阿里云发布Qwen2.5 系列模型,最新发布的 Qwen2.5 系列中包括普通的大语言模型 (LLM) 以及针对编程和数学的专用模型:Qwen2.5-Coder 和 Qwen2.5-Math。
包括:
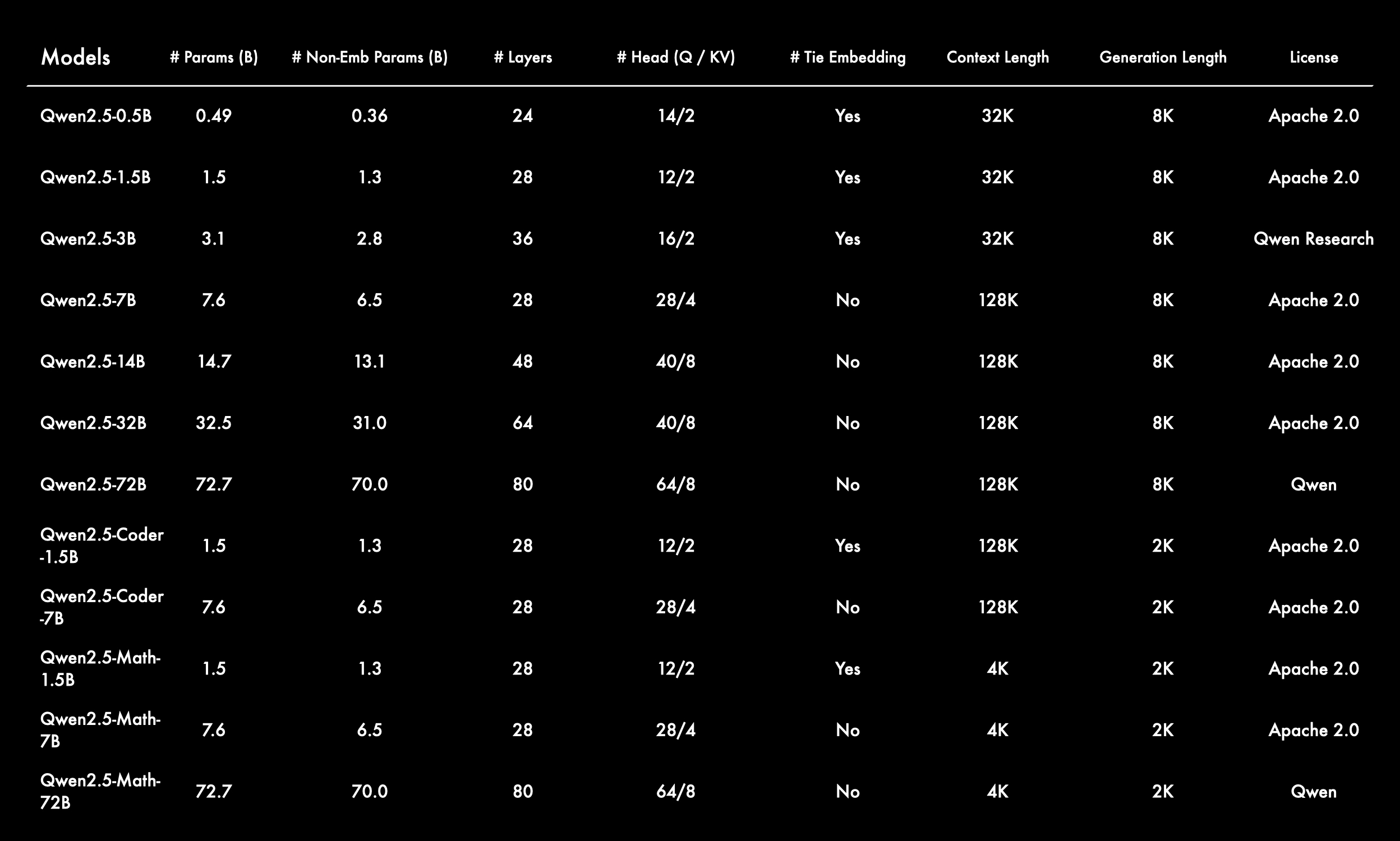
- Qwen2.5: 0.5B、1.5B、3B、7B、14B、32B 和 72B
- Qwen2.5-Coder: 1.5B、7B 和 32B(即将发布)
- Qwen2.5-Math: 1.5B、7B 和 72B
新的模型在指令跟随、生成长文本(超过 8K Tokens)、理解结构化数据(如表格)以及生成结构化输出(尤其是 JSON 格式)方面取得了显著进步。
Qwen2.5 模型更能适应不同的系统提示,提升了角色扮演和条件设定的能力。
与 Qwen2 类似,Qwen2.5 支持 128K Tokens,最大可生成 8K Tokens,且支持 29 种语言,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。

相比 Qwen2 系列,Qwen2.5 系列具有以下升级:
- 全面开源: 除继续开源 Qwen2 的四个模型(0.5B、1.5B、7B 和 72B)外,Qwen2.5 还新增了两个中等规模的高性价比模型 Qwen2.5-14B 和 Qwen2.5-32B,以及一个移动端模型 Qwen2.5-3B。这些模型与同类开源模型相比竞争力极强。
- 更大规模、更高质量的预训练数据集: 预训练数据集的规模从 7 万亿 tokens 扩展到 18 万亿 tokens。
