

成立两年半的 MiniMax 一直悄无声息的,低调前行。但在刚刚结束的MiniMax Link伙伴日上MiniMax的创始人闫俊杰,详细介绍了公司开发的多款多模态模型,包括语音模型、音乐模型和视频生成模型。这些模型在多个领域展现了领先的技术水平。

以下是这些模型的详细介绍:
1. 语音模型
MiniMax的语音模型经过精心打磨,具备多种先进功能:
- 多语种支持:该模型支持包括日语、韩语、西班牙语、法语、粤语等在内的10多种语言。这使得MiniMax成为全球第一个拥有地道粤语语音模型能力的公司。
- 情绪表达:生成的语句不仅自然流畅,还能够模拟出细腻的情绪变化,使得语音表达更加拟人化,接近人类的自然语言表达。
- 音乐生成:MiniMax的语音模型还具备音乐生成的能力,能够创作具有高度艺术性和可塑性的音乐作品,提供给创作者和用户全新的玩法和惊喜。

2. 音乐模型
MiniMax推出了首款音乐生成模型,这款模型具有极高的艺术性和可塑性。其主要特点包括:
- 高度拟人化的音乐生成:该模型能够创作出复杂且富有情感的音乐作品,适用于多种创作场景,给音乐创作带来了极大的灵活性和创新空间。
- 多风格支持:模型能够驾驭多种音乐风格,从传统乐器到现代电子音乐,从中式古典到西方流行,几乎无所不能。
3. 视频生成模型
MiniMax的视频生成模型是目前全球领先的视频生成技术之一,具备以下独特优势:
- 文本响应能力强:该模型得益于MiniMax在文本处理上的深厚积累,能够精准理解和响应文本指令,从而生成与指令高度一致的视频内容。
- 高压缩率和高动态表现力:由于MiniMax在网络架构上的经验积累,该模型在处理高动态、变化多的视频信息时表现尤为出色,同时保持高效的压缩率。这使得模型在生成高质量视频时表现出色,尤其是在生成复杂场景和高动作场景时尤为明显。
- 风格多样性:模型能够支持多种视频风格,无论是3D电影大片场景、2D动画,还是中式风格、科幻风格或美漫风格,均能轻松驾驭。
MiniMax将这些模型整合在其开放平台以及相关应用中,如星野APP、海螺AI等,用户可以通过这些平台体验到最新的模型。
新一代 MOE+ Linear Attention 模型

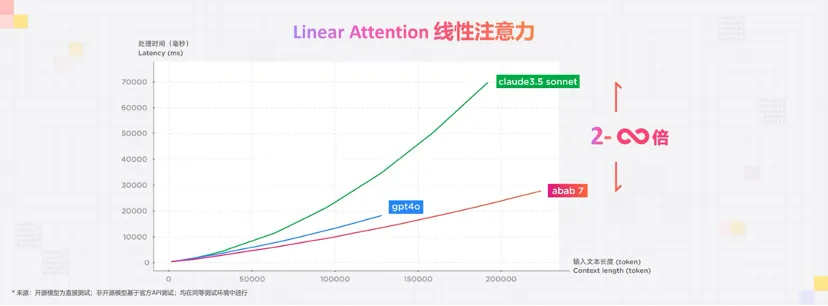
- MOE (Mixture of Experts) 架构: abab 7 模型基于MiniMax自研的MOE技术,成功实现了在不牺牲模型性能的前提下,大幅度提高了处理速度。通过这种架构,模型能够选择性地激活部分专家,从而节省大量的计算资源,同时在处理特定任务时依然能够保持高效和精准。
- Linear Attention: abab 7 采用了MiniMax创新的Linear Attention机制。Linear Attention技术使模型能够以线性复杂度处理极长的输入序列,相比传统的注意力机制,其处理效率显著提升。这种改进不仅使得模型在长文本处理上具有更好的表现,也在复杂任务处理上减少了错误率。
- 多模态理解与生成: abab 7 不仅在文本生成上表现出色,还具备了强大的多模态处理能力。它能够处理和生成包括图像、声音、视频等多种形式的内容。尤其是在语音、视频生成方面,abab 7 能够通过其优化的模型架构,实现对多模态输入的深度理解和响应,生成高度拟真和多样化的内容。
性能与应用
- 处理速度与效率:得益于MOE和Linear Attention的结合,abab 7 在处理速度上较前代模型提升了多个量级。在长序列处理和复杂任务执行中,其表现尤为突出,处理效率是传统模型的数倍。
- 生成质量:无论是在文本生成、语音合成还是视频创作上,abab 7 都展示了高度的生成质量。其生成内容不仅自然流畅,而且在情感表达和细节处理上有着极高的精度,几乎可以媲美人类的创作能力。
- 多语言与多模态支持:abab 7 支持多种语言的处理,包括多语种翻译、情感语音合成等。此外,它还支持从文本生成图像、视频等多模态内容,为用户提供更加多样化和富有创意的AI应用场景。
背景概述
Linear Attention 是一种优化Transformer模型中注意力机制的技术,它旨在解决传统注意力机制中随着输入长度增加,计算复杂度急剧上升的问题。在Transformer中,注意力机制的计算复杂度与输入长度呈平方关系(O(n^2)),这导致当输入长度较大时,计算变得非常昂贵且难以处理。Linear Attention 的目标是将这种复杂度降低为线性关系(O(n)),从而显著提高模型的处理效率,特别是在处理长文本或其他大规模数据输入时。
工作原理
Linear Attention 的核心思想是通过简化传统注意力机制中的计算过程,减少计算资源的消耗。具体实现包括以下几个关键步骤:
- 乘法近似: 在传统Transformer中,注意力机制的计算涉及到一个左乘和一个右乘操作,形成一个密集矩阵计算。Linear Attention通过将这个计算分解为两步:首先是左乘,然后是右乘。通过找到合适的近似方法,可以有效地降低计算复杂度。
- 归一化替代: 传统Transformer中使用的是Softmax归一化函数,这种函数在计算过程中消耗大量算力。Linear Attention提出了一种新的归一化方式,可以替代Softmax,并且在大规模模型上运行时仍然保持高效。
- 位置编码优化: 位置编码是Transformer模型中的一个重要组成部分,用于保留序列中的顺序信息。Linear Attention对位置编码进行了优化,使其能够更好地适应线性计算,从而在保持模型性能的同时进一步降低计算复杂度。
技术优势
Linear Attention带来了以下几个显著的优势:
- 线性计算复杂度:与传统注意力机制的O(n^2)相比,Linear Attention将计算复杂度降低到了O(n),使得模型在处理超长序列时仍能保持高效运行。
- 高效的长序列处理能力:得益于线性计算复杂度,Linear Attention能够处理极长的输入序列(例如超过10万token的输入),而不需要担心计算资源的瓶颈。
- 更好的资源利用:由于计算效率的提升,Linear Attention能够在相同的资源条件下处理更多的数据,从而加速模型的训练和推理过程,这对于大规模模型的训练尤为重要。
MiniMax在其最新的模型中成功实现了Linear Attention技术,并将其应用于大规模的模型训练和推理中。MiniMax的团队通过创新的归一化方法和位置编码技术,使得Linear Attention成为可能,并成功开发出能够比肩国际顶级模型(如GPT-4)的新一代模型。
在实际性能测试中,使用Linear Attention的模型在处理10万token的输入时,处理效率可达非Linear Attention模型的2-3倍,且随着输入长度的增加,效率提升更加明显。这使得MiniMax的模型能够在长文本生成、复杂任务处理等场景中表现出色,并且在处理大规模、多步骤的复杂任务时,错误率显著降低。