

Jina AI 推出的两款专门将原始 HTML 转换为干净的 Markdown 的小型语言模型。
Reader-LM 的功能特点
-
HTML 到 Markdown 转换:HTML 到 Markdown 的转换:
- Reader-LM 专为将原始 HTML 内容转换为干净、结构化的 Markdown 文件而设计,简化了从网页提取和清理数据的过程。无需复杂的规则或正则表达式,模型能自动处理噪声内容,如广告、脚本、导航栏等,生成结构清晰的 Markdown。
-
小型但高效的语言模型:
- Reader-LM 提供了两种模型:Reader-LM-0.5B 和 Reader-LM-1.5B。虽然参数较小,但它们专门针对 HTML 转 Markdown 任务进行了优化,表现超过了许多更大的语言模型。由于模型的紧凑性,它们能够在资源有限的环境中高效运行。
- 这两个模型都是多语言的,支持最长 256K 令牌 的上下文长度。尽管它们的体积小,这些模型在这个任务上实现了最先进的性能,超越了更大的 LLM 对应模型,而它们的体积仅为其 1/50。

-
多语言支持:
- Reader-LM 支持多种语言,使其能够处理来自全球各地的网页内容。这种多语言能力特别适合在国际化项目中使用,能够自动识别并处理不同语言的 HTML 内容。
-
长上下文处理能力:
- 模型能够处理长达 256K tokens 的上下文数据,这意味着即使是非常复杂和庞大的 HTML 文件,也能被模型高效处理。它非常适合用于内容丰富的网页或文档。
-
端到端的数据清理与提取:
- 与传统的依赖正则表达式或启发式规则的方法不同,Reader-LM 是一个端到端的解决方案,可以自动清理 HTML 数据并提取关键内容,无需繁琐的手动设置。

Reader-LM性能

-
对比性能:
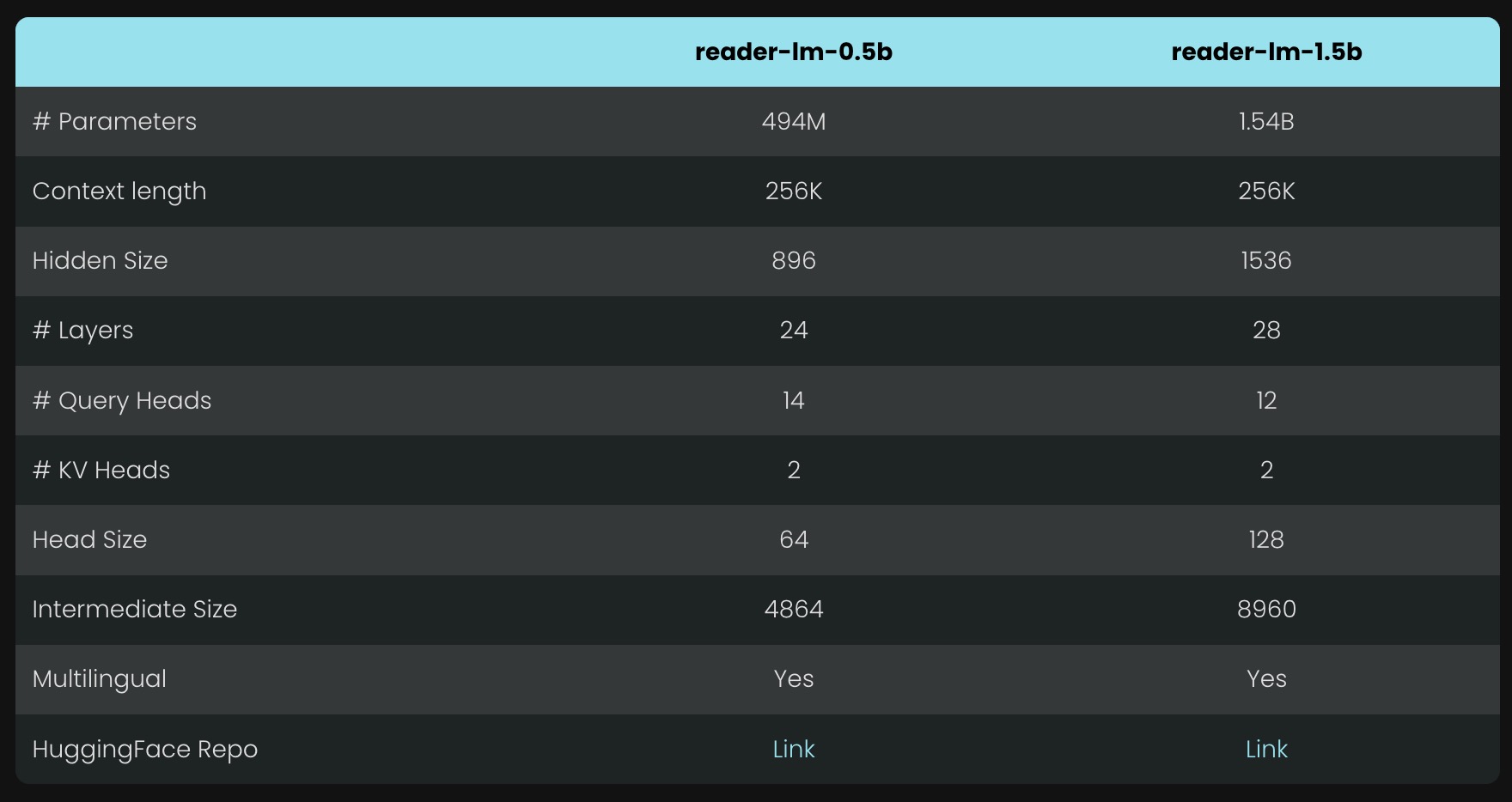
- Reader-LM 模型与 GPT-4 和 Gemini 等更大型的语言模型进行对比测试,尽管参数量较小,Reader-LM 在 HTML 转 Markdown 任务中的表现优于一些更大的模型。
- 在任务中,Reader-LM-1.5B 表现尤为出色,具备更高的ROUGE-L 分数(衡量输出与参考之间的相似性),并且Word Error Rate (WER) 和 Token Error Rate (TER) 都较低,表明它在生成内容时准确率更高,误差更小。