- 知识增强: Qwen2.5 大幅提升了知识储备。在 MMLU 基准测试中,Qwen2.5-7B 和 72B 的表现分别从 70.3 提升到 74.2 和从 84.2 提升到 86.1。
- 编程能力增强: 通过 Qwen2.5-Coder 的技术突破,Qwen2.5 在编程能力方面得到了显著提升。Qwen2.5-72B-Instruct 在 LiveCodeBench、MultiPL-E 和 MBPP 基准测试中分别取得了 55.5、75.1 和 88.2 的分数。
- 数学能力增强: 整合 Qwen2-Math 技术后,Qwen2.5 的数学能力得到了快速提升。Qwen2.5-7B/72B-Instruct 在 MATH 基准测试中的成绩从 52.9/69.0 提升至 75.5/83.1。
- 更符合人类偏好: Qwen2.5 能够生成更符合人类偏好的响应。特别是 Qwen2.5-72B-Instruct 的 Arena-Hard 分数从 48.1 显著提升至 81.2,MT-Bench 分数从 9.12 提升到 9.35。
- 其他核心能力增强: Qwen2.5 在指令跟随、生成长文本(从 1k 提升至 8K tokens)、理解结构化数据(如表格)以及生成结构化输出(尤其是 JSON 格式)方面取得了显著进展。此外,Qwen2.5 模型在适应不同的系统提示方面表现更具弹性,增强了角色扮演和条件设定的能力。
专用模型的亮点:
- Qwen2.5-Coder:专注于编程任务,相较于前作 CodeQwen1.5,有更好的编程能力,支持多种编程语言,并能在 HumanEval 基准测试上取得优异表现。
