Salesforce AI宣布开源🍃MINT-1T,这是首个拥有一万亿个Token的多模态交织数据集。包含一万亿个文本标记和34亿张图像,比现有开源数据集规模大10倍。此外,还纳入了 PDF 和 ArXiv 论文等之前尚未开发的资源。
多模态交织文档是包含图像和文本的序列结构,能够训练跨图像和文本模式推理的大型多模态模型。
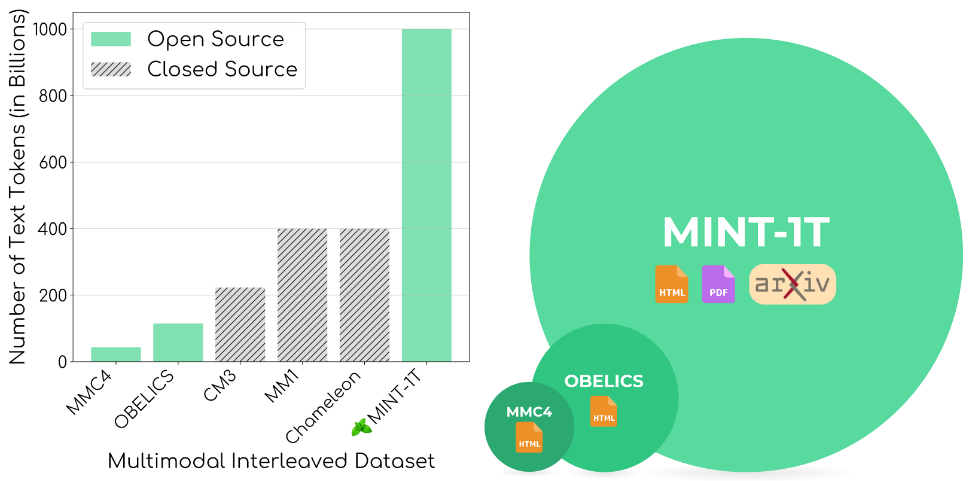

- 规模:MINT-1T的数据量达到一万亿个Token,比之前最大的开源数据集(如 OBELICS 和 MMC4 )扩大了近10倍,这使得研究人员可以训练更大的多模态模型。
- 多样性:MINT-1T不仅包含HTML文档,还包括PDF文档和ArXiv论文。这些额外的文档来源显著提高了科学文档的覆盖率,丰富了数据集的多样性。
数据集内容
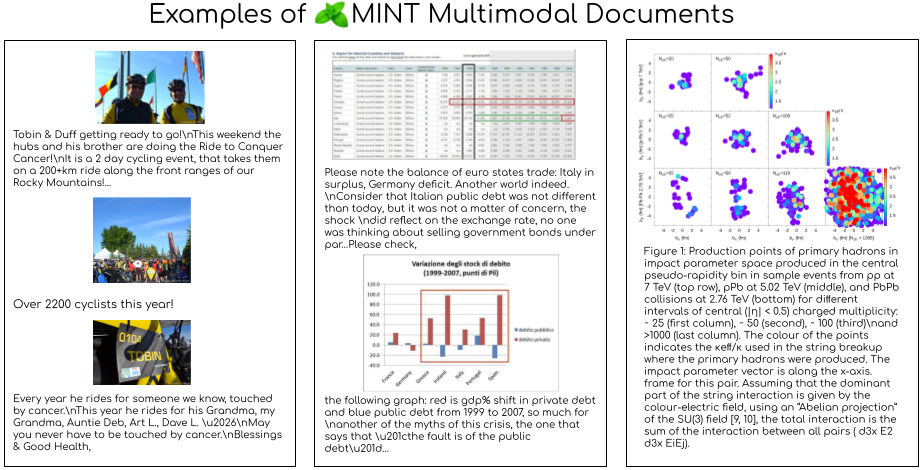
MINT-1T 数据集的构建涉及多种来源的数据收集、处理和过滤步骤,以确保数据的高质量和多样性。

-
HTML 文档:
- 从 CommonCrawl 中提取 HTML 文档。
- 处理时间范围从 2017 年 5 月到 2024 年 4 月,使用了 2018 年 10 月到 2024 年 4 月的完整数据和之前年份的部分数据。
- 过滤条件:排除没有图像或超过30张图像的文档,以及图像URL包含不合适子串(如 logo, avatar, porn, xxx)的文档。
-
PDF 文档:
- 从 CommonCrawl WAT 文件中提取 PDF 文档,处理时间范围从 2023 年 2 月到 2024 年 4 月。
- 使用 PyMuPDF 工具下载和解析 PDF 文件。
- 过滤条件:排除大于 50MB 或超过 50 页的 PDF,排除没有文本的页面,并根据页面上的文本块和图像的边界框位置来确定图像的插入顺序。
-
ArXiv 文档:
- 使用 LaTeX 源代码构建交错文档。
- 解析 LaTeX 代码中的 figure 标签,将图像与文本交错。
- 处理多文件论文,识别主文件并清理 LaTeX 代码(如移除导入、参考文献、表格和引用标签)。
数据过滤与去重
-
文本质量过滤:
- 使用 FastText 模型进行语言识别,排除非英语文档。
- 移除包含不合适子串的 URL(如 NSFW 内容)。
- 应用来自 RefinedWeb 和 MassiveText 的文本过滤规则,移除重复的 n-grams 和低质量文档。
-
图像过滤:
- 尝试下载所有 HTML 数据集中的图像 URL,移除无法检索的链接。
- 过滤条件:移除小于 150 像素的图像(避免噪音图像如 logo 和图标)和大于 20,000 像素的图像(通常为无关图像)。
- 对 HTML 文档,移除长宽比大于 2 的图像;对 PDF 文档,调整阈值为 3 以保留科学图表。
-
安全过滤:
- 应用 NSFW 图像检测器,发现单个 NSFW 图像则移除整个文档。
- 移除个人可识别信息,如电子邮件地址和 IP 地址,并替换为模板或随机生成的无效 IP。
-
去重处理:
- 使用 Bloom Filter 进行高效的文本去重,设置误报率为 0.01,去重 13-gram 段落。
- 移除常见的 HTML 噪音句子(如 “Skip to content” 或 “Blog Archive”)。
- 基于 SHA256 哈希值进行图像去重,移除在一个快照中出现超过十次的图像,以及单个文档中重复的图像。
- 数据处理期间,平均使用 2350 个 CPU 核心,总共使用约 420 万 CPU 小时构建数据集。

