
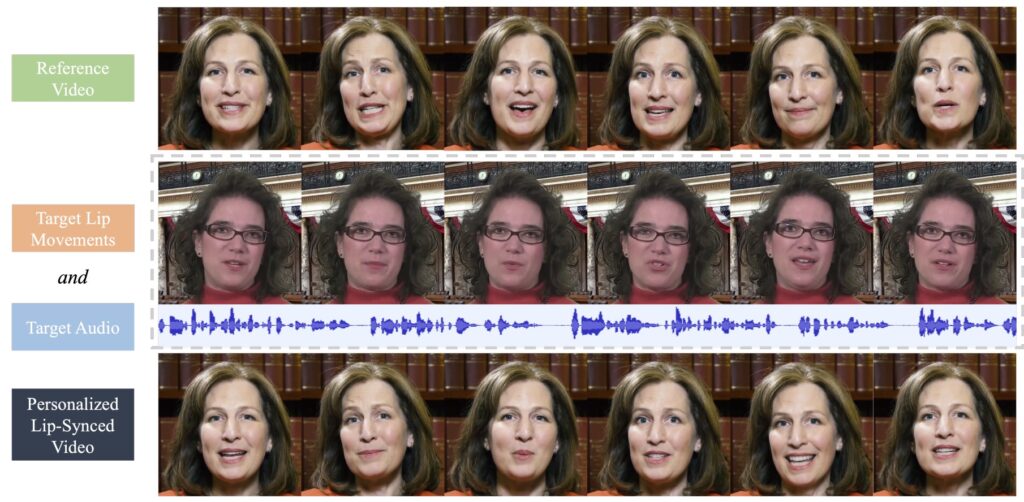
PersonaTalk 是由字节跳动开发的一种专为实现高保真和个性化视觉配音的技术框架,也就是专门用来给视频人物进行AI配音。它不仅能够让人物的嘴巴动作和声音完全同步,还能保持人物的个性特征,比如独特的说话风格和面部细节。
它通过一个基于注意力机制的两阶段系统,在生成与音频同步的嘴部动作的同时,保持说话者独特的个性特征(如说话风格和面部细节)。其目标是解决传统配音技术难以同时确保口型同步和个性保留的挑战。
它能做到:
- 声音同步嘴型:当你给一个视频加上新的声音时,PersonaTalk可以让人物的嘴巴动作和声音完全匹配,和新的语音说话口型嘴唇一样。
- 保留人物特点:在生成新视频时,它会尽量保留人物原本的说话方式、脸型、表情等细节,让视频看起来更加真实和自然。
- 适用于不同人物:它不需要大量的数据来单独训练特定的人物,可以适应不同的人物和场景。
PersonaTalk 主要功能
- 音频驱动的个性化视觉配音:能够根据输入的音频和参考视频生成同步的视觉配音,不仅让嘴唇动作与音频完美匹配,还能保留说话者的个性特点,比如说话的速度、语调和表情。这让生成的视频更加真实和个性化。
- 风格感知的唇形同步:PersonaTalk 会在生成唇部动作时将说话者的独特说话风格加入音频特征中,从而让唇形动作不仅仅是机械的同步,而是带有说话者的风格,比如轻松、严肃或激动的语气,让配音更生动。
- 双重注意力面部渲染:通过“双重注意力”机制,PersonaTalk 能够分别处理唇部和面部的纹理,确保每个细节都能真实呈现,比如牙齿的清晰度、面部轮廓的准确性、肤色和妆容的保留。这样,生成的人脸视频看起来更加自然和细腻。
- 多样化和一致性生成:在生成视频时,会根据不同的参考帧动态选择合适的画面,这样既能保证视频中的说话者动作一致性,又能在不同场景下展现多样性,比如不同角度、光线和背景的变化。
- 无需个性化微调的通用框架:可以在不同说话者之间直接应用,不需要额外的个性化调整。它能够适应多种说话者,适合广泛的应用场景,比如新闻播报、虚拟主持人或多语言配音。
