

英伟达(NVIDIA)推出了Mistral-NeMo-Minitron 8B,这是一款由英伟达与Mistral AI合作开发的Mistral NeMo 12B模型的紧凑版本。不仅精度高,而且计算效率高,可在 GPU 加速的数据中心、云和工作站上运行模型。
通过剪枝和蒸馏技术优化,这款小型模型在保持尖端精度的同时,降低了计算成本,并且可以在工作站和笔记本电脑等设备上实现实时性能。
Mistral-NeMo-Minitron 8B可以作为英伟达NIM微服务提供,适用于各种应用,包括AI驱动的聊天机器人、虚拟助手和内容生成器。
与更大的模型不同,小型语言模型可以实时运行在工作站和笔记本电脑上。这使得资源有限的组织能够更轻松地在其基础设施中部署生成式AI能力,同时优化成本、运营效率和能源使用。在边缘设备上本地运行语言模型也带来了安全优势,因为数据不需要从边缘设备传输到服务器。
开发者可以使用标准应用编程接口(API)将Mistral-NeMo-Minitron 8B打包为NVIDIA NIM微服务开始使用,或者从Hugging Face下载模型。不久后,还将提供一个可下载的NVIDIA NIM,能在任何GPU加速系统上几分钟内部署。
模型优化
Mistral-NeMo-Minitron 8B 的模型优化是通过以下两个关键步骤实现的:
- 宽度剪枝 (Width Pruning):
- 目的: 宽度剪枝的目的是在不显著影响模型性能的前提下,减小模型的大小。它通过减少模型中神经元的数量以及注意力头和嵌入通道的数量来实现这一目标。
- 过程: 在对Mistral NeMo 12B模型进行剪枝时,研究人员计算了每个注意力头、嵌入通道和MLP隐藏维度的重要性分数,并根据这些分数对模型进行剪枝。具体而言,MLP中间维度从14,336减少到11,520,隐藏大小从5,120减少到4,096,同时保留了注意力头的数量和层数。
- 知识蒸馏 (Knowledge Distillation):
- 目的: 知识蒸馏是为了将大型复杂模型(通常称为教师模型)的知识转移到一个较小的学生模型中,从而创建一个更高效的模型,同时保留原始大模型的大部分预测能力。
- 过程: 在剪枝后,研究团队使用了3800亿个标记的数据集对模型进行了轻量再训练。再训练使用了峰值学习率为1e-4、最小学习率为4.5e-7、60步线性预热、余弦衰减调度以及768的全局批次大小。这种蒸馏过程帮助恢复了剪枝后可能丢失的模型精度。
