OpenAI发布了全新的o1-preview” 推理模型系列,这是一个设计用于解决复杂问题的 AI 系列,能够进行复杂推理。
相比之前的模型,这些新模型在回应之前会花费更多时间思考,尤其在科学、编码和数学等领域具有卓越的表现,根据官方的报告它的推理性能远超GPT-4o,能够在许多基准测试中超过人类专家水平。
新的推理模型学会像人类一样花更多时间推理问题,尝试不同策略,并修正错误。它们通过训练学会了更有效地分析问题,尝试多种策略,并能够识别并纠正错误。通过这种方式,模型能够在更复杂的任务中表现出色。

大规模强化学习算法
OpenAI 使用了一种大规模的强化学习算法,来训练 o1-preview 模型。该算法通过高效的数据训练,让模型学会如何利用“思维链”(Chain of Thought)来生产性地思考问题。模型在训练过程中会通过强化学习不断优化其思维链,最终提升解决问题的能力。
OpenAI 发现,o1 模型的性能会随着强化学习时间(训练时计算量)和推理时间(测试时计算量)的增加而显著提高。这种基于推理的训练方式与传统的大规模语言模型(LLM)预训练方式不同,具有独特的扩展性优势。


o1 性能在训练时间和测试时间的计算中都平稳提升
思维链(Chain of Thought)
o1-preview 模型通过 思维链推理 显著增强了其在复杂推理任务中的能力。思维链的基本理念类似于人类思考困难问题的过程:逐步分解问题、尝试不同策略并纠正错误。通过强化学习训练,o1-preview 能够在回答问题前进行深入思考,逐步细化步骤。
这种推理方式大幅提升了 o1-preview 在复杂任务中的表现。例如,o1-preview 能够通过思维链识别问题中的关键步骤并逐步解决。这种推理模式特别适用于需要多步骤推理的任务,如复杂的数学问题或高难度编程任务。
举例说明:
- 在某些复杂问题上,o1-preview 能够逐步打破问题的难点,最终找到正确解答。这与人类面对挑战性问题时逐步分析的思维方式非常相似。
评估与基准测试
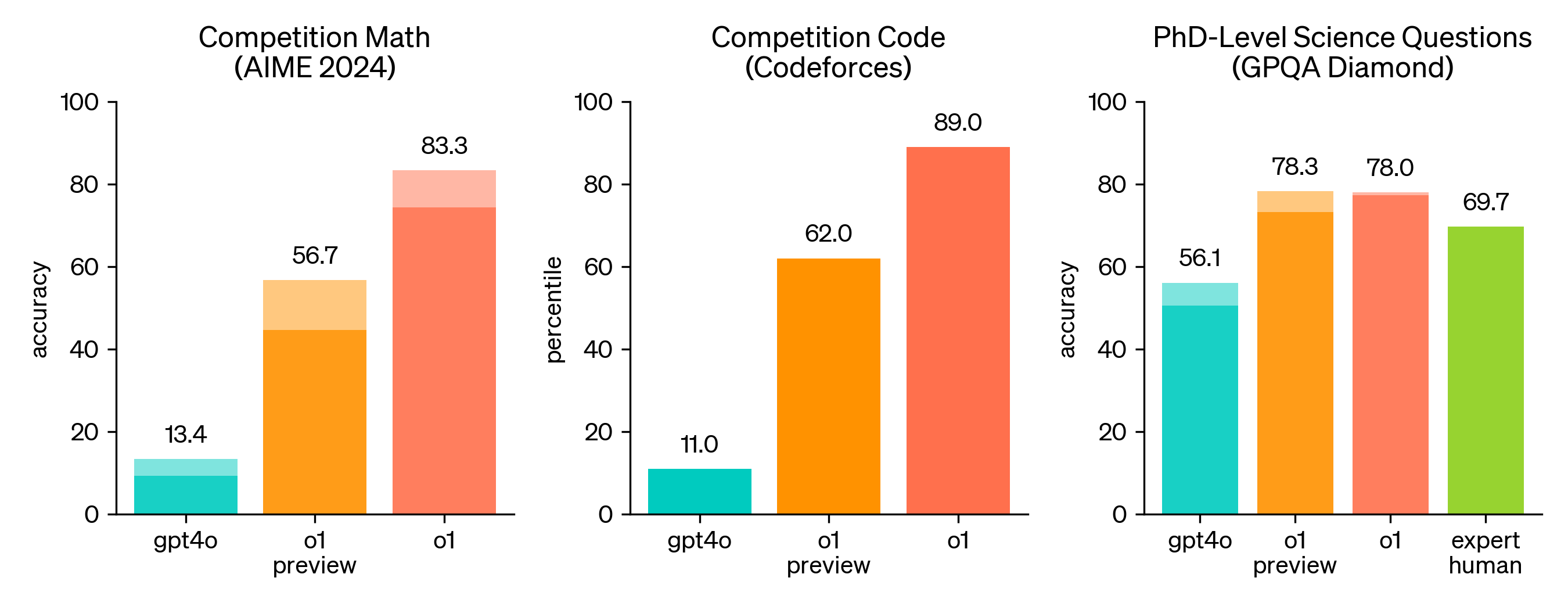

