
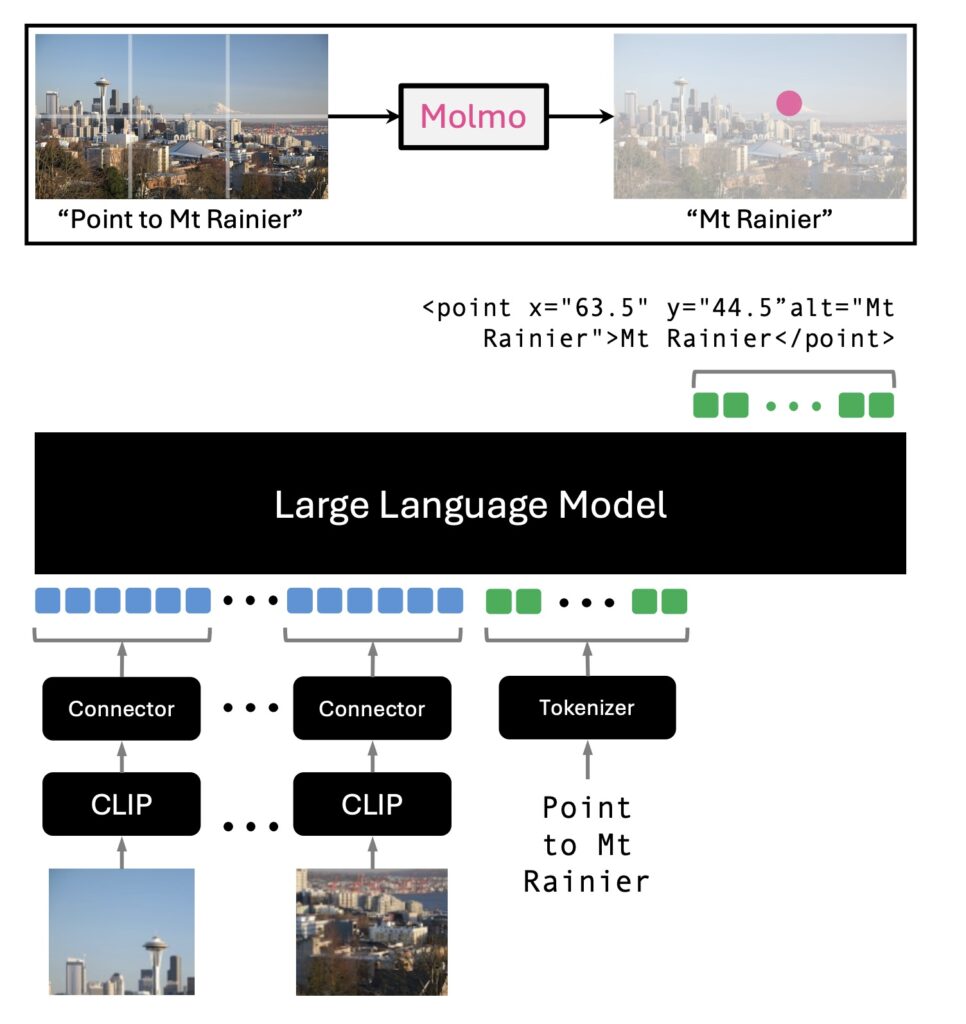
Molmo 一个开源的先进多模态人工智能模型,旨在提高开放系统在性能上与专有系统(如商业模型)之间的竞争力,特别是在学术标准和人类评估方面的表现。Molmo 模型在性能上优于体积大十倍的其他模型。
Molmo基于Qwen2-72B,使用OpenAI的CLIP作为视觉骨干,增强了模型处理图像和文本的能力。
Molmo 的目标是突破当前多模态模型的局限,这些模型通常只是将多模态数据(如图像和文本)转化为自然语言。Molmo 通过引入指向功能,使模型能够更深入地与物理和虚拟环境互动,从而支持更复杂的应用场景,例如人机交互、增强现实等。这种能力使得未来的应用能够更灵活、智能地处理真实世界的信息。
在同类大小的多模态模型中,Molmo-72B表现优越,获得最高的学术基准分数,并在人类评估中排名第二,仅次于GPT-4o。

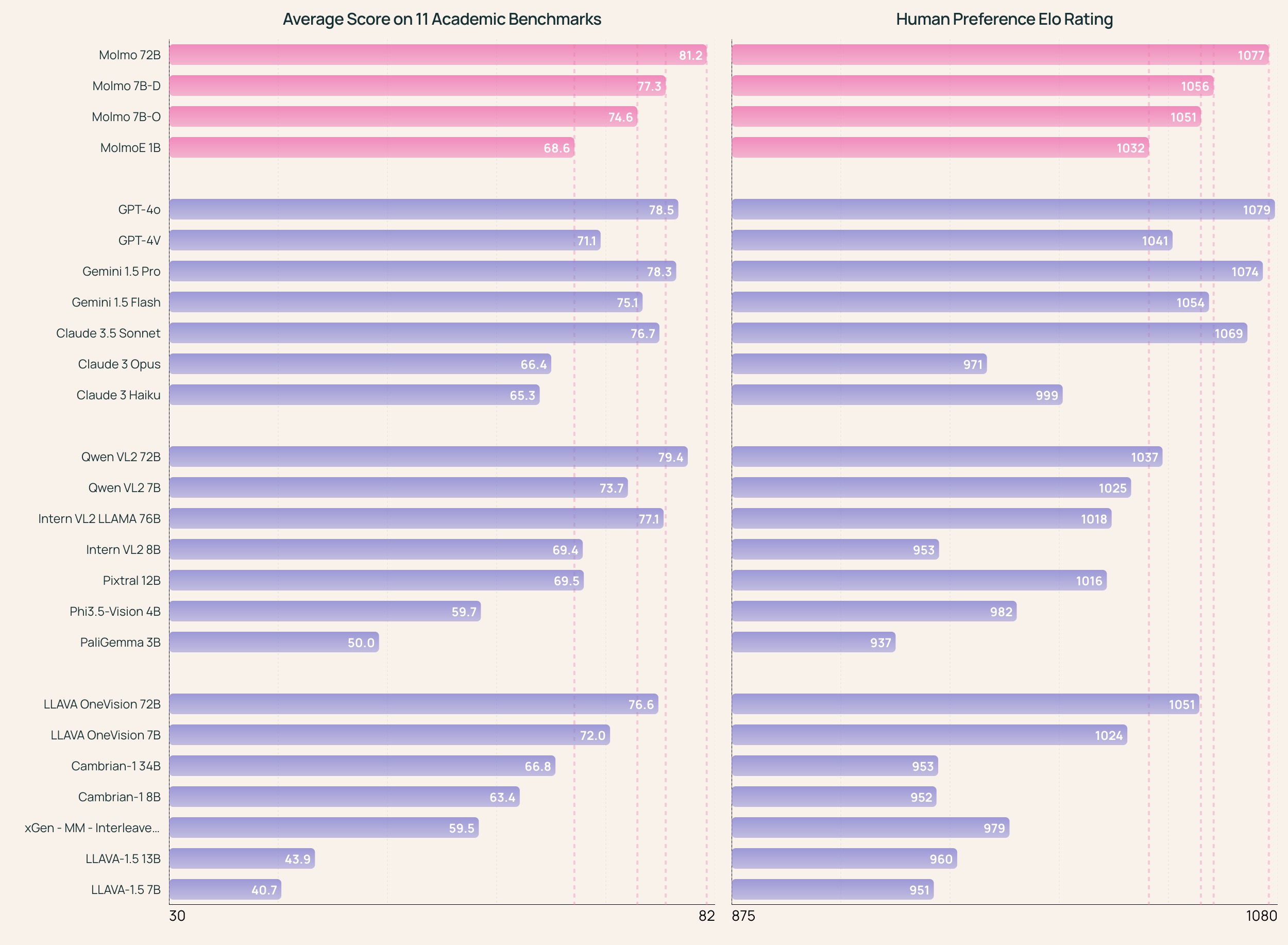
Molmo在开源权重和数据模型中表现最佳,能够与一些专有系统(如GPT-4o、Claude 3.5和Gemini 1.5)相媲美。


Molmo的能力
- 图像理解与生成:
- 图像描述:Molmo能够生成高质量的图像描述,理解图像内容并将其转化为自然语言。例如,模型能够识别图像中的物体、场景和活动,并生成准确的描述。
- 视觉问答:支持用户提出与图像相关的问题,模型能够根据图像内容提供准确的答案,展现出强大的理解能力。
- 多模态交互:
- 文本与图像结合:用户可以同时输入文本和图像,Molmo能够有效融合这两种信息,生成综合性的输出。这种能力使得用户体验更加丰富和直观。
- 指向与交互:Molmo支持用户通过2D指向交互,增强了与视觉内容的互动能力,例如用户可以通过手势或点击与图像中的对象进行互动。
- 高质量数据处理:
- 人类注释数据集:Molmo使用的图像字幕数据集完全由人类注释者收集,确保了数据的准确性和多样性,提升了模型的训练效果和性能。
- 动态适应性:模型能够根据输入的变化自动调整处理方式,适应不同类型的用户交互和数据格式。
- 灵活的应用场景:
- 教育:在教育领域,Molmo可用作智能教学助手,帮助学生理解图像和文本内容,增强学习体验。
- 娱乐:支持多种娱乐应用,包括游戏、虚拟现实体验和创意内容生成,提供沉浸式的用户体验。
- 医疗:在医疗图像分析中,Molmo能够辅助医生理解医学图像,提供诊断支持。
数据集特点
- 规模:
- 收集方式:Molmo的密集描述数据集是通过人工注释者使用语音描述图像而收集的。这种方法的优点是能够获取更详细的描述,避免了文字描述中常见的简略问题。
