
微软发布Phi-3.5-vision 轻量级、多模态的开源模型,其属于Phi-3模型家族。该模型专为需要文本和视觉输入的应用而设计,重点处理高质量、高推理密度的数据。它支持128K的上下文长度,并经过严格的微调和优化过程,旨在在内存或计算资源有限、低延迟要求高的环境中广泛用于商业和研究领域。
该模型具备广泛的图像理解、光学字符识别(OCR)、图表和表格解析、多图像或视频剪辑摘要等功能,非常适合多种AI驱动的应用,在图像和视频处理相关的基准测试中表现出显著的性能提升。
Phi-3.5-vision 模型使用高质量的教育数据、合成数据和经过严格筛选的公开文档进行训练,确保数据质量和隐私。其架构包括一个42亿参数的系统,集成了图像编码器、连接器、投影器和Phi-3 Mini语言模型。
Phi-3.5-vision包括三款模型:
1. Phi-3.5 Mini Instruct:
- 参数量:3.82亿参数。
- 设计目标:这是一个轻量级AI模型,主要针对需要在内存或计算资源有限的环境中进行强大推理的场景,比如代码生成、数学问题求解以及基于逻辑的推理任务。
- 上下文长度:支持128K的token上下文长度。
- 性能表现:尽管模型体积较小,但在多语言和多轮对话任务中表现出色,在“长上下文代码理解”基准测试(RepoQA)中,超越了类似大小的模型(如Llama-3.1-8B-instruct和Mistral-7B-instruct)。
- 应用场景:特别适合那些对计算资源要求较高的场景,能在保证推理能力的前提下减少资源消耗。
2. Phi-3.5 MoE (Mixture of Experts):
- 参数量:41.9亿参数(具有42亿活动参数,但实际活跃参数为6.6亿)。
- 设计目标:这是微软首次推出的“专家混合”模型(Mixture of Experts),结合了多个不同类型的模型,各自专注于不同的任务。这种架构使得该模型能够在多语言理解、代码和数学推理等复杂任务中表现出色。
- 上下文长度:支持128K的token上下文长度。
- 性能表现:在多个基准测试中超越了体积更大的模型,如在大规模多任务语言理解(MMLU)测试中,Phi-3.5 MoE 在STEM、人文学科和社会科学等多领域的5-shot测试中表现优异,击败了GPT-4o mini。