-
AIME(美国数学邀请赛):
在国际数学奥林匹克(IMO)的资格考试中,GPT-4o 模型仅正确解决了 13% 的问题,而新推理模型则正确解决了 83% 的问题。
- GPT-4o 仅解决了 12% 的问题(平均每 15 题解答 1.8 题)。
- o1-preview 平均解决了 74% 的问题(11.1/15),远远超越了 GPT-4o。
- 使用共识评估方法时(64 次样本共识),o1-preview 的解答率提高至 83%。
- 在重新评分 1000 个样本后,模型的最终得分达到 93%(13.9/15),这一成绩足以使其跻身全美前 500 名高中生之列,并超越了参加美国数学奥林匹克竞赛的入围分数。
-
GPQA(物理、化学和生物学的专家级测试):在 GPQA-diamond 基准测试中,o1-preview 超过了博士级专家的表现,成为第一个在该基准上优于人类博士的 AI 模型。这并不意味着 o1 比博士在所有任务中更强,而是它在某些问题上展示了超越博士解决能力的水平。
- 为了进行公平的对比,OpenAI 招募了具有博士学位的专家来回答 GPQA-diamond 基准测试中的问题。o1-preview 成功超越了这些人类专家,成为第一个在这一基准测试上超越博士级水平的 AI 模型。
- 需要注意的是,这并不意味着 o1-preview 模型在所有任务上都比博士专家更强,而是表明它在某些特定的问题上具备了超越专家的能力。
-
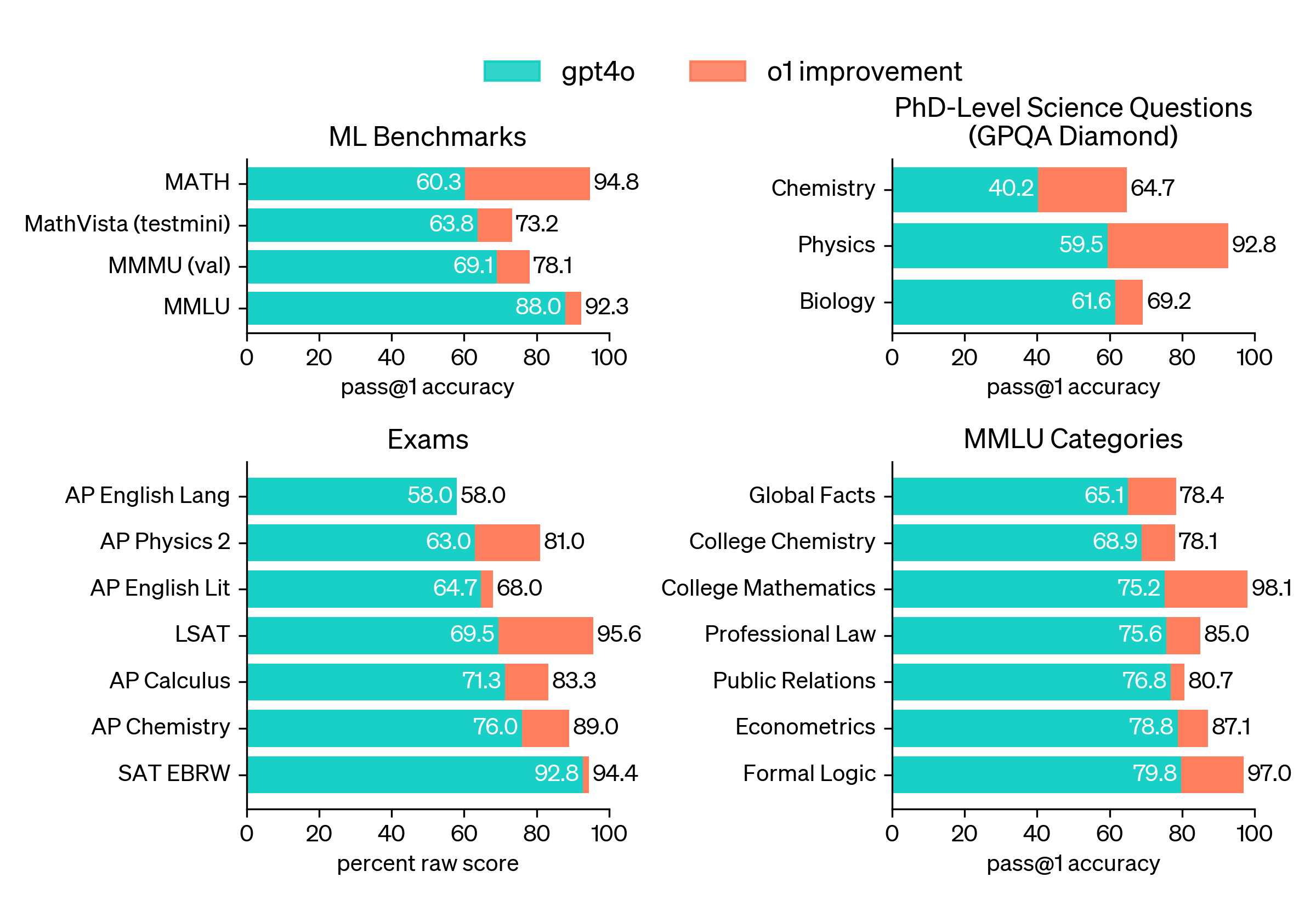
MMLU(多任务语言理解):o1-preview 在 57 个子类别中的 54 个类别中超过了 GPT-4o。特别是在视觉感知启用的情况下,o1 模型在 MMLU 基准测试中的表现达到了 78.2%,首次与人类专家竞争。
- GPT-4o 在 57 个子类别中仅在 3 个类别中超过了 o1-preview。
- o1-preview 在 54 个子类别中的表现优于 GPT-4o,展示了其更为广泛的推理能力。