- 描述细节:注释者被要求在60到90秒内详细描述他们所看到的图像,包括空间位置和对象之间的关系。通过这种方法,收集到的描述信息更加全面且细致。
- 数据量:总共收集了712,000张图像的详细音频描述,涵盖了50个高层主题。这种密集的数据集支持多模态预训练,使得模型能够更好地理解和生成图像描述。
- 注释质量:
- 数据集中的图像描述是由人类注释者使用语音描述收集的,这确保了描述的自然性和准确性。
- 避免依赖现有VLM:在数据收集过程中,Molmo团队避免使用现有的视觉-语言模型,以确保构建出一个真正从零开始的高性能模型。
- 收集挑战:从人工注释者收集密集描述数据是一项挑战,传统上,简单的图像描述往往只会提及少量视觉元素。因此,Molmo的创新收集方法显得尤为重要,确保了收集的数据在细节和质量上的优势。
- 多样性:
- 数据集设计旨在覆盖广泛的场景和内容,支持多种类型的用户交互,包括问题回答和图像描述生成。
- 数据源:该数据混合包含标准的学术数据集以及几种新收集的数据集,目的是使模型在特定任务上表现良好。
- 功能拓展:新收集的数据集使得Molmo能够执行一系列重要的功能,包括:
- 回答有关图像的通用问题
- 改善OCR(光学字符识别)相关任务,如阅读文档和图表