- Qwen2.5-Math:Qwen2.5-Math 支持中英文,并结合多种推理方法,支持如链式思维(CoT)、程序思维(PoT)和工具整合推理(TIR),具备更强的数学推理能力。
性能提升
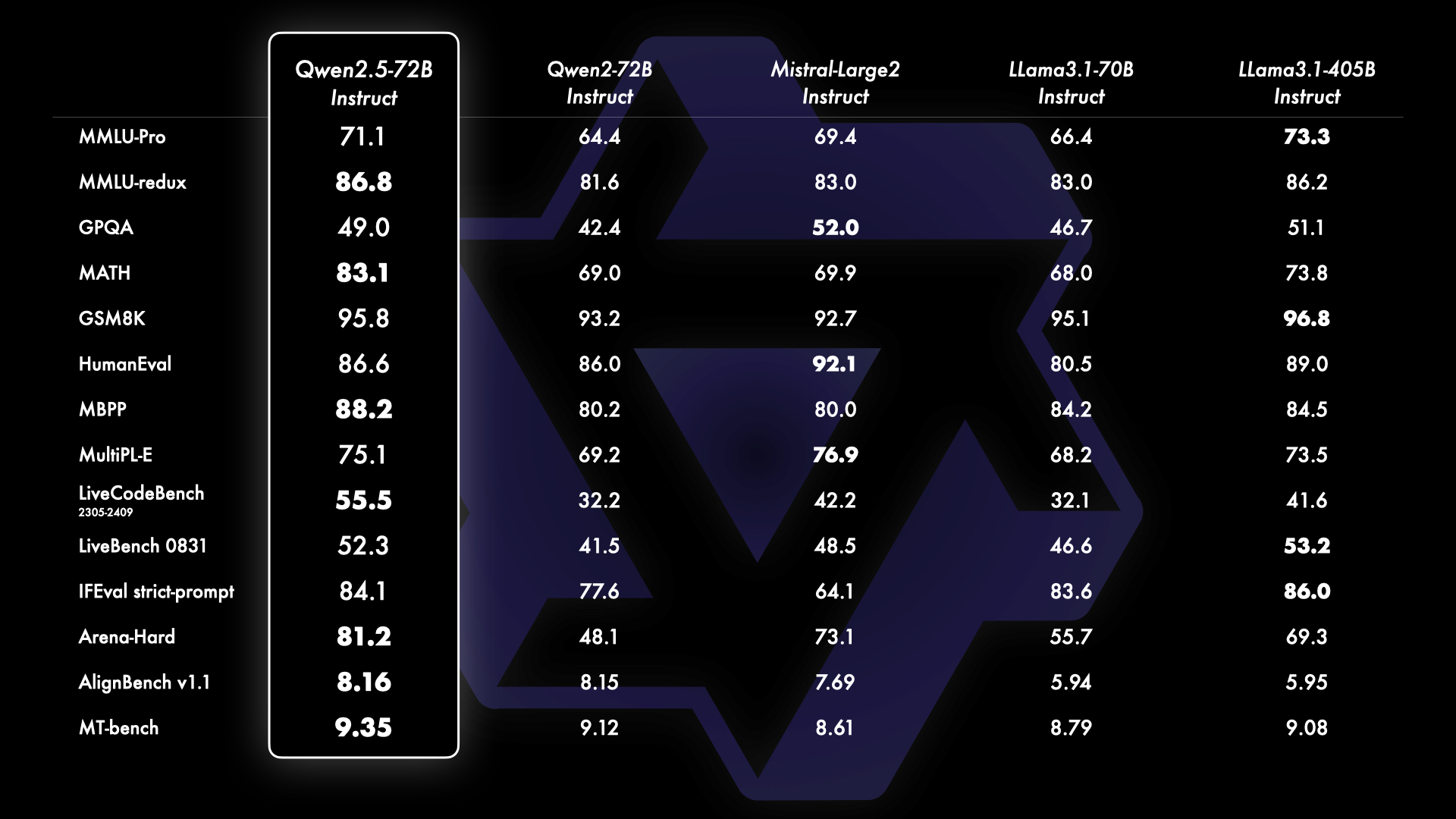

来自不同基准的指令调优版本的全面结果,评估了模型能力和人类偏好。
- Qwen2.5 系列模型在多项基准测试中表现优异,尤其是 72B 参数的模型在与 Llama-3.1-70B、Mistral-Large-V2 等开源大模型对比中取得领先。
- 编程模型 Qwen2.5-Coder 在编码任务上表现卓越,而 Qwen2.5-Math 的数学推理能力也超越了许多同类模型。
- 对比 Llama 和 GPT4-o:
- 在多个基准测试中,Qwen2.5-72B 在许多任务上表现出色,尤其是在与 Llama-3 和 Mistral-Large 等模型的对比中。尽管 Qwen2.5 在某些方面不如 GPT4-o 和 Claude-3.5-Sonnet,但在整体性能上保持了高度的竞争力,尤其是在开源领域。
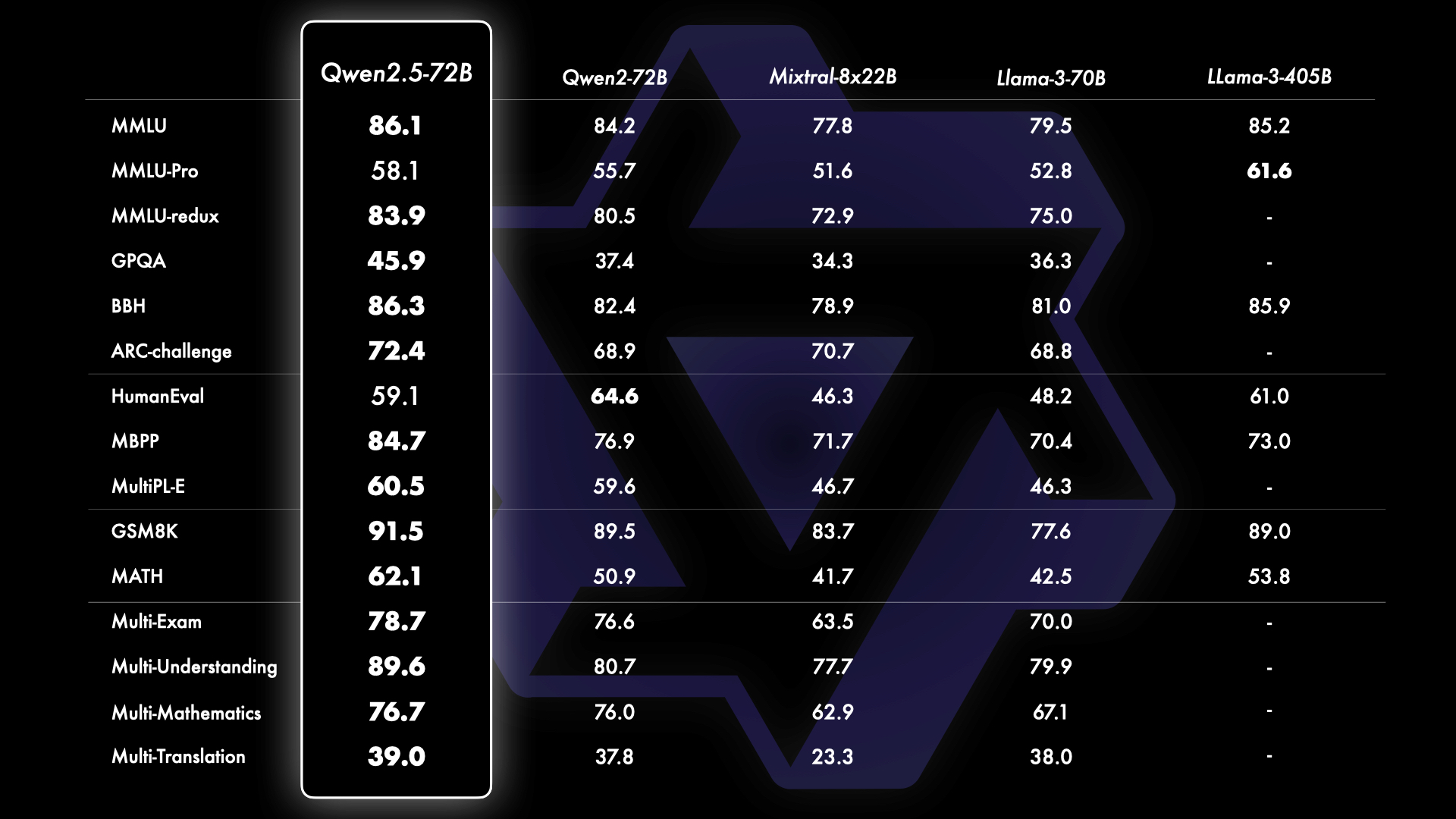
- 在多个基准测试中,Qwen2.5-72B 在许多任务上表现出色,尤其是在与 Llama-3 和 Mistral-Large 等模型的对比中。尽管 Qwen2.5 在某些方面不如 GPT4-o 和 Claude-3.5-Sonnet,但在整体性能上保持了高度的竞争力,尤其是在开源领域。
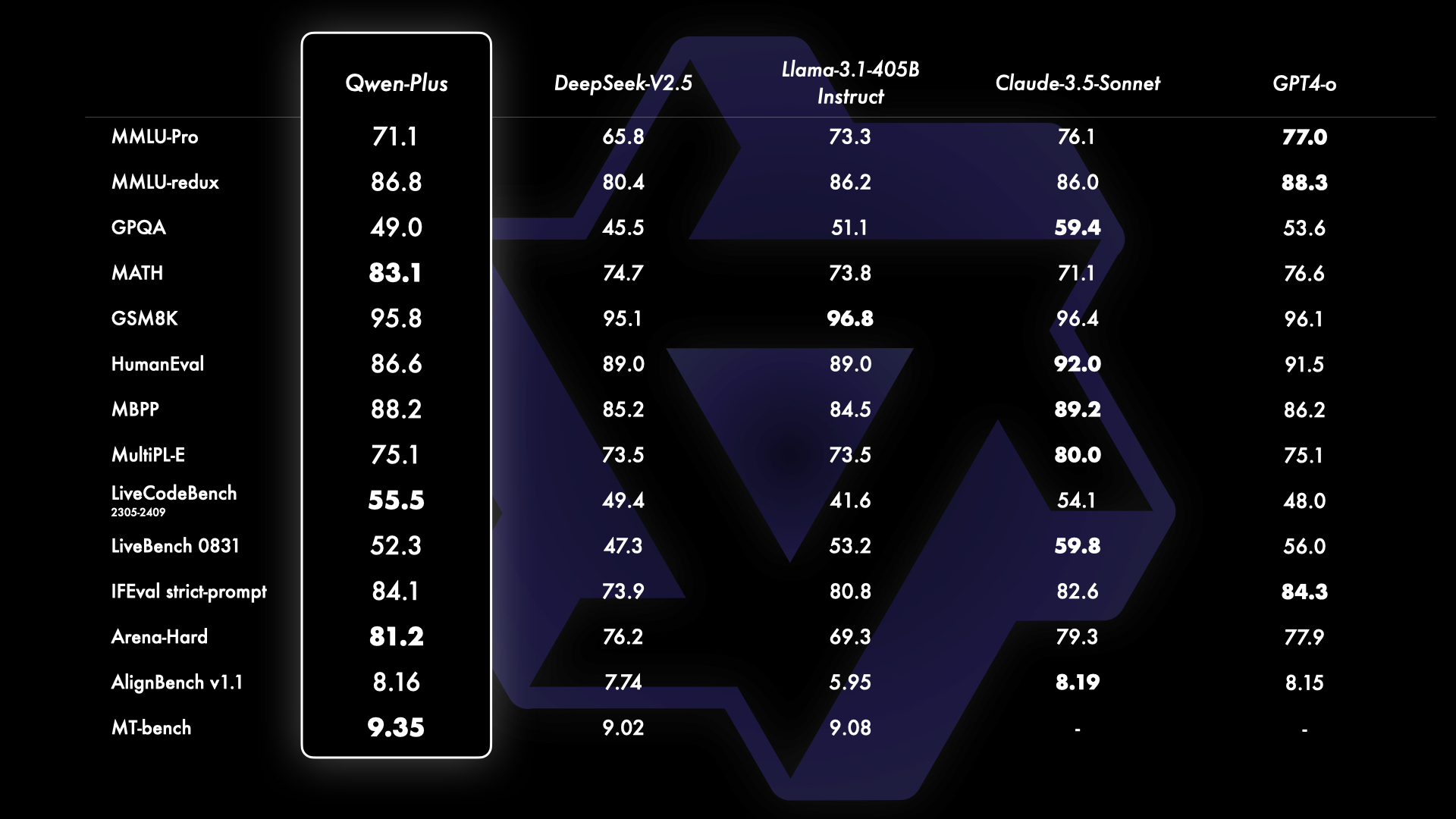
- Qwen-Plus:
- Qwen-Plus 作为 Qwen2.5 的 API 模型,在推理速度和响应成本上具有优势。与 Llama-3.1-405B 和 DeepSeek-V2.5 等模型对比中,Qwen-Plus 展示了良好的性能,特别是在成本效益方面表现突出。
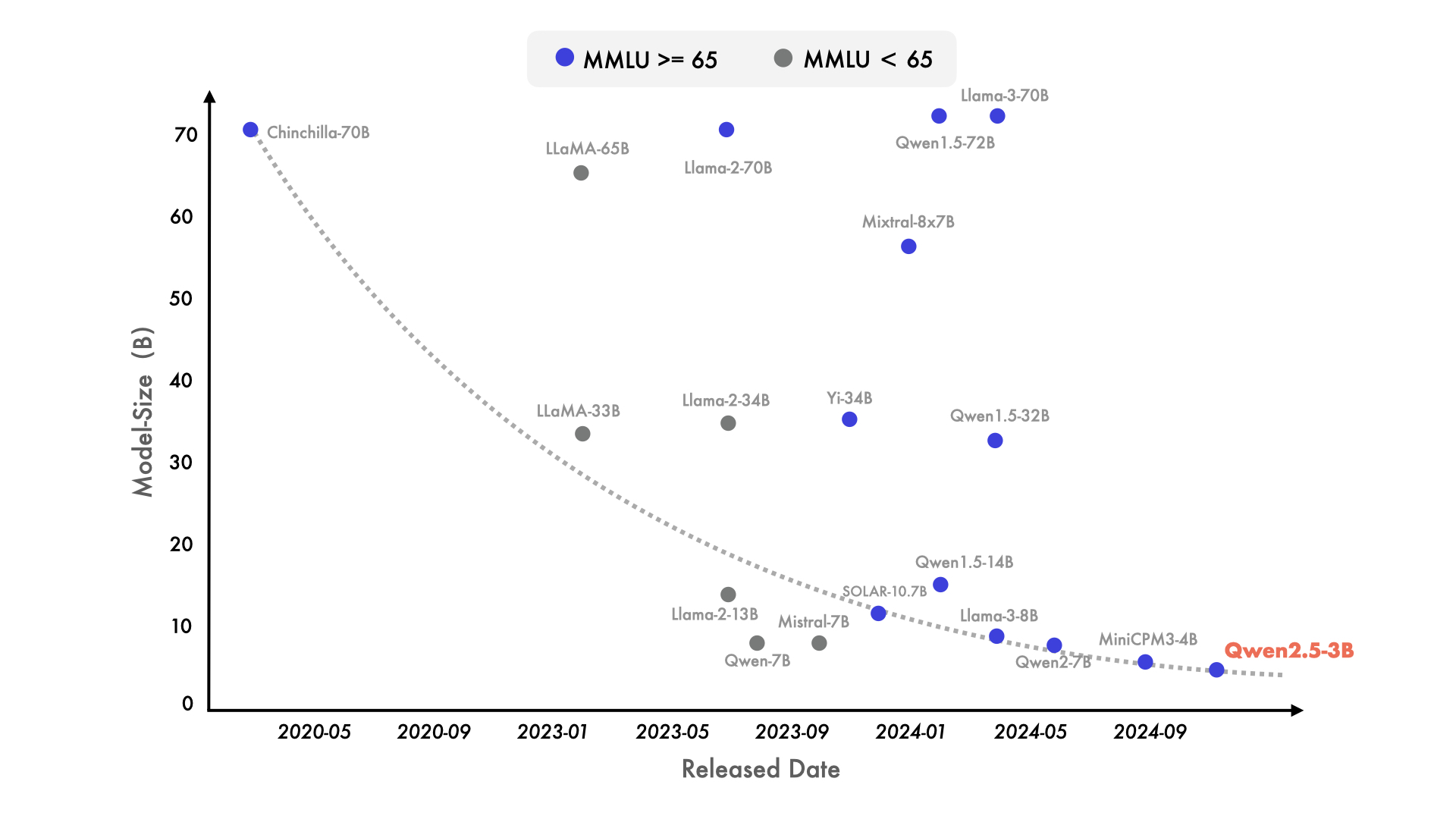
- 值得注意的是,尽管 Qwen2.5 的 3B 参数模型相对较小,但它在多个任务上依然表现出色,证明了随着知识密度的增加,小型模型在某些任务上可以与更大规模的模型竞争。Qwen2.5-3B 在 MMLU 中取得了超过 65+ 的高分,展示了其在处理多任务语言理解方面的高效性。
- Qwen-Plus 作为 Qwen2.5 的 API 模型,在推理速度和响应成本上具有优势。与 Llama-3.1-405B 和 DeepSeek-V2.5 等模型对比中,Qwen-Plus 展示了良好的性能,特别是在成本效益方面表现突出。
Qwen2.5-Coder
Qwen2.5-Coder 继 CodeQwen1.5 之后进一步增强了编码能力,并正式更名为 Qwen-Coder。该版本的主要改进包括:扩展代码训练数据规模,并在保留数学和通用任务能力的同时,大幅提升了编码任务的性能。
Qwen2.5-Coder 支持 128K Tokens 的上下文长度,涵盖 92 种编程语言,并在代码生成、多语言代码生成、代码补全和代码修复等多个代码相关评估任务中取得了显著进展。
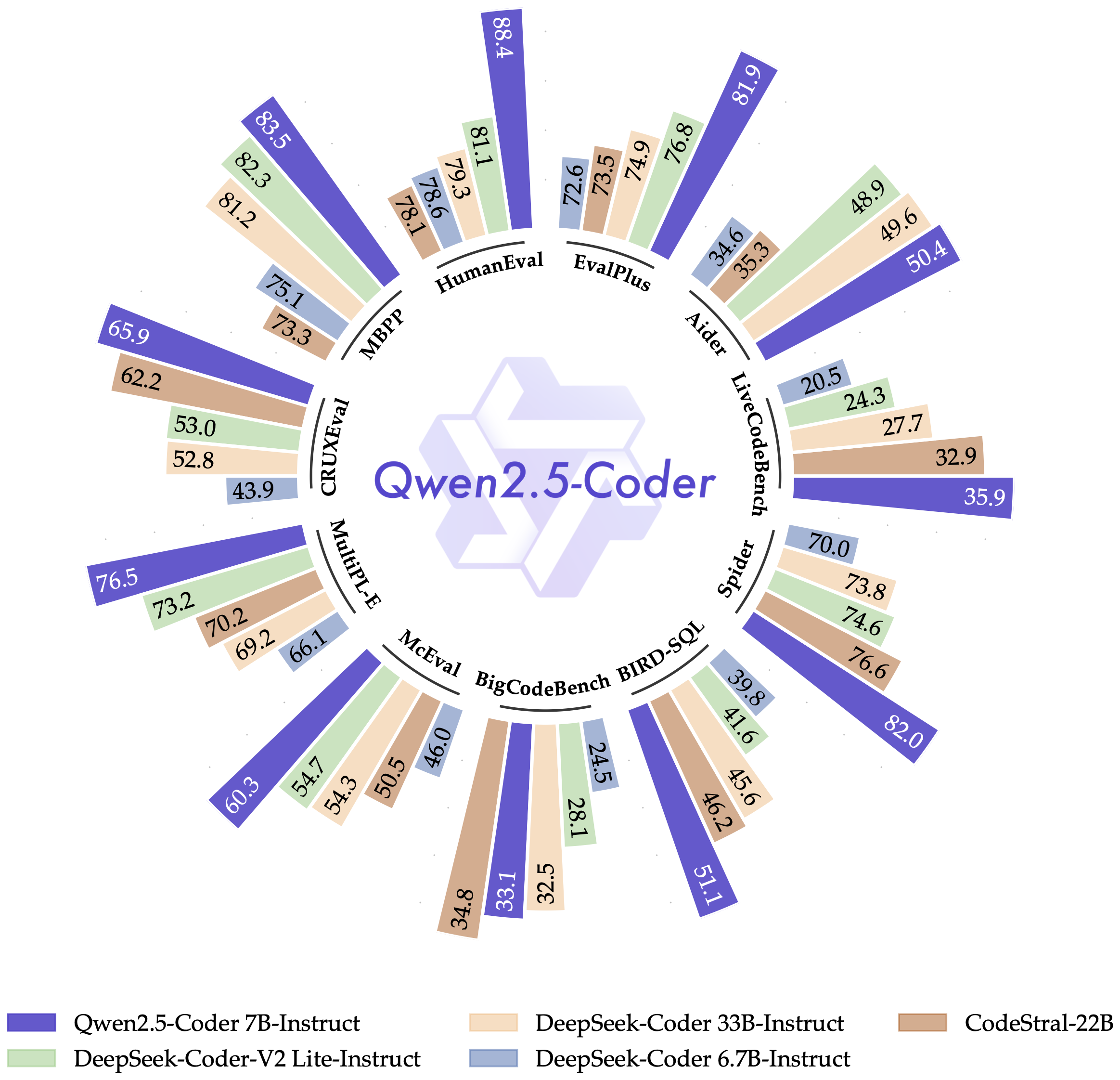