- 尤其是在启用视觉感知功能时,o1-preview 在 MMLU 中得分达到了 78.2%,这是首个能与人类专家竞争的 AI 模型表现。
- 编码能力:新模型在编码能力上的表现也非常优越。在Codeforces编程竞赛中,o1模型也表现优异,超过了93%的竞争对手。特别是其编程能力,通过强化学习后的o1能够高效解决复杂的算法问题。
-
在 2024 年国际信息学奥林匹克竞赛(IOI) 中,OpenAI 训练了一个基于 o1-preview 的模型参加比赛,并在相同的条件下与人类选手竞争。
- 该模型在比赛中得到了 213 分,排名在第 49 百分位,表现优于大部分参赛者。
- 模型在 10 小时内解决了 6 个复杂的算法问题,并且每个问题允许提交 50 次结果。通过多次样本提交,该模型的成绩得到了显著提升。
-
在 Codeforces 编程竞赛中,o1-preview 模型达到了 1807 Elo 分数,这使得它超过了 93% 的人类竞争者。
- 对比之下,GPT-4o 的 Elo 分数仅为 808,位于人类参赛者的 11 百分位。
通过这些评估,o1-preview 展示了其在编程任务中的显著优势,特别是在解决复杂算法和逻辑问题时表现卓越。
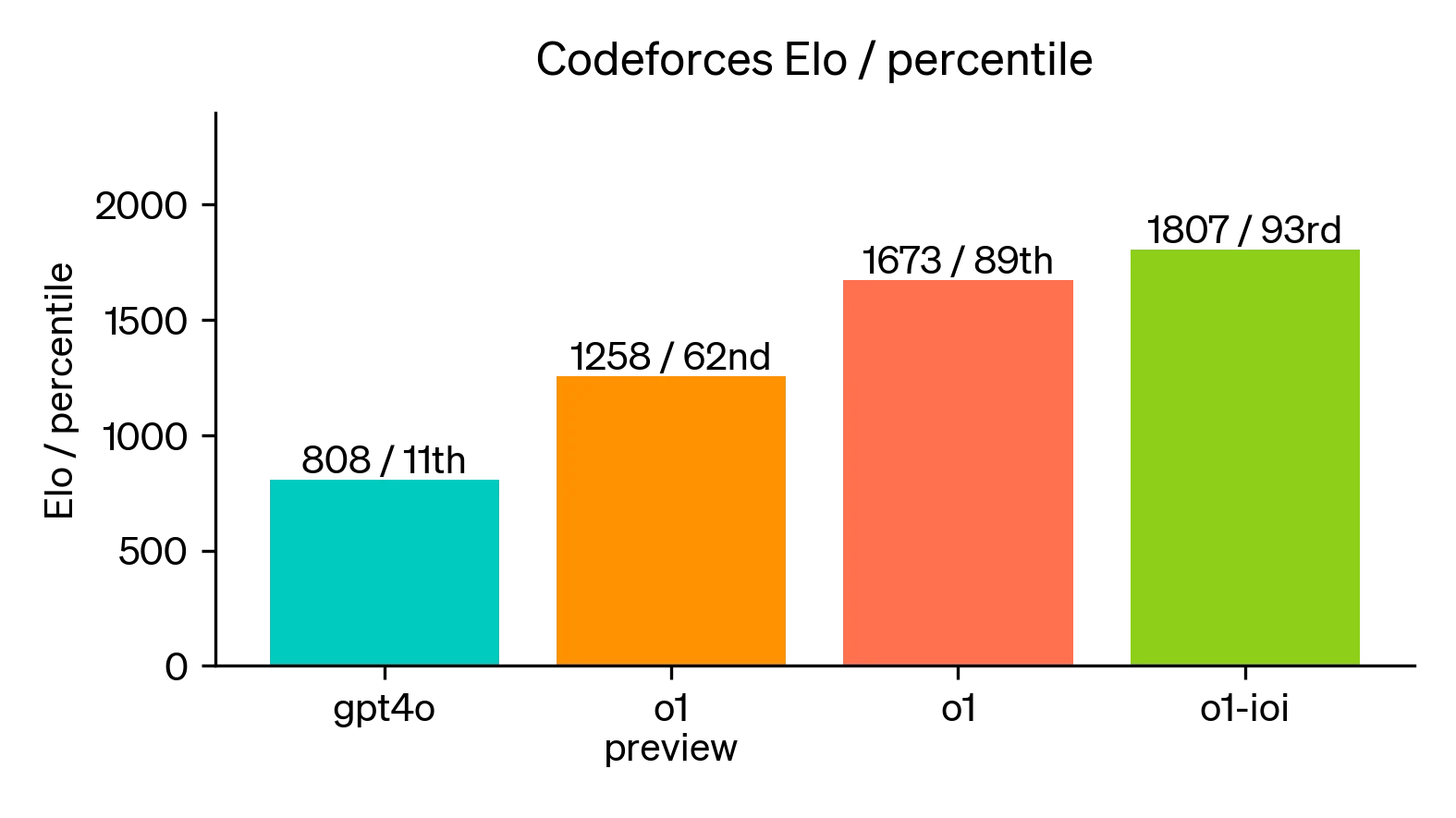
-
-
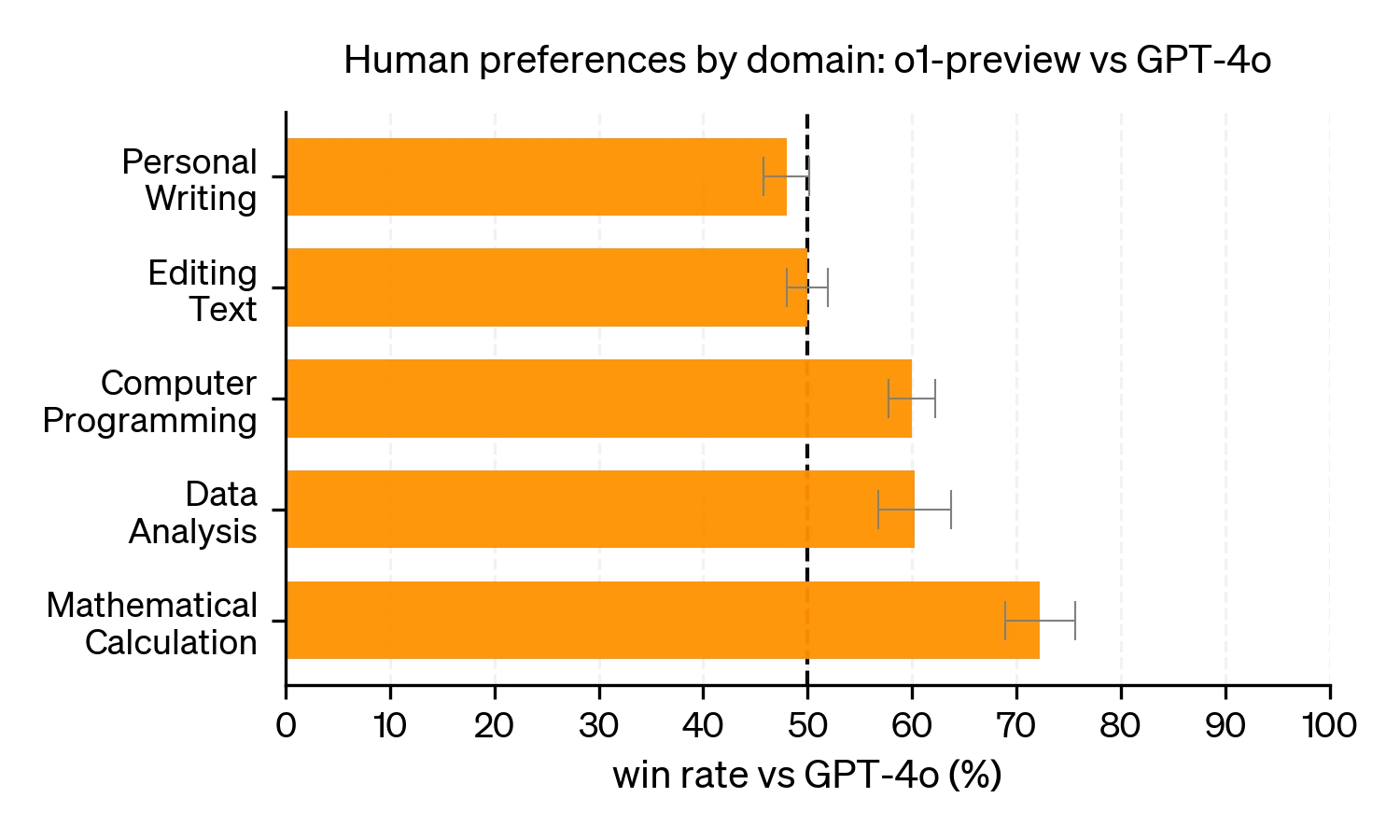
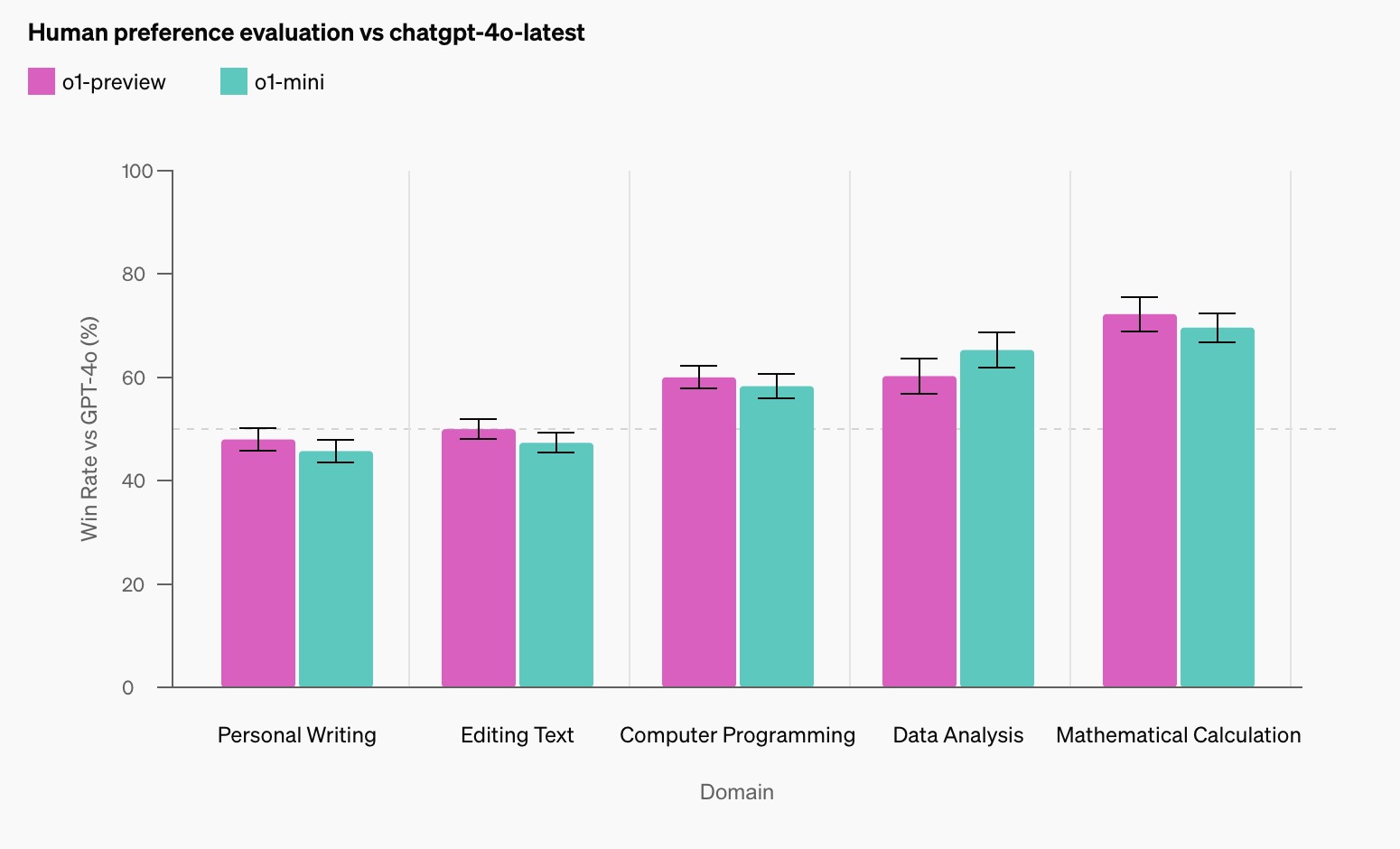
人类偏好评估
除了学术基准测试,OpenAI 还进行了 人类偏好评估。评估方法是通过向人类评审者展示 o1-preview 和 GPT-4o 在相同问题上的匿名回答,评审者根据回答的质量选择他们更偏好的答案。
结果显示:
- 在涉及推理任务(如数据分析、编码、数学等)的领域,人类评审者明显偏好 o1-preview 模型的回答。
- 然而,在一些自然语言处理任务中,GPT-4o 的表现优于 o1-preview,这表明 o1-preview 并不适合所有的应用场景,尤其是在语言生成和自然语言理解方面。