- 应用场景:适用于需要处理复杂AI任务的应用,尤其是在多语言环境和复杂推理场景中表现突出。
3. Phi-3.5 Vision Instruct:
- 参数量:4.15亿参数。
- 设计目标:这款多模态模型集成了文本和图像处理功能,特别适合处理诸如图像理解、光学字符识别(OCR)、图表和表格解析以及视频摘要等任务。
- 上下文长度:同样支持128K的token上下文长度。
- 性能表现:该模型在多帧图像处理和复杂视觉任务中表现出色,能够高效地管理复杂的多模态任务。模型的训练数据包括合成数据和经过过滤的公开数据,确保了高质量和推理密度。
- 应用场景:主要应用于需要综合处理视觉和文本数据的复杂任务中,如多帧图像对比和视频内容总结。
主要功能特点
- 图像理解:
- 具备对单张图像和多张图像进行详细理解的能力,能够识别图像中的内容,并提供相关描述和分析。
- 可用于一般的图像理解任务,如识别图像中的物体、场景或其他重要元素。
- 光学字符识别 (OCR):
- 能够从图像中提取和识别文本内容,适用于处理包含文字的图像,如文档扫描、图像中的标注等。
- 图表和表格理解:
- 可解析图表和表格中的信息,帮助用户从复杂的图形数据中提取有用的见解。
- 适用于财务报表分析、数据可视化理解等场景。
- 多图像对比:
- 能够对多张图像进行对比分析,找出图像之间的异同点。
- 适用于多帧图像或视频片段的比较和总结,支持复杂的多图像推理。
- 多图像或视频剪辑摘要:
- 提供对多张图像或视频片段的综合总结功能,能够提炼出关键内容,生成简明的总结性描述。
- 非常适合用于新闻报道、视频编辑或任何需要快速理解和总结大量视觉内容的应用场景。
- 高效的推理能力:
- 强调推理密度,能够在处理复杂问题时提供深入且有逻辑的推理结果。
- 适用于需要高质量推理的场景,如科学研究、复杂问题求解等。
- 低延迟和内存优化:
- 针对计算资源受限和需要低延迟响应的环境进行了优化,使其能够在各种设备和场景下高效运行。
- 非常适合用于需要快速响应的实时应用,如互动式AI系统、嵌入式系统等。
模型架构:
- 参数量:Phi-3.5-vision 拥有 42亿个参数,结构包括图像编码器、连接器、投影器和Phi-3 Mini语言模型。
- 输入:该模型接受文本和图像作为输入,最适合使用对话格式的提示进行操作。
- 上下文长度:支持长达128K的上下文长度(以token为单位)。
- GPU:训练时使用了256个NVIDIA A100-80G GPU。
- 训练时间:模型训练时间为6天。
训练数据:
- 数据规模:模型的训练数据包括5000亿个token(包括视觉和文本token)。
- 数据来源:
- 公开文档:包含了经过严格筛选的高质量公开文档。
- 教育数据和代码:选择了高质量的教育数据和代码进行训练。
- 图像-文本数据:使用高质量的图像-文本混合数据进行训练。
- 合成数据:创建了用于教学的合成数据,涵盖数学、编码、常识推理、世界通识(如科学、日常活动、心智理论等),以及新创建的图像数据(如图表、表格、幻灯片)和多图像及视频数据(如短视频剪辑、两张相似图像对等)。
- 人工监督数据:收集了覆盖广泛主题的高质量对话格式监督数据,以反映人类偏好,如指令遵循、真实度、诚实度和有用性。
训练方法:
- 微调过程:Phi-3.5-vision 经过了严格的微调,包括监督微调(SFT)和基于人类反馈的强化学习(RLHF)方法,确保模型在不同任务中的表现能够满足高标准的安全性和准确性要求。
- 数据过滤:在数据收集过程中,经过了严格的过滤流程,以确保训练数据的高质量,并且避免包含任何潜在的个人信息,保护隐私。
- 模型稳定性:该模型为静态模型,训练数据集的截止日期为2024年3月15日。后续可能会发布优化版本,以进一步提升模型性能。
基准测试结果:
Phi-3.5-vision 在多项基准测试中展示了其在图像理解、推理和文本生成任务中的出色表现。以下是一些关键基准测试的具体成绩: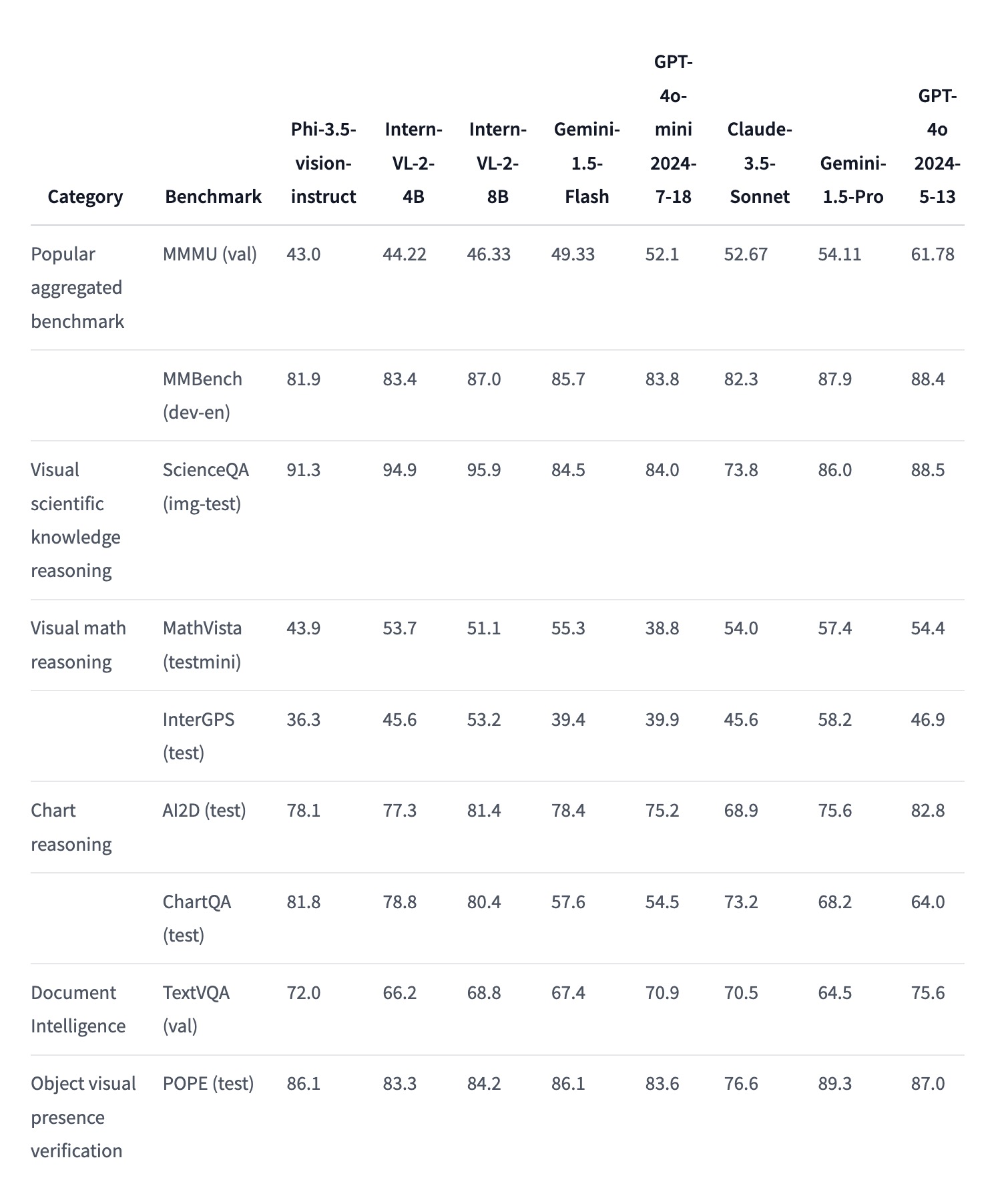

- MMMU (Multi-Modal Multi-Image Understanding):
- 得分: 43.0(相较于之前版本40.2有所提升)
- 说明: 该基准测试评估模型在多模态、多图像理解任务中的表现,Phi-3.5-vision在这一测试中的提升显示了其在处理复杂图像理解任务时的增强能力。
