OpenAI 宣布推出了一个名为 large-v3-turbo(简称 turbo)的新 Whisper 模型。这是 Whisper large-v3 的优化版本,将解码器层数从大型模型的 32 层减少到与 tiny 模型相同的 4 层。此优化版本的开发受到了 Distil-Whisper 的启发,后者表明使用较小的解码器可以显著提升转录速度,同时对准确性的影响较小。
速度比 large-v3 快 8 倍,但质量几乎没有下降!
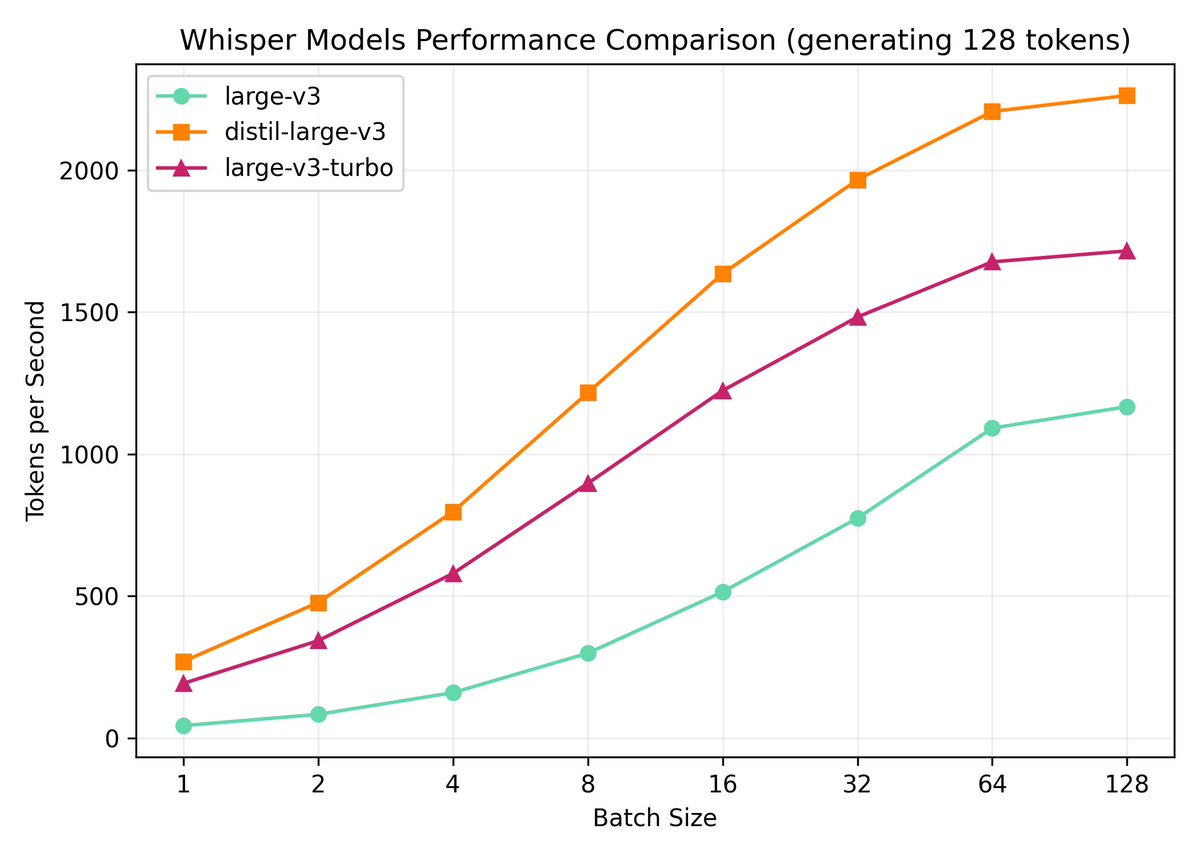

Whisper large-v3-turbo 主要功能和特点:
- 更少的解码器层数:
- 与 Whisper large-v3 相比,large-v3-turbo 只使用了 4 个解码器层,而 large-v3 使用了 32 个解码器层。较少的解码器层数使得模型在保持相对高准确度的同时,显著提高了处理速度。
- 优化的速度表现:
- Turbo 模型的语音转录速度比 tiny 模型更快,是 Whisper 系列模型中速度与准确性兼顾的“最佳选择”。通过使用更小的解码器层数,该模型提升了实时转录的能力。
- 通过减少解码层数和启用 torch.compile,推理速度可提升高达 4.5 倍,进一步提高了模型的效率,非常适合需要低延迟的应用场景。
- 多语言支持:
- 支持 99 种语言的语音转录,表现出色,并且与大型数据集兼容,包括 FLEURS 和 Common Voice 数据集,尤其在高质量录音上效果更佳。
- 跨语言的高效表现:
- Turbo 模型的跨语言转录表现与 large-v2 相当,但在一些语言(如泰语和粤语)上表现较弱。在一些录音质量较高的数据集(如 FLEURS)上,turbo 模型的表现优于 Common Voice 数据集。
- 更快的自动语音识别 (ASR):
- 结合最新的技术补丁(#2359),turbo 模型在使用 F.scaled_dot_product_attention(缩放点积注意力机制)时,能进一步提升自动语音识别的速度。
- 专注于转录任务:
- Turbo 模型专为多语言转录任务微调,不适合翻译任务,因为训练时不包含翻译数据。它在纯语音转录方面的表现更为优异,但翻译任务表现较差。
- 使用与集成方便:
- 开发者可以通过简单的 Python 包更新或 Whisper 的命令行工具默认使用 turbo 模型,使得其在实际应用中更易于集成。
GitHub:https://github.com/openai/whisper/discussions/2363
模型下载:https://huggingface.co/openai/whisper-large-v3-turbo
在线体验:https://huggingface.co/spaces/hf-audio/whisper-large-v3-turbo