适用用户
新的推理模型将特别适合处理科学、编程、数学等领域中的复杂问题。以下是一些可能的应用场景:
- 医疗领域:研究人员可以使用 o1-preview 模型注释复杂的细胞测序数据。
- 物理学:物理学家可以利用该模型生成复杂的数学公式,特别是量子光学领域中的计算。
- 开发者:在开发领域,o1-preview 可以帮助开发者构建和执行多步骤工作流,简化复杂任务的处理流程。
OpenAI o1-mini
为了满足开发者的需求,OpenAI 还发布了 OpenAI o1-mini,这是一个更小、更快速的推理模型,专注于代码生成和调试。o1-mini 模型相较于 o1-preview 更加便宜,成本降低了 80%,适合那些需要推理能力但不需要广泛世界知识的应用场景。
o1-mini 的优势:
- 该模型特别适合编码任务,能够准确生成和调试复杂代码。
- o1-mini 的计算资源更少,因此在需要高效、快速和成本控制的应用中表现优异。
- o1-mini 是一款较小但高效的推理模型,与 OpenAI 的 o1-preview 和 o1 相比,成本减少了 80%,但在 STEM 领域中的推理能力几乎与 o1 持平。
- 今天,o1-mini 正式面向 API 第 5 级用户发布,价格比 o1-preview 更具竞争力。
- ChatGPT Plus、团队、企业和教育用户也可以使用 o1-mini 作为 o1-preview 的替代选择,享受更高的速率限制和更低的延迟。
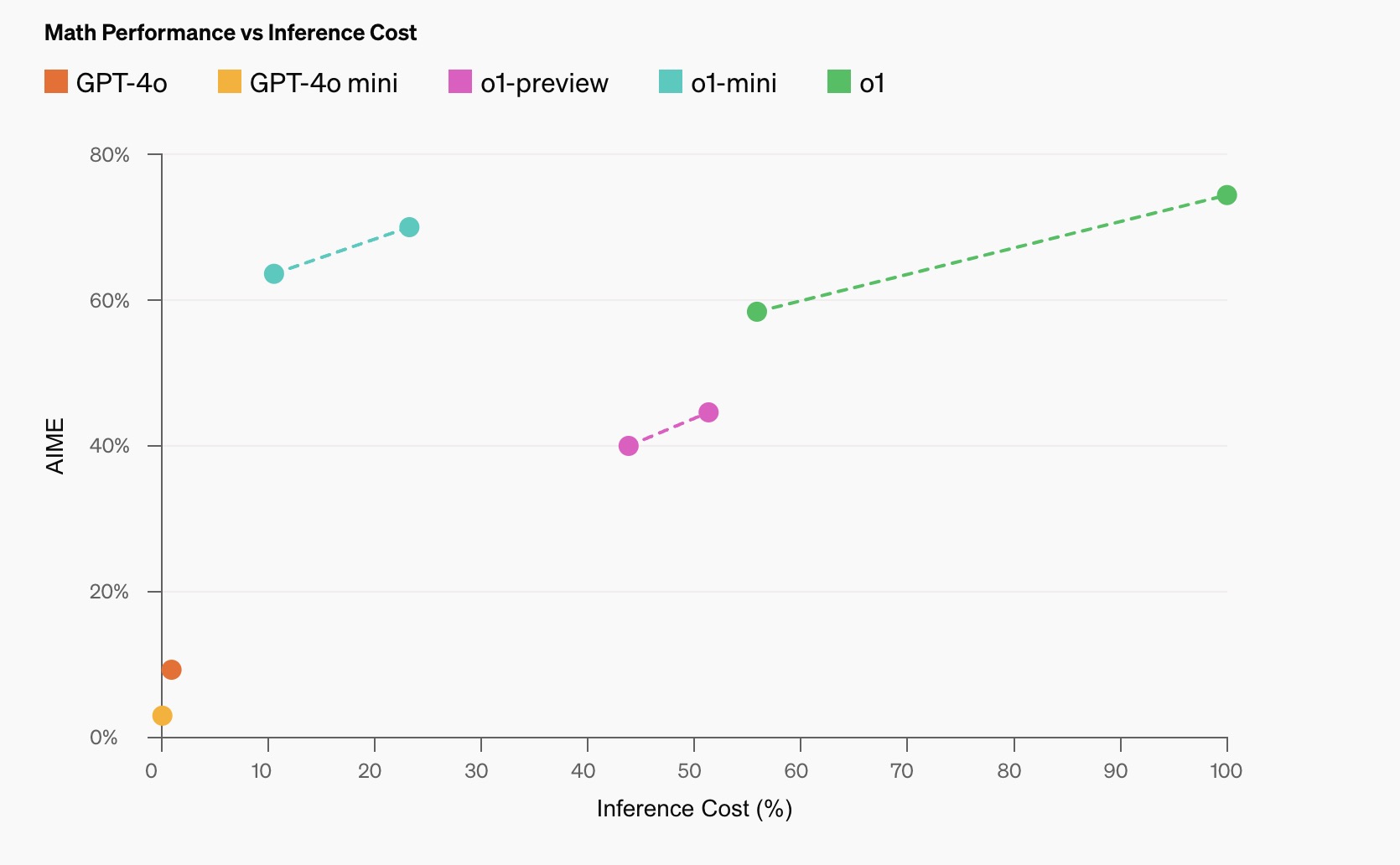

