化等功能,可以优化产品图片,使其符合电商平台要求,从而提高产品展示效果。
- 游戏设计与艺术资产:为游戏设计者提供了灵活的图形控制工具,以生成高度个性化和复杂的游戏场景、角色和图标。
- 社交媒体和广告:提供了生成高视觉吸引力图像的功能,可以轻松生成用于社交媒体的创意内容和广告,满足视觉吸引力的高需求。
- 定制图标与标志设计:设计师可以利用矢量生成功能为应用或网站生成清晰的图标,确保在各类尺寸和屏幕上都保持视觉一致性。
该模型现在可供免费和付费用户在 Canvas 上的桌面应用程序、移动应用程序(可在iOS和Android上使用)以及API中使用。