-
指标对比:
- Reader-LM-0.5B 和 Reader-LM-1.5B 在测试中表现如下:
- ROUGE-L: 0.56(0.5B 模型),0.72(1.5B 模型),优于 GPT-4 等更大模型。
- WER(Word Error Rate): 1.87(1.5B 模型),表示输出的准确性较高,减少了错误生成。
- TER(Token Error Rate): 0.19(1.5B 模型),该指标显示出模型在 HTML 转 Markdown 时的高准确率。
- Reader-LM-0.5B 和 Reader-LM-1.5B 在测试中表现如下:
-
效率与资源占用:
- 由于 Reader-LM 是小型模型,它在资源需求方面更加轻量,特别是Reader-LM-0.5B 模型,可以在较低配置的硬件(如 Google Colab 的免费 GPU)上高效运行。
- 尽管模型小,但它的上下文处理能力强大,支持256K tokens,这使得它能够处理庞大、复杂的网页内容,而不会影响性能。
-
训练效率:
- Reader-LM 使用了多阶段训练流程,确保了在转换复杂 HTML 内容时的性能。与预训练模型相比,Reader-LM 能更有效地完成HTML 到 Markdown 的“选择性复制”任务,同时保持较高的准确率和处理速度。


Reader-LM 尽管参数较小,但在处理 HTML 到 Markdown 的任务中表现优异,具备高准确率、低错误率和强大的长上下文处理能力,能够在较低硬件资源下高效运行。其表现优于一些更大的语言模型,尤其是在精确性和任务专用性能上,极具性价比。
Reader-LM 训练情况
Reader-LM 的训练分为两个阶段,重点在于数据清理和处理长上下文任务。模型经过精心设计和训练,专注于从原始、噪声较多的 HTML 中提取并转换为 Markdown 内容,以下是详细的训练流程和技术细节:
1. 数据准备
- HTML 到 Markdown 转换对:Jina AI 使用 Jina Reader API 生成了大量的 HTML 到 Markdown 的配对数据。这些配对数据包括从网页中提取的原始 HTML 和对应的 Markdown 转换版本。
- 合成数据:除了真实的网页数据,还引入了由 GPT-4 生成的合成数据,这些数据更简单,结构更容易预测,帮助模型处理不同复杂度的 HTML。
- 高质量数据过滤:训练数据经过严格的筛选,确保只有高质量的 Markdown 条目被纳入训练集,这提高了模型的整体表现。
2. 两阶段训练流程
- 短序列阶段:
- 在训练初期,Reader-LM 使用长度为 32K tokens 的 HTML + Markdown 序列进行训练,共使用了 15 亿 tokens。
- 这一阶段的目标是让模型掌握短文本和较简单 HTML 结构的转换能力。
- 长序列阶段:
- 在后续阶段,Reader-LM 处理更复杂的 HTML 文件,序列长度扩展至 128K tokens,并引入了 12 亿 tokens 进行训练。
- 使用了Zigzag-Ring Attention 机制(Zilin Zhu 的 “Ring Flash Attention” 技术),使得模型能够高效处理长序列内容。
3. 模型大小和架构
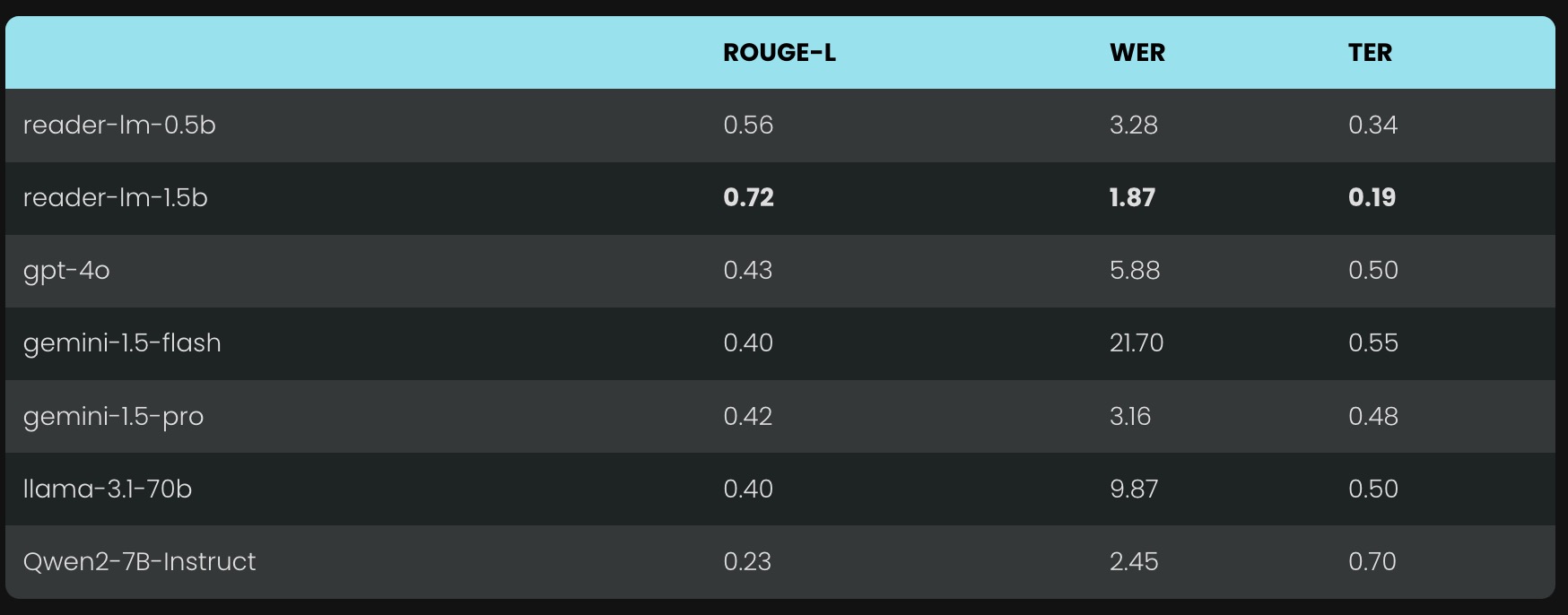
- Reader-LM 提供了两个不同大小的模型:
- Reader-LM-0.5B:具有 494M 参数,是一个小型但高效的模型,能够胜任较长上下文的 HTML 转 Markdown 任务。
- Reader-LM-1.5B:参数更大,达 1.54B,在长文本处理和复杂内容提取上表现更加优异。
- 两个模型都支持256K tokens 的长上下文处理能力,确保在处理长篇网页内容时依然能够保持高效。