相比大型语言模型(如 o1),o1-mini 专为 STEM 推理任务进行了优化。虽然大型模型如 o1 具有广泛的世界知识,但它们在实际应用中可能较为昂贵且运行速度较慢。与之相比,o1-mini 经过优化,专注于推理任务,在诸如数学和编码等领域表现出色。
o1-mini 在预训练阶段采用了与 o1 相同的高计算力强化学习(RL)管道,因此在许多推理任务中表现类似,但成本却大大降低。尽管 o1-mini 在需要非 STEM 知识的任务中表现较差,但在 STEM 推理领域,它的性能非常接近 o1-preview 和 o1。
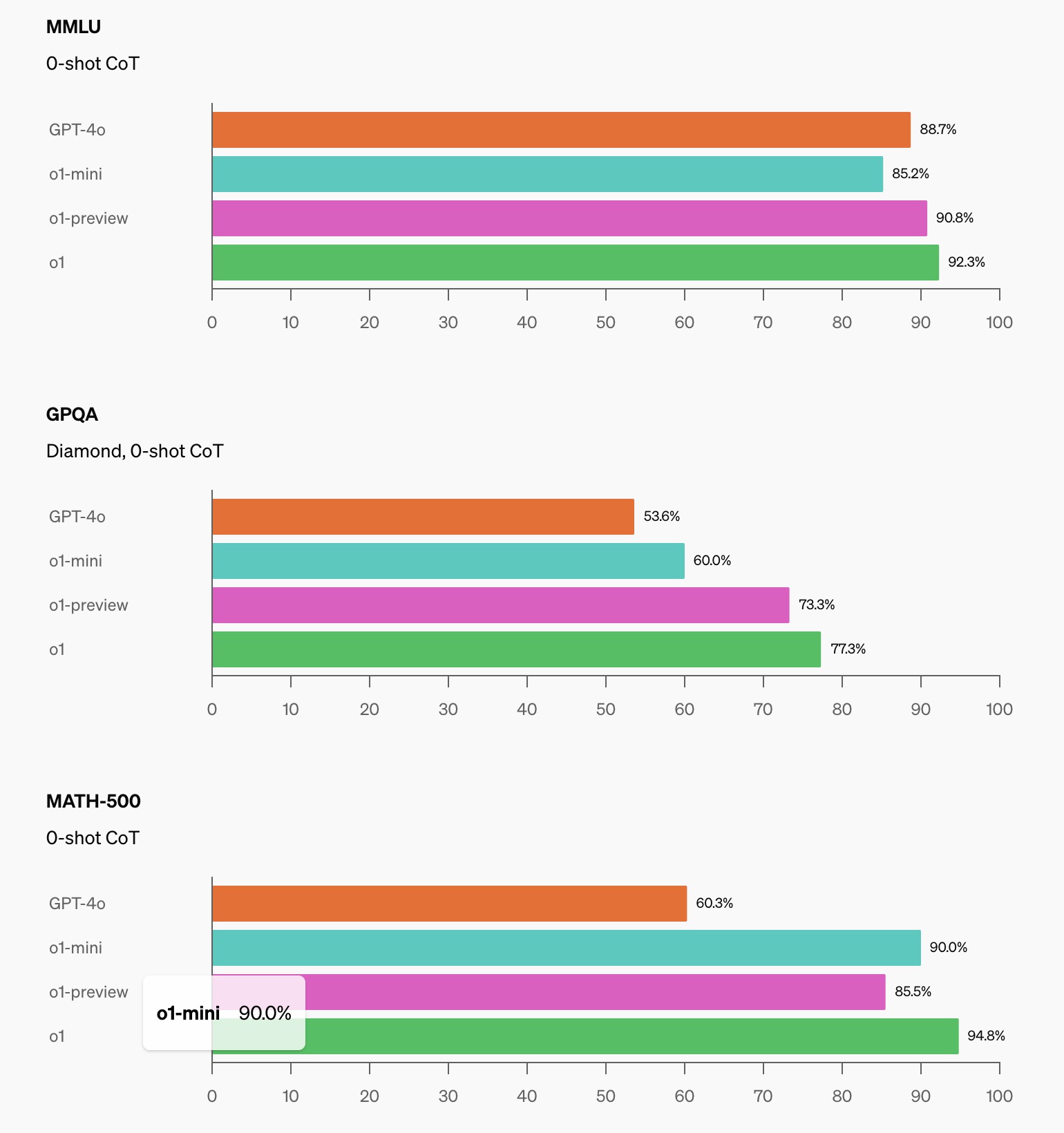