值得注意的是,Qwen2.5-Coder 的开源 7B 版本甚至超越了更大模型,如 DeepSeek-Coder-V2-Lite 和 Codestral,使其成为最强大的基础代码模型之一。除了代码任务外,Qwen2.5-Coder 在 GSM8K 和 Math 等评估中还表现出强大的数学能力。在通用任务方面,对 MMLU 和 ARC 的评估显示,Qwen2.5-Coder 保持了 Qwen2.5 的通用能力表现。
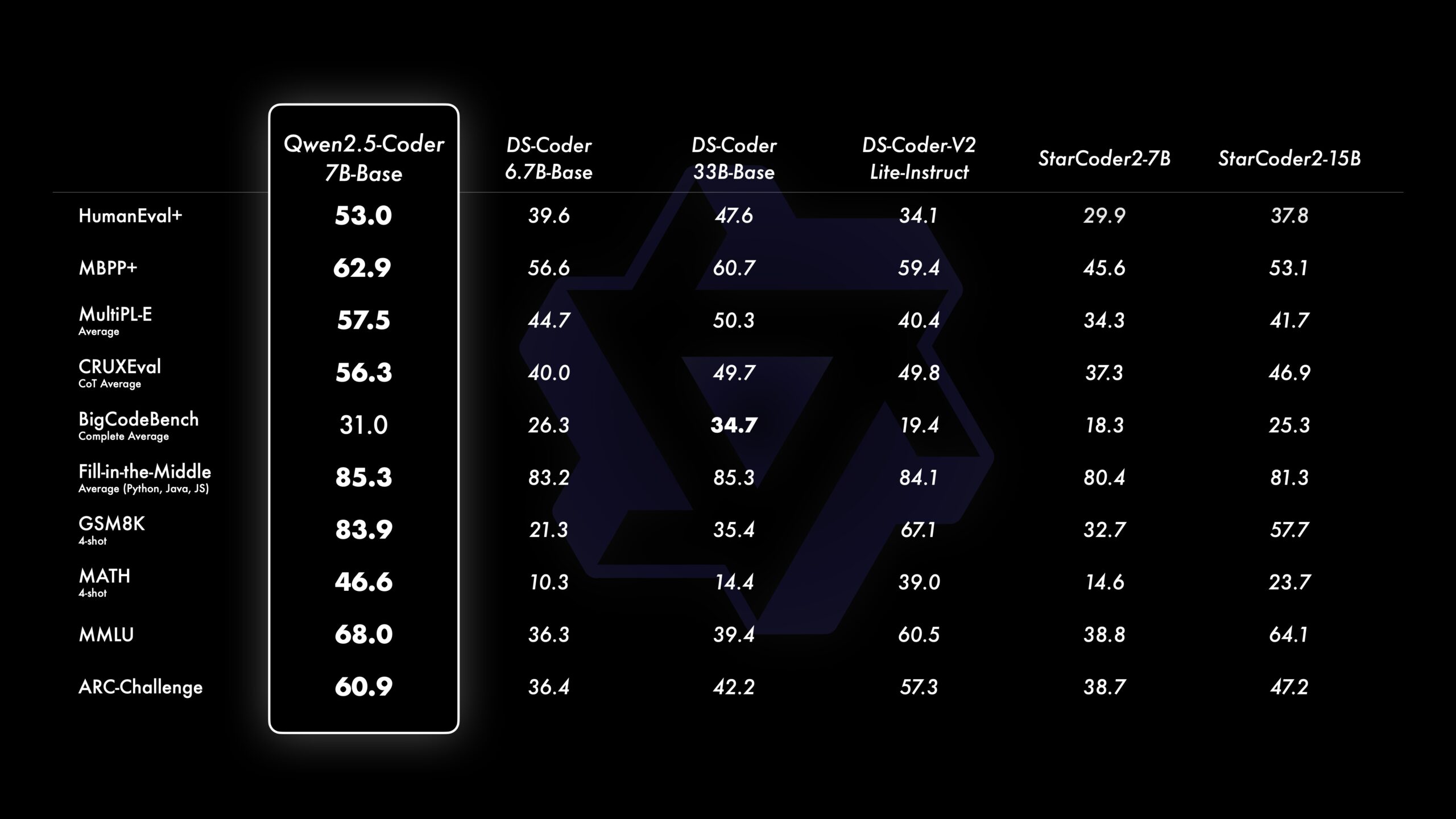

关键特点:
- 模型规模:提供三个模型规模,分别为 1.5B、7B 和即将发布的 32B 参数模型。
- 数据规模:训练数据扩展至 5.5 万亿 tokens,涵盖源码、文本代码和合成数据。
- 代码能力增强:在代码生成、多语言编程、代码补全和代码修复等任务上有显著提升,支持多达 92 种编程语言,并且 7B 模型表现优于一些更大规模的模型。
Qwen2.5-Coder-Instruct:指令微调模型
基于 Qwen2.5-Coder,我们使用指令数据对其进行了微调,推出了 Qwen2.5-Coder-Instruct。该指令微调模型不仅进一步提高了任务性能,还在多个基准测试中展现了出色的泛化能力。
Qwen2.5-Coder-Instruct 在几个关键领域表现出色:
- 多语言专家:我们使用 McEval 扩展了多语言评估,涵盖 40 多种编程语言。结果表明,Qwen2.5-Coder-Instruct 在许多编程语言(包括小众语言)中的表现非常出色。
- 代码推理:我们认为代码推理与通用推理能力密切相关。使用 CRUXEval 作为基准测试,结果表明 Qwen2.5-Coder-Instruct 在代码推理任务中表现出色。随着代码推理能力的提升,模型执行复杂指令的能力也随之增强,这促使我们进一步探索如何通过代码增强通用能力。