- MMBench (Multi-Modal Benchmark):
- 得分: 81.9(相较于之前版本80.5有所提升)
- 说明: 该测试衡量了模型在多模态任务中的整体表现,Phi-3.5-vision的高得分表明其在多模态任务中的广泛适用性和强大性能。
- TextVQA (Text-based Visual Question Answering):
- 得分: 72.0(相较于之前版本70.9有所提升)
- 说明: 该基准测试评估模型在处理包含文本的图像时的问答能力,Phi-3.5-vision 的改进表明其在视觉问答任务中的准确性有所提升。
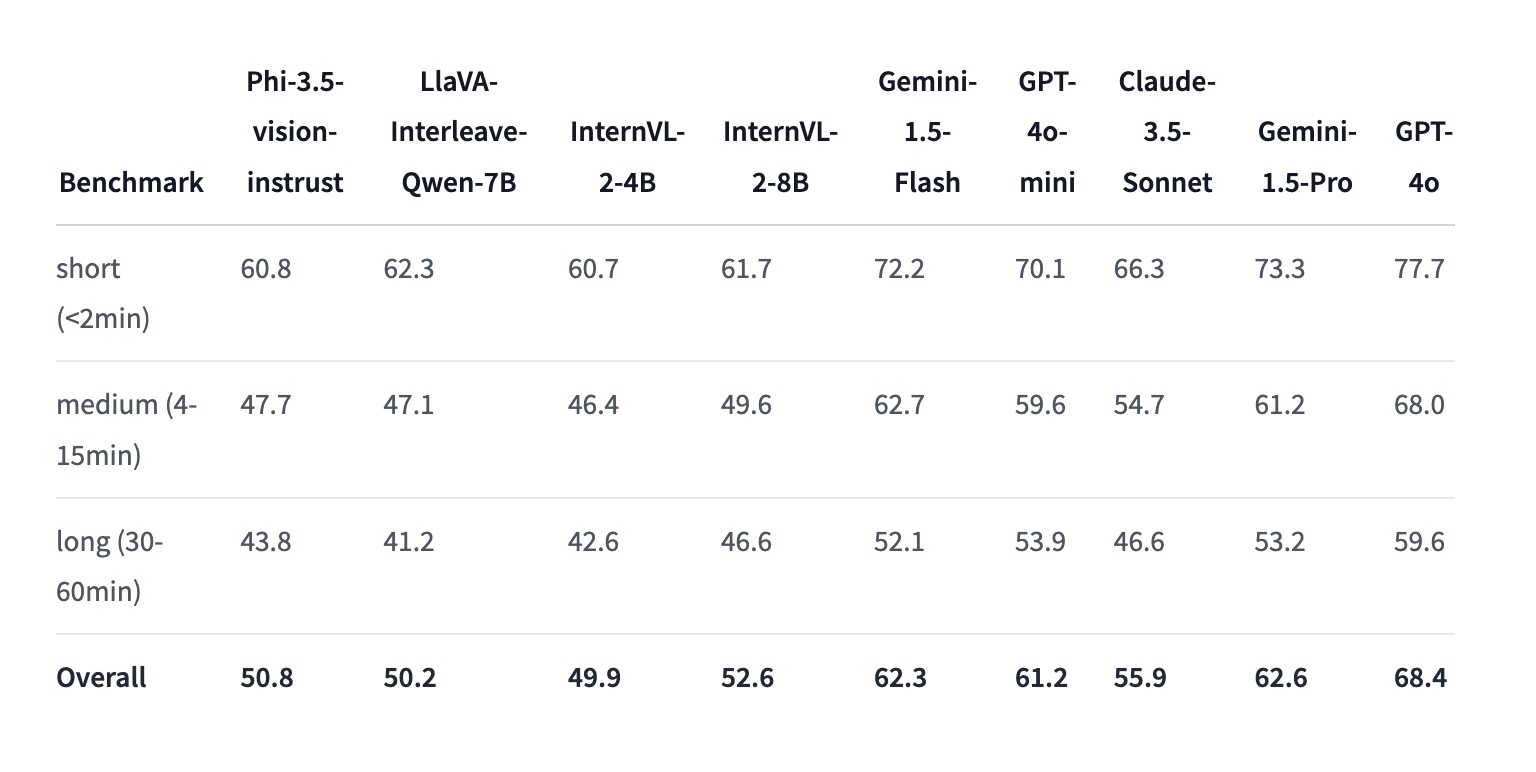
- 视频处理能力 (Video-MME):
- 短视频(<2分钟): 60.8
- 中等长度视频(4-15分钟): 47.7
- 长视频(30-60分钟): 43.8
- 总体得分: 50.8
- 说明: Phi-3.5-vision在视频数据处理上的表现优异,尤其是在短视频的处理上表现突出,能够有效分析和总结视频内容。

BLINK基准测试
BLINK 是一个用于评估多模态大语言模型(Multimodal LLMs)性能的基准测试,包含14个视觉任务。这些任务是人类可以快速解决的,但对当前的多模态大语言模型来说仍然具有挑战性。BLINK 基准测试的设计旨在测试模型在处理复杂视觉信息时的能力,并在以下几个方面对模型进行评估:
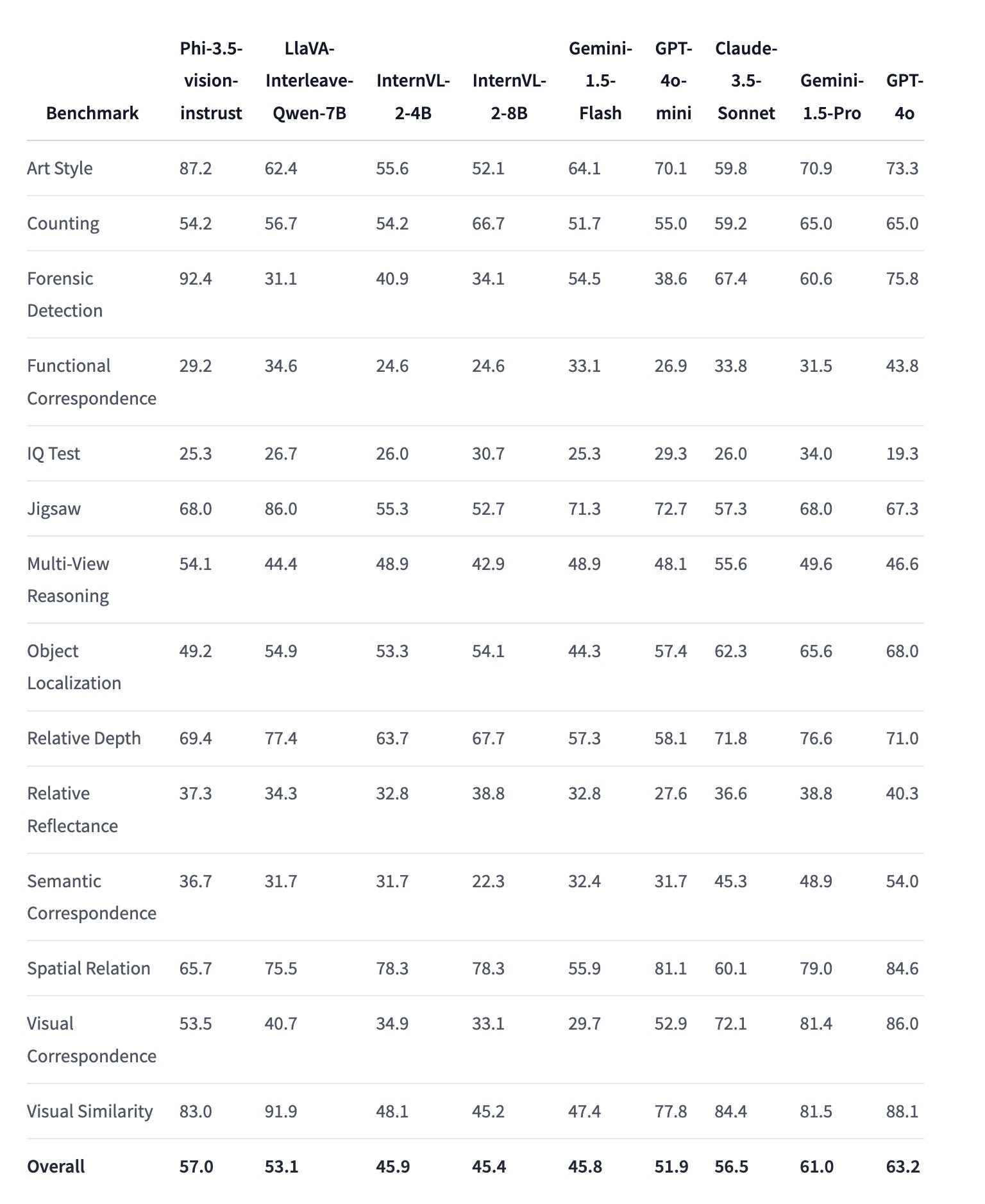

在BLINK基准测试中,Phi-3.5-vision模型表现出色,在许多任务上取得了高分。例如,在艺术风格识别、法医检测、相对深度、空间关系等任务中表现尤为突出,显示了其在复杂视觉任务中的强大处理能力。
这个基准测试提供了一个多维度的视角,帮助研究人员了解和改进多模态大语言模型的性能,使其更接近人类在视觉任务上的表现。
主要任务类型:
- 艺术风格识别(Art Style Recognition):识别和区分图像的艺术风格。
- 计数(Counting):准确地数出图像中相同类型物体的数量。