o1-mini 在多项 STEM 基准测试中表现出色,尤其在数学和编程任务上,显示出强大的推理能力。
-
数学表现:
- 在 AIME(美国数学邀请赛)的高中数学竞赛中,o1-mini 得分为 70.0%,接近 o1 的 74.4%,并显著超过 o1-preview 的 44.6%。o1-mini 的成绩(约解决了 11/15 的问题)使其位列美国前 500 名高中生。
-
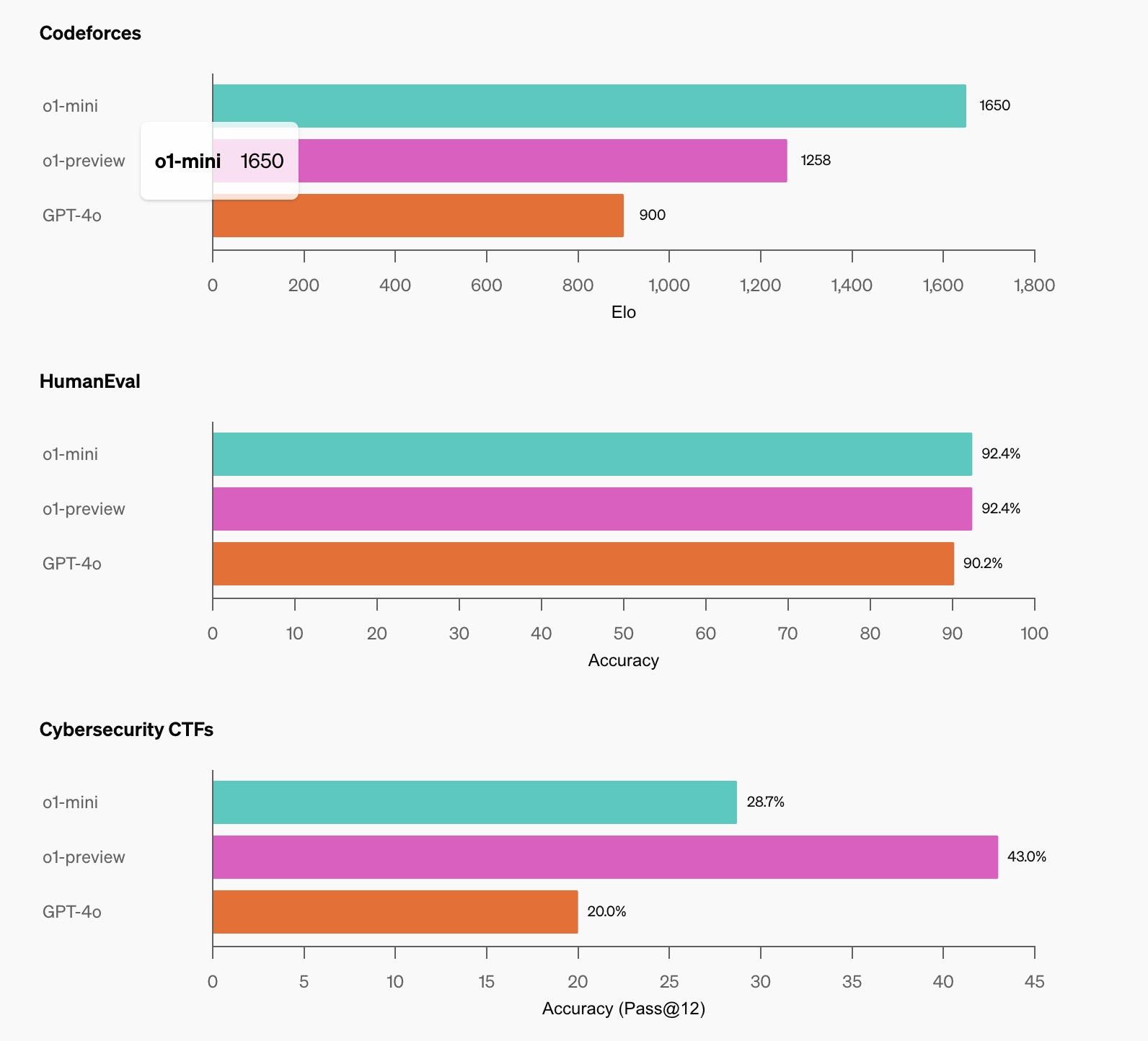
编程表现:
- 在 Codeforces 编程比赛网站上,o1-mini 达到了 1650 Elo,与 o1 的 1673 Elo 接近,并高于 o1-preview 的 1258 Elo。这一 Elo 分数使得 o1-mini 位于 Codeforces 平台上 86% 的程序员之列。
- o1-mini 在 HumanEval 编程基准测试和高中级别的网络安全夺旗挑战赛(CTF)中表现优异。
-
学术推理:
- 在某些学术推理基准测试上,如 GPQA(科学)和 MATH-500,o1-mini 的表现优于 GPT-4o,但由于缺乏广泛的世界知识,o1-mini 在 MMLU(多任务语言理解)等任务上的表现不如 GPT-4o,也落后于 o1-preview。
- 人类偏好评估:在人类评审员各种领域中比较 o1-mini 和 GPT-4o测试中,使用与o1-preview 与 GPT-4o 比较相同的方法。在重推理的领域中,o1-mini 比 GPT-4o 更受欢迎,但在语言集中领域中,o1-mini 不如 GPT-4o 受欢迎。