- 数学推理:数学是代码的基础,代码是数学的关键工具。Qwen2.5-Coder-Instruct 在代码和数学任务中均表现优异,被证明是一个“理科生”。
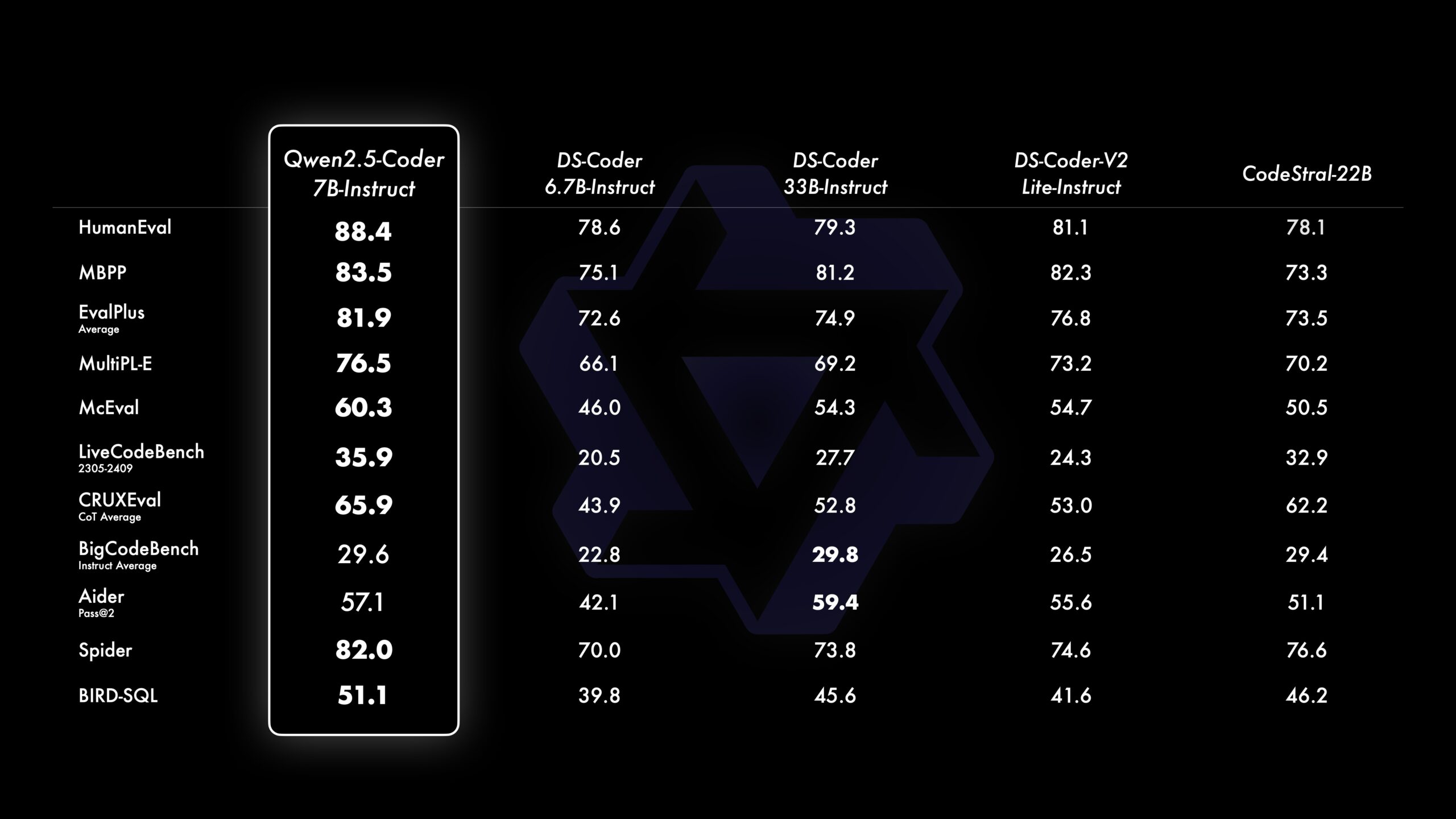
Qwen 团队正在准备发布 32B 版本的 Qwen2.5-Coder,以挑战更大的专有模型。同时,他们还在探索基于代码推理的更强大模型,推动代码智能的边界。
Qwen2.5-Math
Qwen2.5-Math 是专门为解决数学问题而设计的大语言模型,主要支持通过 链式思维(CoT) 和 工具集成推理(TIR) 解决中文和英文的数学问题。相比之前的 Qwen2-Math 系列,Qwen2.5-Math 在中英文数学测试中表现大幅提升。Qwen2.5-Math 显著提升了数学推理能力,特别是在复杂算法和符号计算任务中的表现。
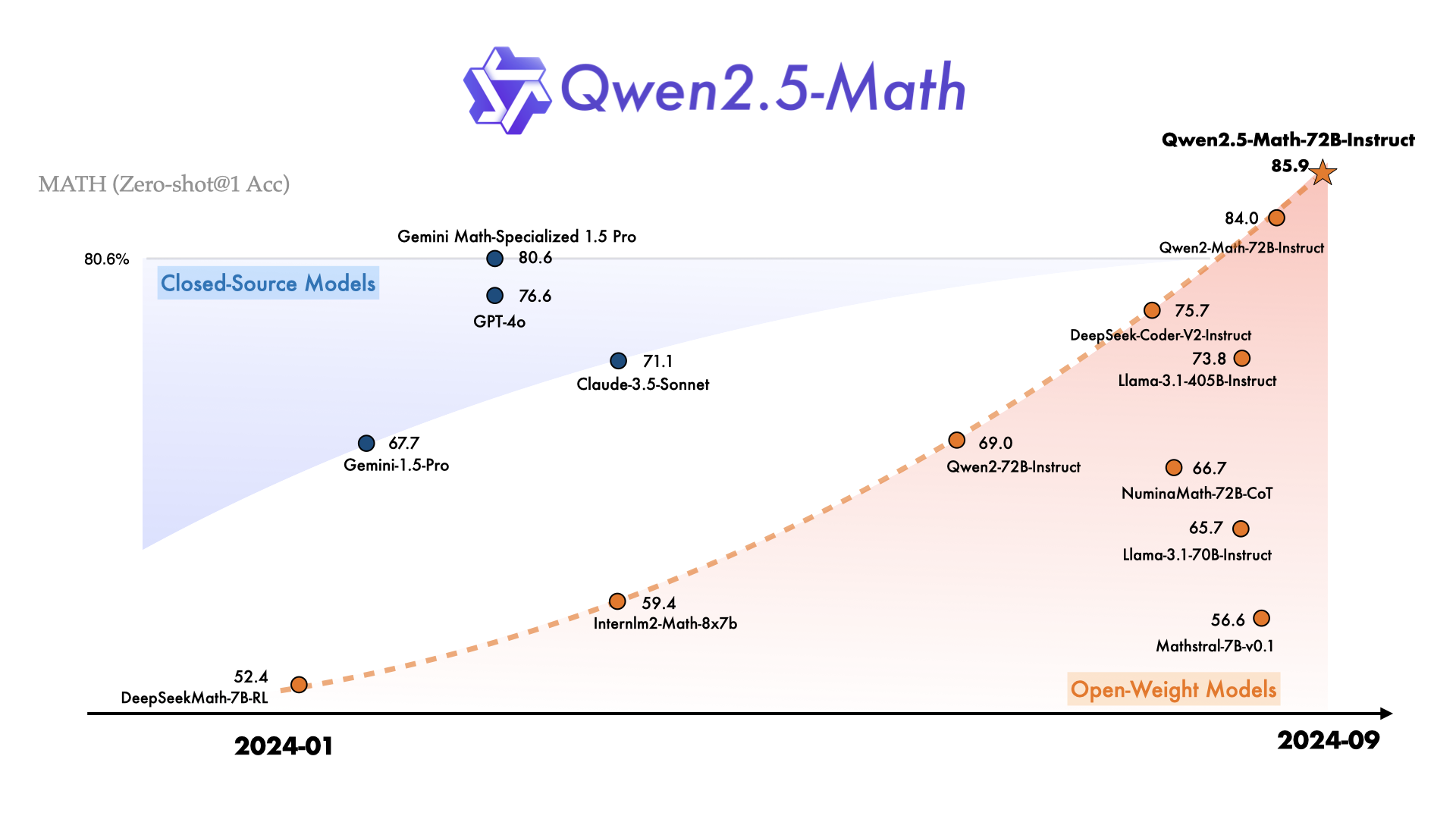
关键特点:
- 模型系列:包括基础模型(1.5B、7B、72B 参数)和指令调优模型(Instruct 版),以及数学奖励模型(Qwen2.5-Math-RM-72B)。
- 双语支持:除了英文数学问题外,现在还支持中文问题,能够在复杂的数学推理任务中表现优异。
- 性能提升:在多项数学基准测试(如 MATH、GSM8K、中国高考数学)上,Qwen2.5-Math 系列模型都大幅超过了 Qwen2-Math 系列,特别是在 TIR 模式下,最高分达 92.9。
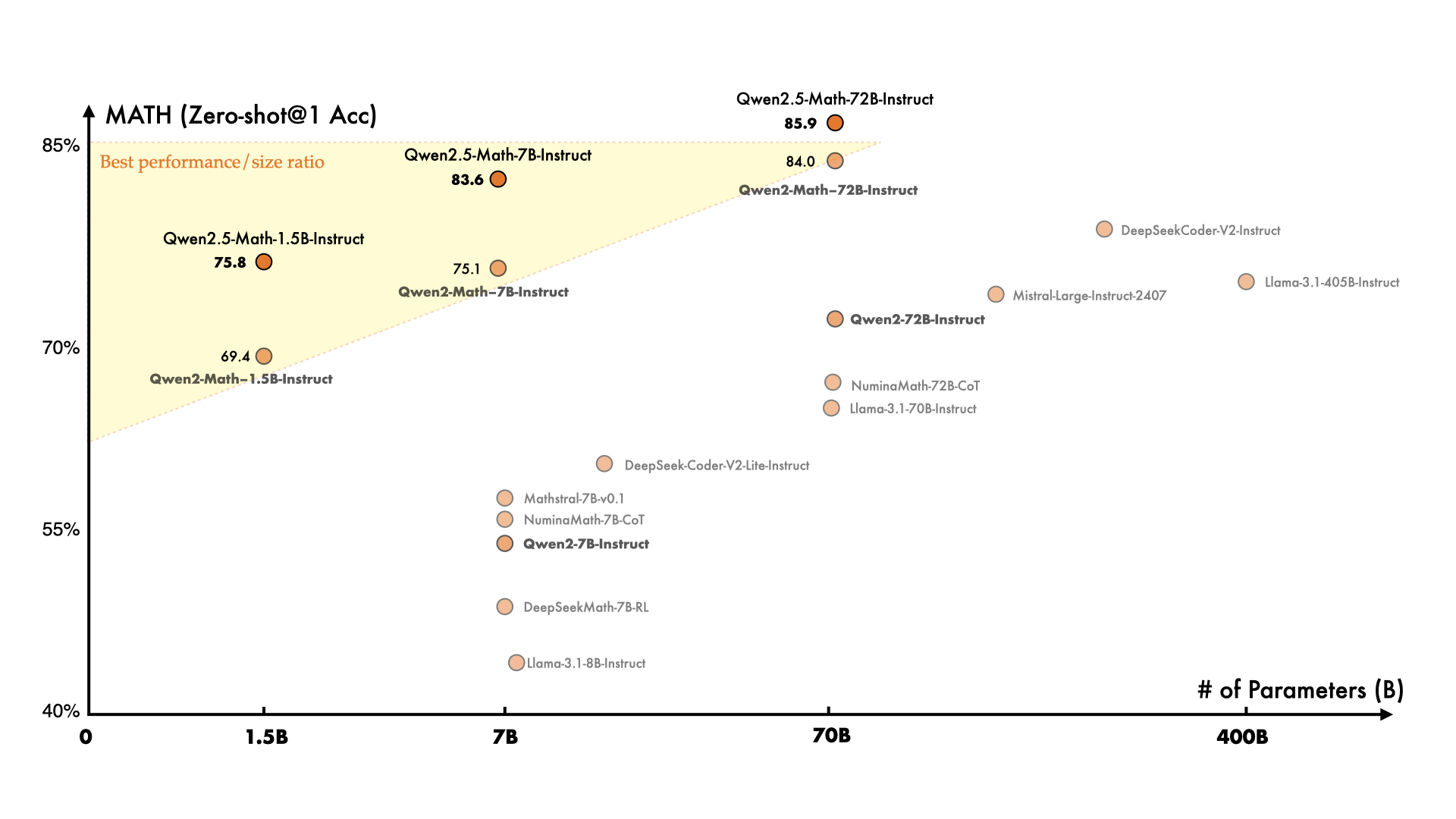