- 法医检测(Forensic Detection):识别图像中的异常或篡改迹象。
- 功能对应(Functional Correspondence):检测图像中物体之间的功能性关系。
- 智力测试(IQ Test):通过图像推理来回答智力测试题目。
- 拼图(Jigsaw Puzzle):解决图像拼图,重建完整图像。
- 多视图推理(Multi-View Reasoning):通过多个视角的图像来进行推理。
- 物体定位(Object Localization):在图像中准确定位特定的物体。
- 相对深度(Relative Depth):判断图像中物体的相对深度。
- 相对反射率(Relative Reflectance):判断图像中物体的反射率差异。
- 语义对应(Semantic Correspondence):识别图像中物体或场景的语义对应关系。
- 空间关系(Spatial Relation):理解和判断图像中物体之间的空间关系。
- 视觉对应(Visual Correspondence):判断两个或多个图像之间的视觉相似性或一致性。
- 视觉相似性(Visual Similarity):评估不同图像之间的视觉相似度。
与其他模型的对比:
- Phi-3.5-vision与竞争模型(如LlaVA-Interleave-Qwen、InternVL等)相比,在多模态和视觉任务中的表现更为突出。特别是在多帧图像理解、图像比较和视频摘要等任务中,该模型不仅在同等规模的模型中表现优异,甚至在某些情况下超过了更大规模的模型。
性能提升的具体应用场景:
- 多帧图像理解:Phi-3.5-vision对多张图像进行综合分析和推理的能力非常强,适用于复杂图像对比、视频片段分析等任务。
- 复杂视觉推理:该模型在处理具有挑战性的视觉推理任务(如科学知识推理、数学推理)中表现尤为突出,能够提供高质量的推理结果。
- 文本生成和视觉问答:在需要文本生成和回答基于图像的问题时,Phi-3.5-vision能够提供准确和上下文相关的回答。
模型下载:https://huggingface.co/microsoft/Phi-3.5-vision-instruct