通过这种剪枝与蒸馏的结合,Mistral-NeMo-Minitron 8B模型在显著减少计算成本的同时,依然保持了高精度的预测能力。这种优化策略为构建更小、更高效的AI模型提供了一个有效的框架。
性能表现
Mistral-NeMo-Minitron 8B 模型在多个基准测试中表现出色,其性能表现可以从以下几个方面来理解: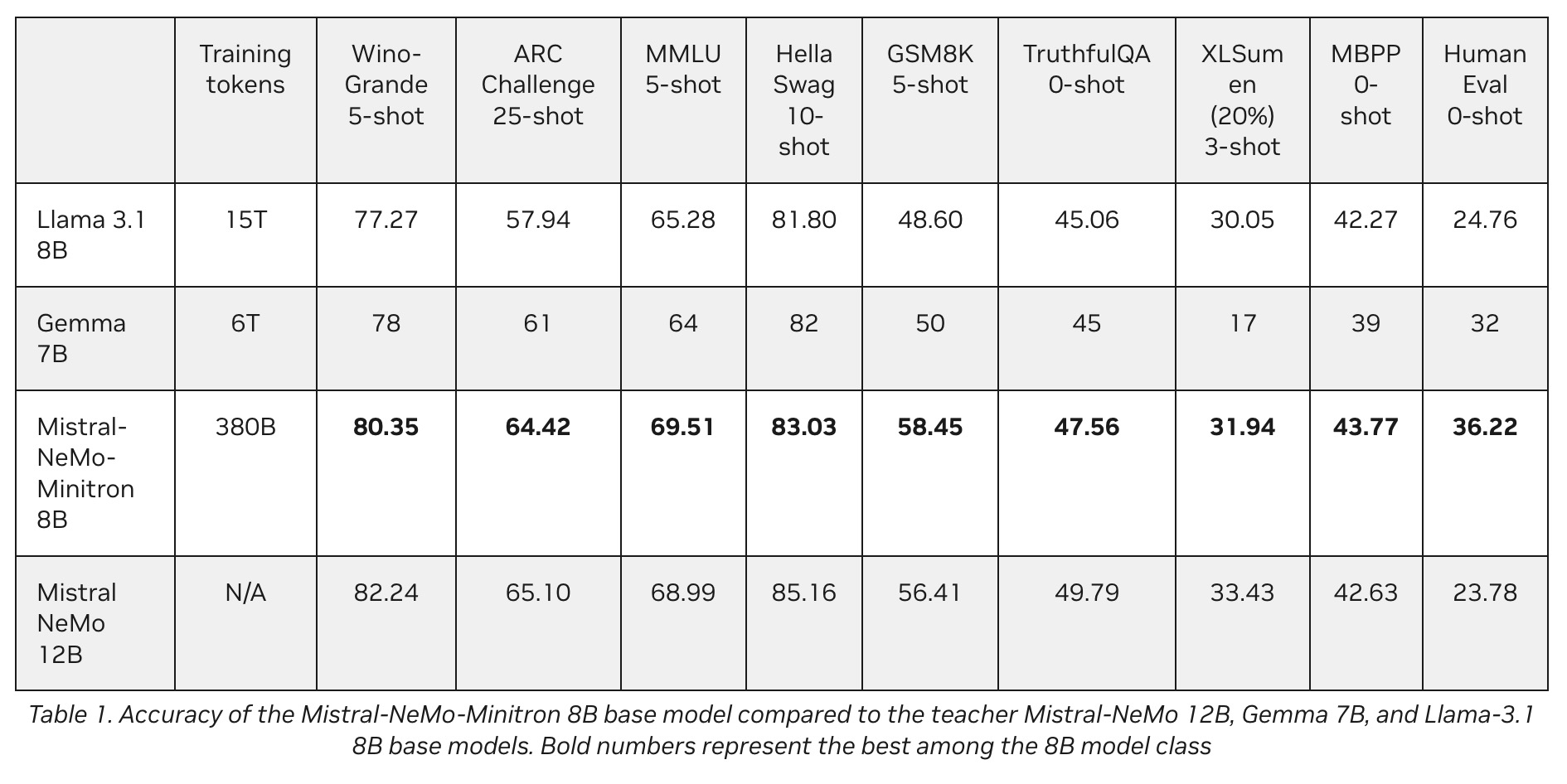

- 领先的基准测试成绩:
- 九个流行的基准测试: Mistral-NeMo-Minitron 8B 在九个广泛使用的基准测试中取得了优异成绩,这些测试涵盖了语言理解、常识推理、数学推理、摘要生成、编程代码生成以及生成真实答案的能力。
- 对比结果: 在这些基准测试中,Mistral-NeMo-Minitron 8B 基础模型的表现接近甚至优于它的“大哥” Mistral NeMo 12B 模型。例如,在WinoGrande、ARC Challenge、MMLU、HellaSwag、GSM8K、TruthfulQA、XLSum en、MBPP 和 HumanEval 等测试中,该模型表现出色,尤其在WinoGrande和GSM8K测试中,8B模型的表现超过了许多同类模型。
- 高效的计算成本:
- 训练效率: 通过剪枝和知识蒸馏技术,Mistral-NeMo-Minitron 8B 模型不仅在性能上接近12B的模型,还显著减少了计算资源的需求。相比于从零开始训练一个同等规模的模型,通过剪枝和蒸馏再训练的方式,可以节省高达40倍的计算资源。
- 适应性强:
- 结构紧凑: Mistral-NeMo-Minitron 8B 的8B参数模型具备紧凑的结构,适合在需要高效AI处理的应用场景中使用,如嵌入式设备、移动设备或边缘计算设备。
- 精度与效率平衡: 该模型在保留高精度的同时,大大提升了运行效率,适合需要低延迟、高响应速度的应用,例如实时聊天机器人、虚拟助手和内容生成工具。
NVIDIA还在本周宣布了Nemotron-Mini-4B-Instruct,这是另一个为NVIDIA GeForce RTX AI PC和笔记本电脑上优化的低内存使用率和更快响应时间的小型语言模型。该模型作为NVIDIA NIM微服务可用于云端和设备端部署,并且是NVIDIA ACE的一部分,这是一套由生成式AI驱动的提供语音、智能和动画的数字人技术。
通过浏览器或API在ai.nvidia.com体验这两个作为NIM微服务的模型。
官方介绍:https://blogs.nvidia.com/blog/mistral-nemo-minitron-8b-small-language-model/