性能对比
- AIME 数学竞赛:o1-mini 得分 70.0%,接近 o1 的 74.4%,显著超过 o1-preview 的 44.6%。
- Codeforces 编程:o1-mini 的 Elo 分数为 1650,与 o1 的 1673 接近,优于 o1-preview 的 1258。
- HumanEval 编程基准测试:o1-mini 的准确率为 92.4%,与 o1-preview 持平,高于 GPT-4o 的 90.2%。
- 网络安全 CTF:o1-mini 的表现为 43.0%,高于 o1-preview 的 28.7% 和 GPT-4o 的 20.0%。
模型速度
作为一个具体的例子,比较了 GPT-4o、o1-mini 和 o1-preview 在一个词语推理问题上的回答。虽然 GPT-4o 没有正确回答,但 o1-mini 和 o1-preview 都回答正确,并且 o1-mini 的回答速度大约快了 3-5 倍。


局限性
- 限制:o1-preview 30 条/周,o1-mini 50 条/周,T5 级别的开发者可以访问其 API,每分钟最多20并发
- 不支持网页浏览、文件和图片上传、画图等功能;
- 在 API 里不支持 system、tool 等字段和 json mode、结构化输出等方法。
- 模型说是有 32k/64k 的最大输出,但真实输出远没有这么多。
- 从实际测试的角度,发现 o1 与其说是一个模型,不如说是基于 GPT-4o 的 agent。
价格与限制
目前 o1 系列模型可通过 ChatGPT 网页版,或者是 API 进行访问:
- o1-preview
- 128k 上下文
- 32k 最大输出
- 旨在解决各个领域复杂问题的推理模型
- 训练数据截止于 23 年 10 月
- o1-mini:
- 128k 上下文
- 64k 最大输出
- 一种更快速、更经济的推理模型,特别擅长编程、数学和科学
- 训练数据截止于 23 年 10 月