Qwen2.5-Math 系列扩展了支持使用思维链和工具集成推理(TIR)来解决中英文数学问题。与 Qwen2-Math 系列模型相比,Qwen2.5-Math 系列模型在中英文数学基准测试中取得了显著的性能提升。模型表现
- 在多项复杂的数学基准测试(如 AIME2024、AMC2023)中,Qwen2.5-Math-72B-Instruct 模型的性能远超市面上其他开源模型和一些闭源模型(如 GPT-4o、Gemini)。
- Qwen2.5-Math 在数学竞赛级别问题中的表现尤为出色,甚至可以在较小的模型(如 1.5B 参数)下取得 80 分以上的成绩。
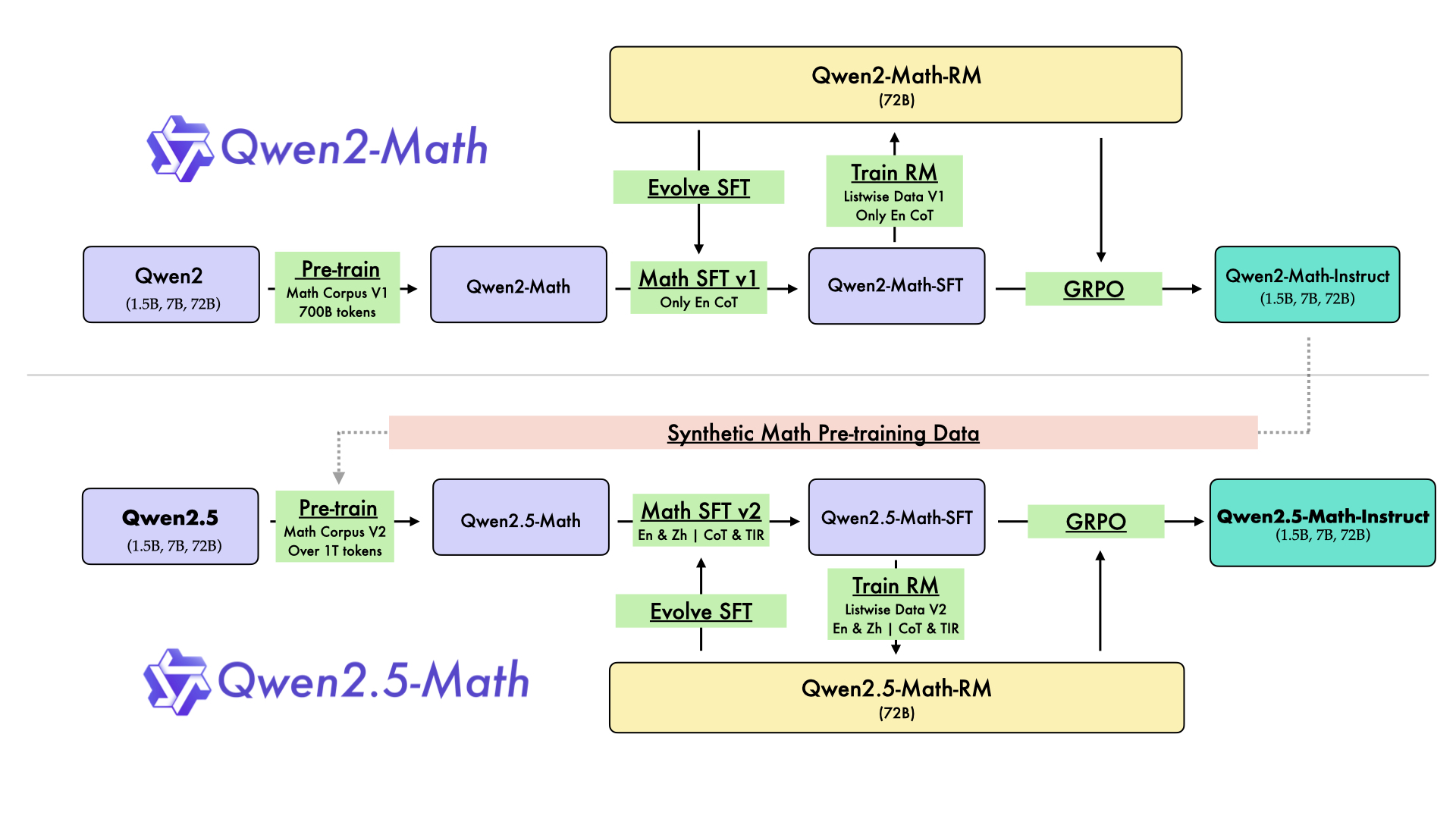
Qwen2-Math 和 Qwen2.5-Math 的整体训练流程如图所示。在完成 Qwen2-Math 基础模型的训练后,通过以下三条主要途径将其升级为 Qwen2.5-Math:
- 使用 Qwen2-Math-72B-Instruct 模型合成额外的高质量数学预训练数据。
- 多轮从网络资源、书籍和代码中聚合更多高质量的数学数据,尤其是中文数据。
- 利用 Qwen2.5 系列基础模型进行参数初始化,该模型在语言理解、代码生成和文本推理能力上更强大。
最终,构建了用于 Qwen2.5-Math 预训练的 Qwen Math Corpus v2 数据集,语境长度为 4K。与用于 Qwen2-Math 训练的 Qwen Math Corpus v1 相比,Token 总量从 7000 亿增加到超过 1 万亿。
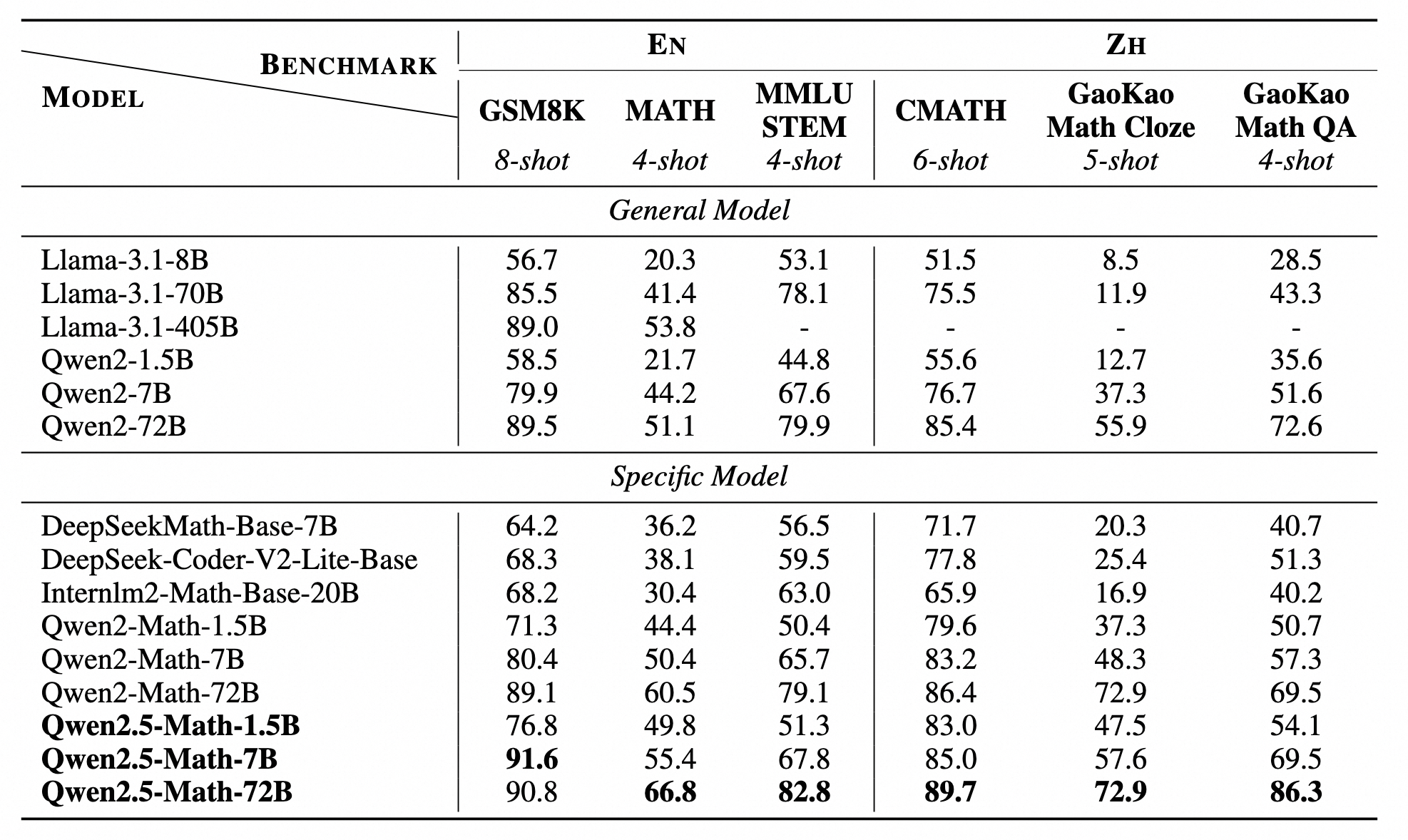