4. 处理重复生成与退化问题
- 重复生成问题:训练过程中遇到的一个主要问题是模型生成重复内容或陷入死循环(称为“退化”)。为了解决这一问题,训练时引入了 对比搜索(Contrastive Search) 和 对比损失(Contrastive Loss),有效减少了重复生成的现象。
- 停止准则:为避免重复生成,训练过程中加入了一个简单的重复停止准则,当模型开始重复生成时,自动停止解码,以防止“死循环”问题。
5. 训练框架和优化
- 使用了基于 Transformers Trainer 的训练框架,为了优化长输入的训练效率,采用了分块模型转发(Chunk-wise Model Forwarding),减少了显存使用,并提升了长序列处理的训练效率。
- 数据打包时通过将多个短文本拼接成一个长序列来减少填充,优化了训练速度。
6. 实验与结果
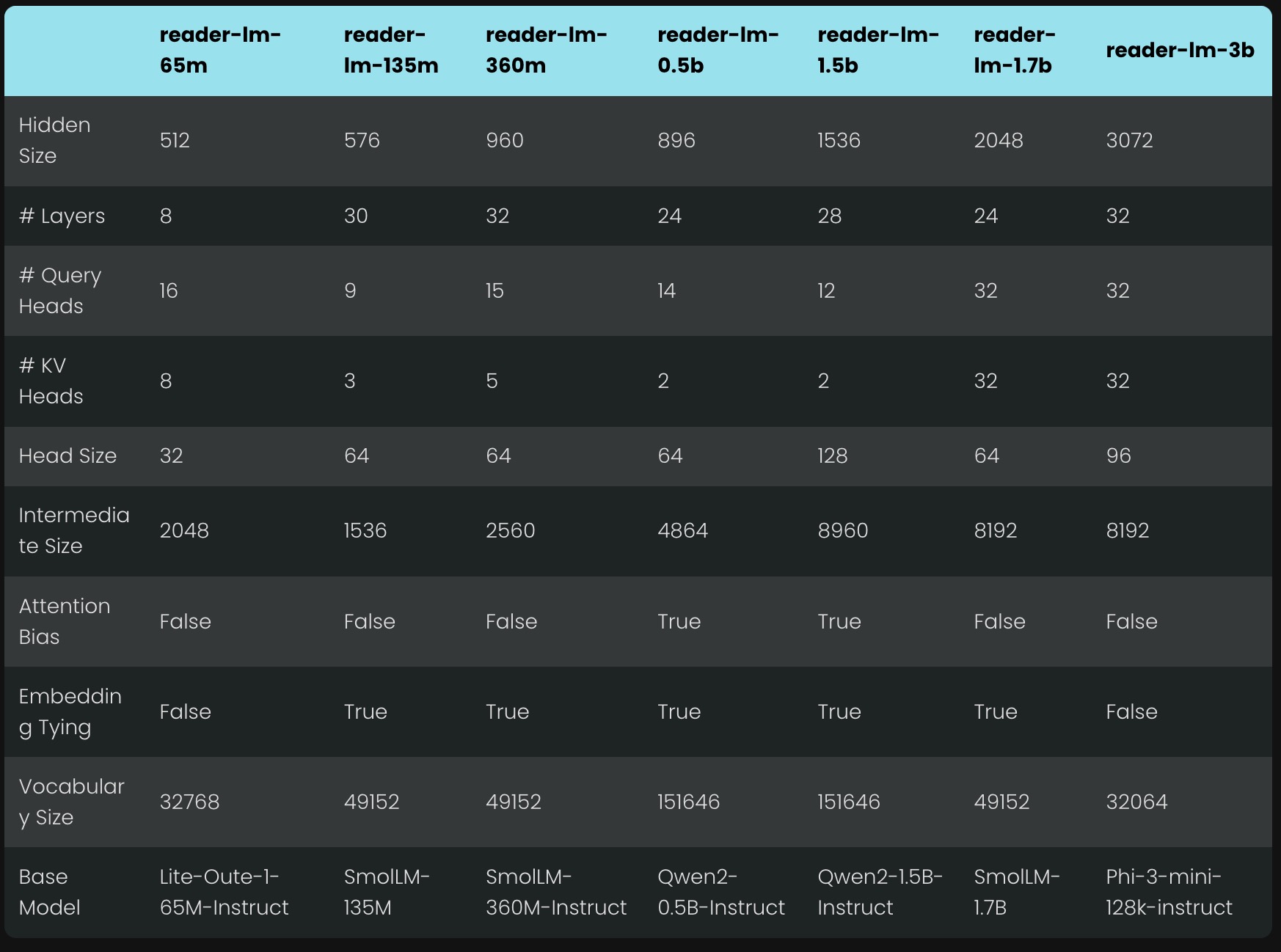
- 训练过程中,实验表明小型模型(如 65M、135M 参数的模型)在处理较短的输入时表现良好,但在长文本(超 1K tokens)时表现不佳。因此,选择了 0.5B 和 1.5B 模型作为公开发布的版本。
- 0.5B 模型被认为是处理长上下文的最小模型,而 1.5B 模型则在性能上有显著提升,同时保持了较高的计算效率。

模型下载:
- Reader-LM-0.5B: Hugging Face – Reader-LM-0.5B
- Reader-LM-1.5B: Hugging Face – Reader-LM-1.5B
如果你想在 Google Colab 上进行尝试,可以通过 Jina AI 提供的 Colab Notebook 快速体验模型。
模型的发布遵循 CC BY-NC 4.0 许可协议,允许非商业用途。如果需要商业使用,可以联系 Jina AI 进行许可申请。