- 对于 ChatGPT 网页版,目前仅 Plus 和 Team 用户目前已经可以访问了。对于 Enterprise 以及 Edu 的用户,还需要再等一周:
- o1-preview:30 条/周
- o1-mini:50 条/周

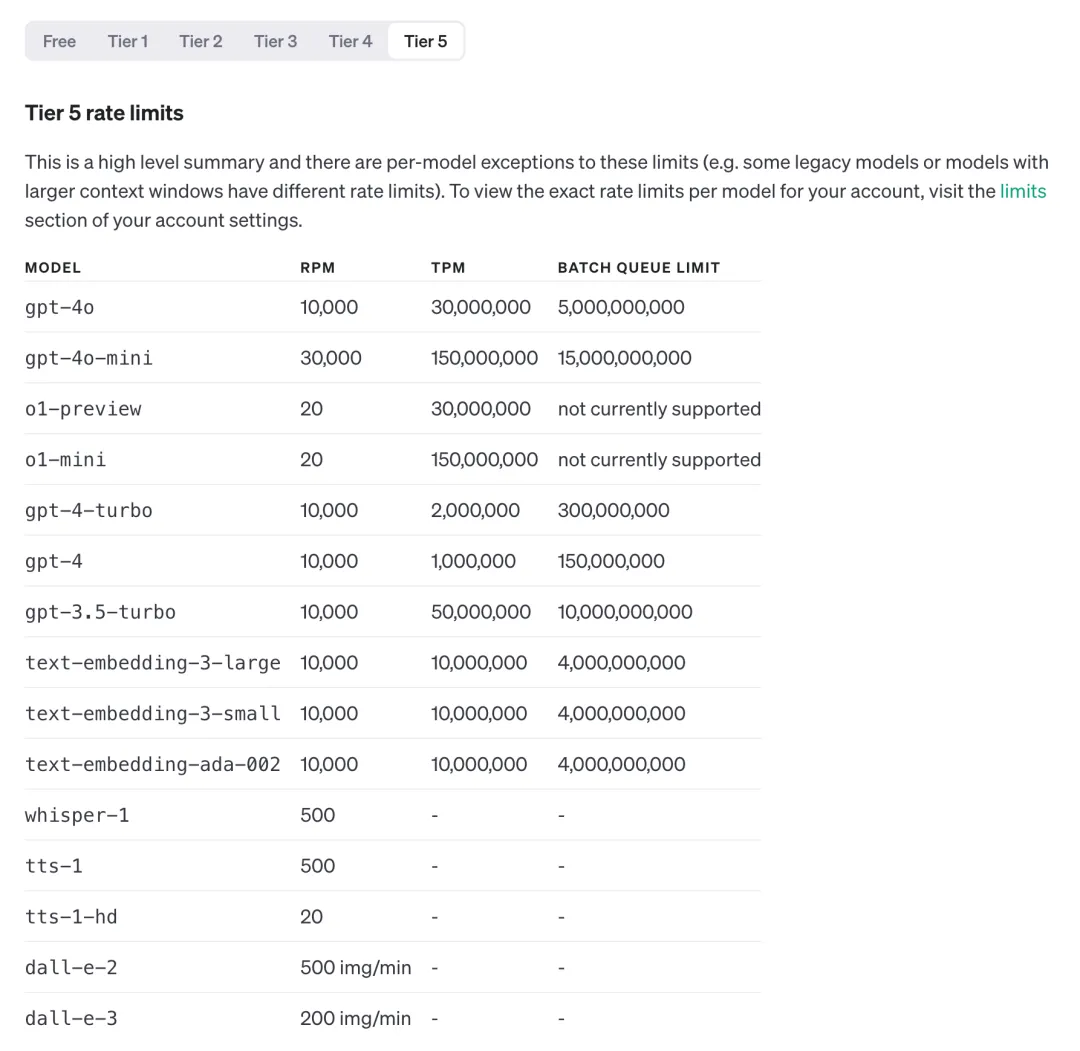
- 对于 API 用户,如果你的等级在 Tire5 (支付金额>1000 美金),目前已经可以通过接口进行调用:
- o1-preview:20 RPM,30,000,000 TPM
- o1-mini:20 RPM,150,000,000 TPM



一些案例展示



OpenAI o1 翻译不完整的韩文

解决数学问题

编写谜题


代码编写

推理能力

逻辑谜题