在三个常用的英语数学基准测试 GSM8K、Math 和 MMLU-STEM 以及三个中文数学基准测试 CMATH、高考数学填空和高考数学问答上评估了 Qwen2.5-Math 基础模型,所有评估均采用少样本 Chain-of-Thought 提示进行。

基于 Qwen2.5-Math-72B 训练了一个数学奖励模型 Qwen2.5-Math-RM-72B,用于通过拒绝抽样构建监督微调(SFT)数据,并在 SFT 后使用 Group Relative Policy Optimization(GRPO)进行强化学习。
在 Qwen2.5-Math-Instruct 的开发中,在 Rejection Sampling 阶段使用 Qwen2.5-Math-RM-72B 进一步提升了响应质量,并在后续的训练中引入了中文和英文的 TIR 数据和 SFT 数据。
Qwen2.5-Math-Instruct 模型在中英文的数学基准测试中表现优异,尤其在复杂的数学竞赛评估(如 AIME 和 AMC)中成绩突出。例如,在 AMC 2023 基准上,Qwen2.5-Math-1.5B-Instruct 使用 RM@256 在 CoT 模式下解决了 29 道题中的 21 道,而 Qwen2.5-Math-72B-Instruct 几乎在 TIR 模式下取得满分。

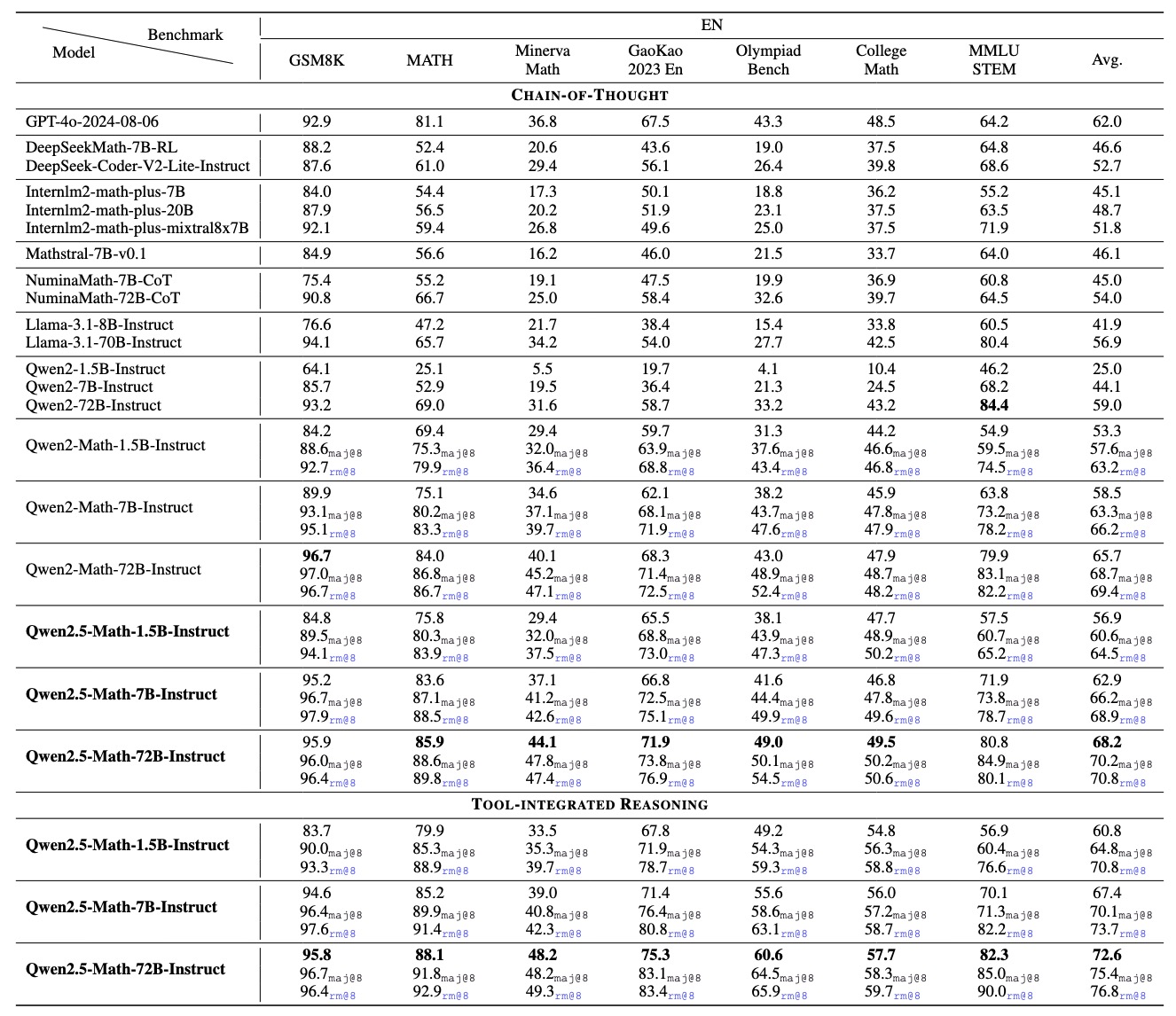

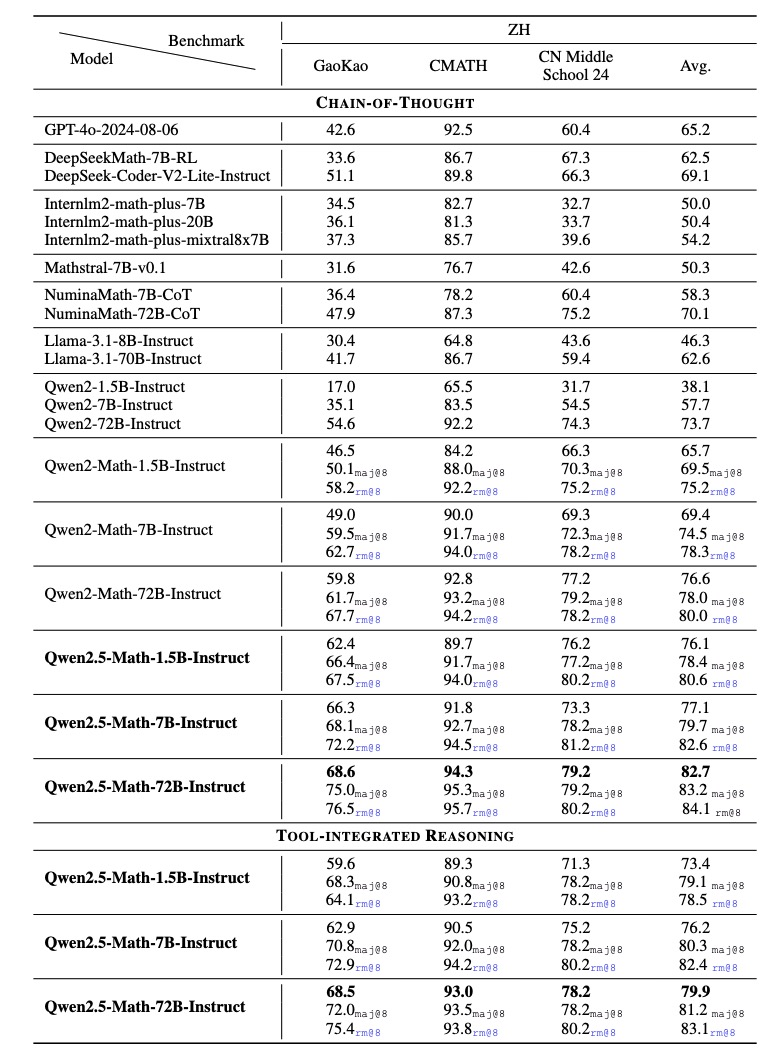
开发了一个支持 TIR 模式的演示,在Qwen-Agent中,可以在本地运行代码以体验 Qwen2.5-Math 的工具集成推理能力。