- 多维度评价与优化:PersonaTalk 不仅关注唇形同步的准确性,还从视觉质量和个性保持等多个维度对生成效果进行评估和优化,确保每个生成结果都达到最佳状态。这让它在各种测试中都表现出色,得到用户的好评。
技术方法
模型架构
- 两阶段架构:
- 风格感知几何构建:首先提取视频中说话者的三维面部几何信息,并通过混合几何估计法学习说话者的说话风格,将其嵌入音频特征。之后,使用交叉注意力机制将音频特征与几何特征结合,实现唇形同步。
- 双重注意力面部渲染:该阶段利用双重交叉注意力机制分别处理唇部和其他面部区域的纹理采样。唇部注意力从参考帧中提取与唇部相关的纹理,而面部注意力则负责生成其余的面部纹理,从而保留面部的精细细节。
也就是PersonaTalk 先用AI分析视频中人物的3D脸型,然后再对脸部进行细致的渲染。这样既保证嘴巴动得对,也能保留人物的脸部细节。
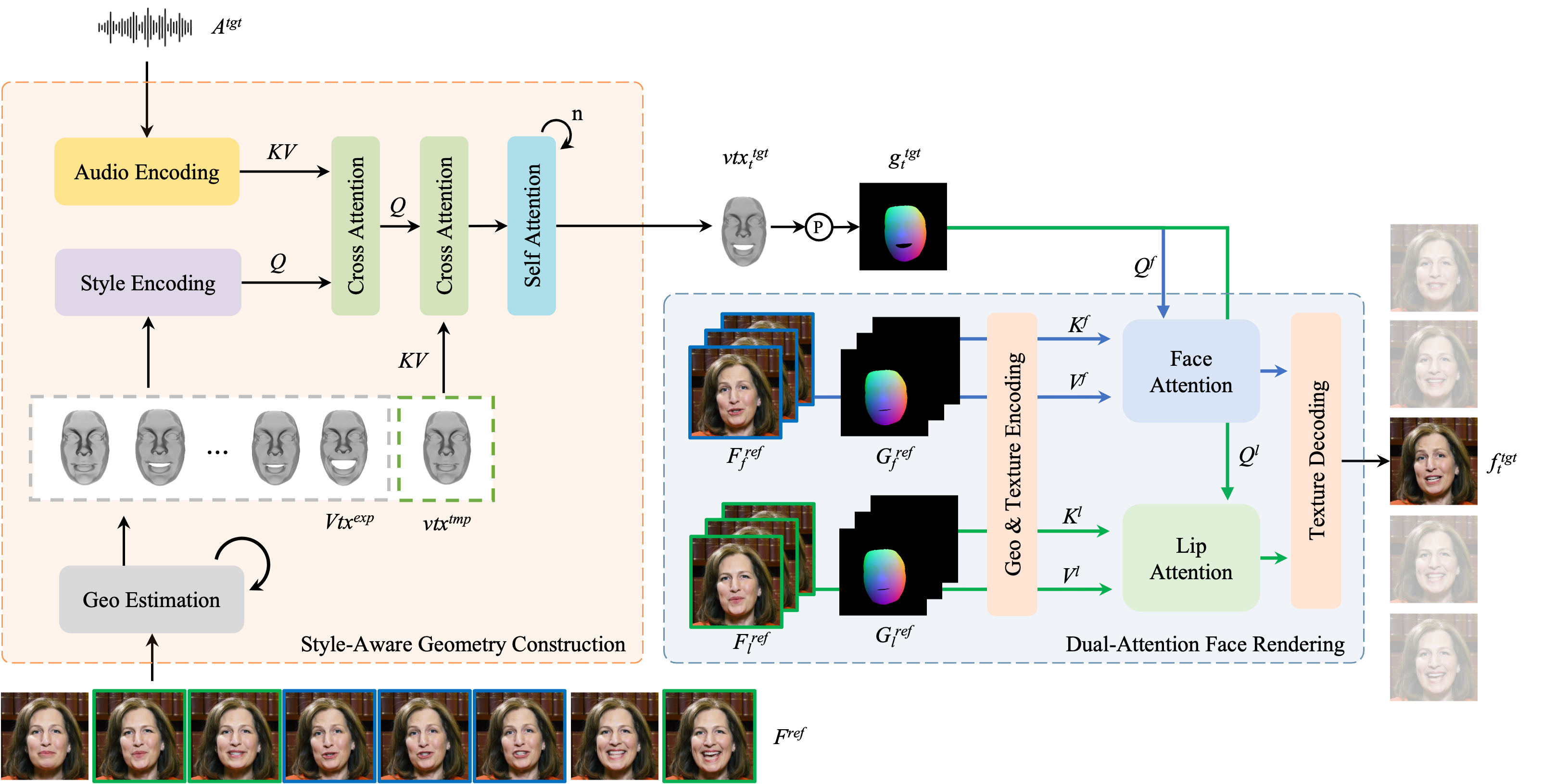

1. 几何构建(Style-Aware Geometry Construction)
- 这一步的目的是从视频中提取出说话者的3D面部几何信息,并与音频同步。具体技术方法包括:
- 3D面部几何提取:
- 通过使用一个“混合几何估计方法”,将视频中的面部信息转化为3D面部几何数据,包括面部的形状、表情和姿态。
- 这种几何建模让嘴型的生成更加精准,也便于后续渲染个性化面部细节。
- 音频编码与风格注入:
- 利用预训练的音频编码器,将音频信号转化为特征表示。
- 通过从几何数据中提取的统计特征来学习说话者的个性化风格,并将其嵌入到音频特征中。这一步通过交叉注意力层来实现,使得生成的口型不仅同步,还带有个性化的说话风格。
- 生成口型同步的几何形状:
- 基于音频特征和3D几何信息,通过多层交叉注意力和自注意力机制,生成口型同步的面部几何。
- 3D面部几何提取:
2. 面部渲染(Dual-Attention Face Rendering)
- 这一步的重点是将口型同步的几何数据转化为真实的人物面部,并保留细节。具体方法包括:
- 双重注意力机制(Dual-Attention Mechanism):
- 使用两种注意力机制,分别处理“嘴部”和“面部其他部分”的细节:
- 口部注意力:专注于嘴唇及相关区域的细节渲染,确保嘴型的精确同步和纹理清晰。