- 准确读取模拟时钟
- 指向图像中的一个或多个视觉元素,从而提供基于图像像素的自然解释。
性能表现

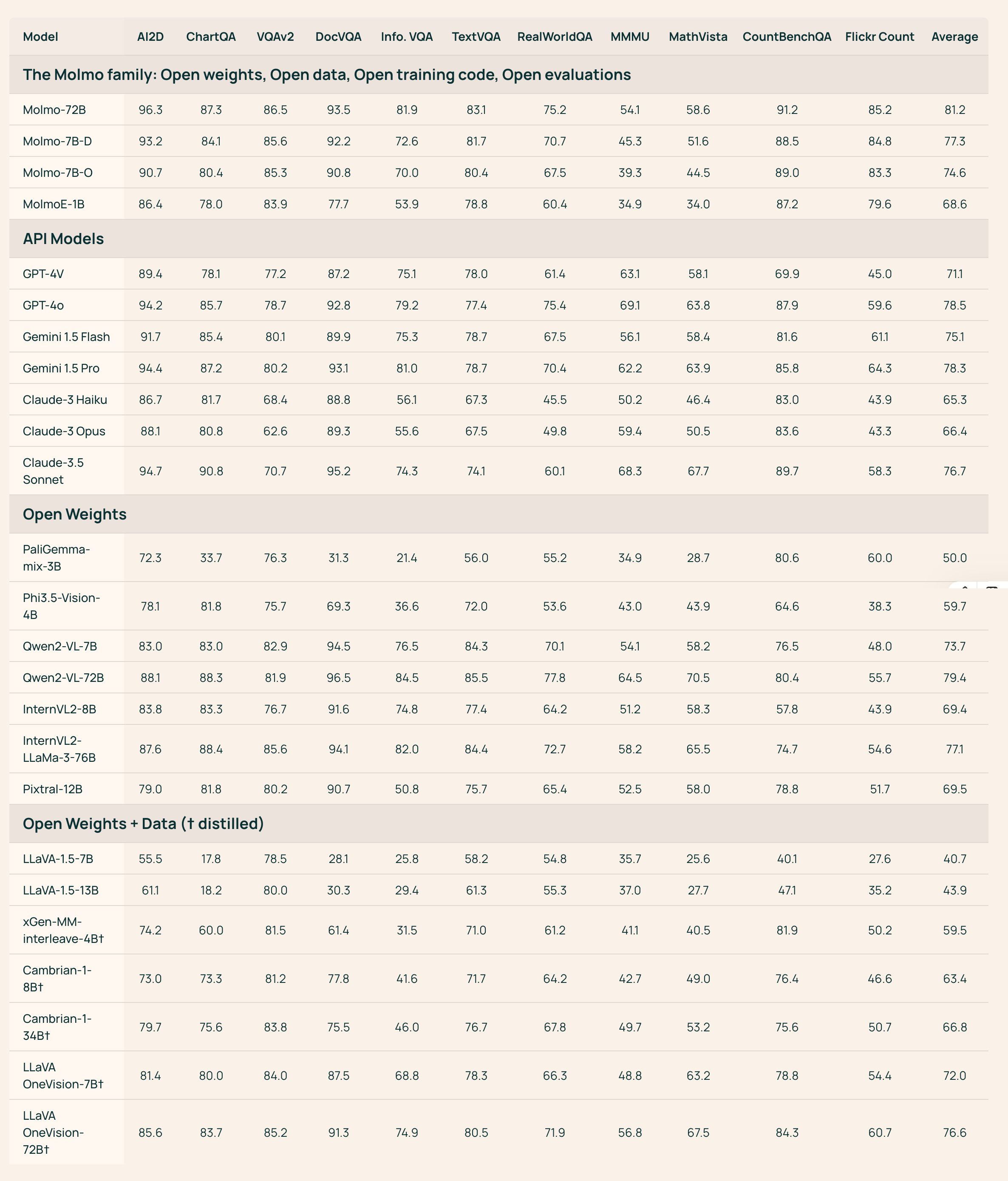
- 模型对比:
- Molmo在开源权重和数据模型中表现最佳,能够与一些专有系统(如GPT-4o、Claude 3.5和Gemini 1.5)相媲美。
- 基于评估:
- Molmo在多个学术基准测试中取得了优异成绩,采用了11个常用的学术基准进行评估。
- 通过人类评估方法收集的结果显示,Molmo在用户偏好排名中表现优越,收集了超过325,231个成对比较数据,使得该评估成为迄今为止最大的多模态模型人类偏好评估。
- 数据使用效率:
- 与传统的大型视觉-语言模型(通常基于数十亿图像文本对)相比,Molmo以不到100万对图像文本的数据训练,体现了数据质量优于数据数量的理念。
- 功能扩展能力:
- Molmo支持多种交互方式,如图像问答、文档阅读和指向特定视觉元素等,显示了其在实际应用中的多功能性。
官方介绍及更多演示:https://molmo.allenai.org/blog
模型下载:https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19