- 面部注意力:负责脸部其他部分的细节渲染,如脸颊、皮肤纹理、脸型轮廓等,以保持面部的整体一致性。
- 使用两种注意力机制,分别处理“嘴部”和“面部其他部分”的细节:
- 参考帧选择策略:
- 在渲染过程中,会动态选择多个参考帧来采样嘴部和面部的纹理。为了减少模糊和闪烁现象,口部参考帧的选择会基于嘴巴张开程度的排序,而面部参考帧则基于相邻帧的稳定性选择。
- 纹理解码(Texture Decoding):
- 在完成纹理采样后,通过一个几何感知的纹理解码器将面部图像从特征空间解码到像素空间,确保面部细节的高度保真。
- 双重注意力机制(Dual-Attention Mechanism):
3. 风格感知的音频编码
- PersonaTalk 通过从3D几何中提取的统计特征来学习说话者的个性化说话风格,并将这种风格嵌入到音频特征中。
- 这项创新使得模型能够在配音时保留独特的说话方式,让生成的视频更自然。
4. 双重注意力的面部渲染
- PersonaTalk 使用了一种双重注意力机制,分别针对嘴部和面部进行渲染:
- 口部注意力:专注于嘴唇和口型的纹理渲染,确保口型的高保真度。
- 面部注意力:处理面部其他部分的纹理,保留皮肤、牙齿、脸部轮廓等细节。
- 这种设计能更好地保留面部复杂细节,同时提高渲染效果的稳定性和逼真度。
4. 基于参考帧的动态选择策略
- 在面部渲染阶段,PersonaTalk 引入了基于参考帧的动态选择策略,通过从不同的参考帧中提取最相关的纹理,提高了视觉效果的保真度和稳定性。
- 这种方法减少了纹理模糊和嘴唇闪烁等常见问题,实现了更好的视觉保真度。
5. 多任务学习与通用适配
- PersonaTalk 通过多任务学习策略,在不进行个性化微调的情况下,能够实现通用适配,在不同人物之间切换时依然保持高质量的配音效果。
- 这使得PersonaTalk在适应不同的人物和场景时比传统方法更高效、更灵活。
案例展示:
保持口型同步视觉配音,同时保留个人的谈话风格和面部细节
Multilingual Translation 多语言翻译
泰勒斯威夫特
原版英文
翻译成中文视频
翻译成德语
成龙翻译案例
原版英文视频
翻译为日语
翻译为德语
Open Online Courses 开放在线课程
Animation 动画片
和其他项目比较