- 预训练:使用MINT-1T预训练了XGen-MM多模态模型,50%的Token来自HTML文档,其余来自PDF和ArXiv文档。
- 评估:在图像说明和视觉问答基准测试中,使用MINT-1T训练的模型表现优于之前的领先数据集OBELICS。评估结果显示,MINT-1T在保持背景一致性、对象位置合理性和对象相关性与质量方面表现优异。
数据集分析
MINT-1T 数据集在规模、数据来源多样性和质量上都有显著提升。以下是对数据集的详细分析:

-
文本标记分布:通过对50,000个文档的随机抽样分析,使用 GPT-2 的标记器计算每个文档的文本标记数量。结果显示,MINT-1T 的 HTML 子集在标记分布上与 OBELICS 相似,但 PDF 和 ArXiv 文档的平均长度明显更长。
-
图像密度:分析文档中的图像密度发现,MINT-1T 的 PDF 和 ArXiv 文档比 HTML 文档包含更多的图像,其中 ArXiv 样本的图像密度最高。
2. 数据源对文档多样性的提升
-
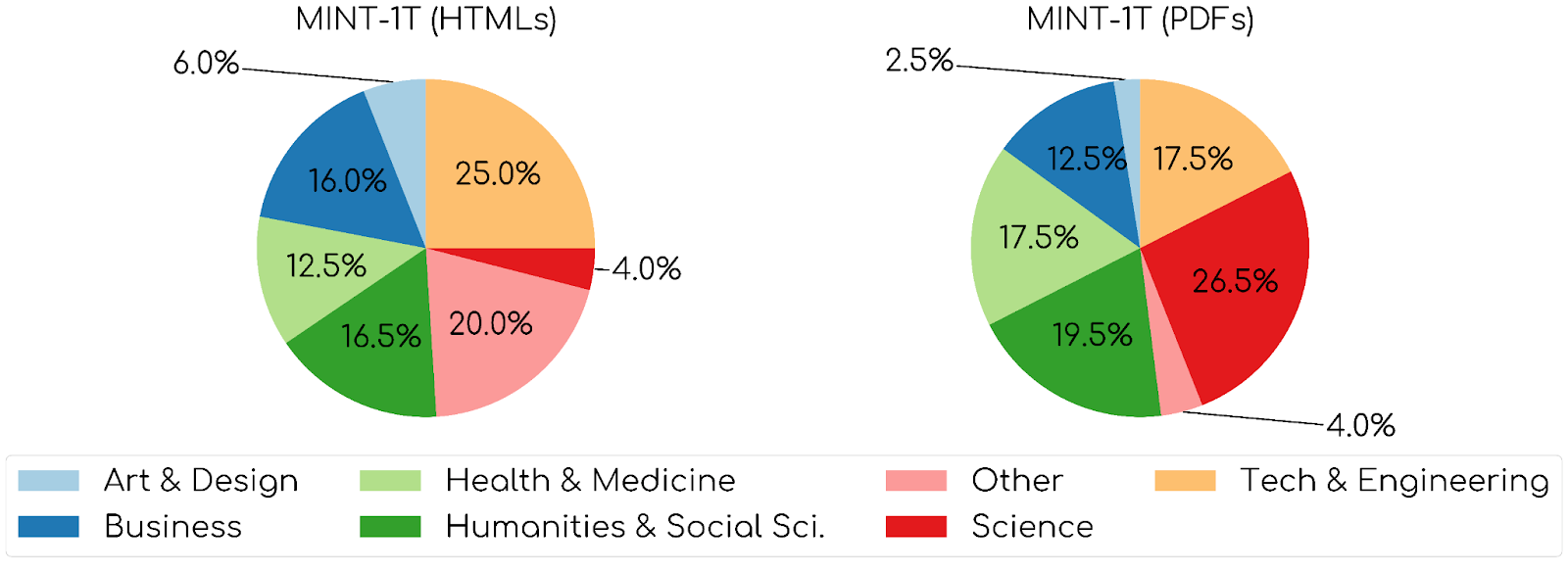
领域覆盖:使用 LDA 模型对 100,000 个文档进行主题建模,结果表明,OBELICS 数据集的文档主要集中在人文学科和社会科学,而 MINT-1T 的 HTML 子集则表现出更广泛的领域覆盖,PDF 子集则主要集中在科学和技术领域。
3. 上下文学习性能
-
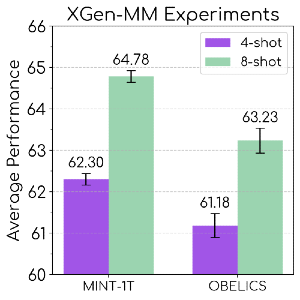
演示示例数量的影响:评估模型在使用 1 到 8 个示例时的上下文学习性能,结果显示,基于 MINT-1T 训练的模型在所有示例数量上都优于基线模型 OBELICS。
4. 不同任务上的表现
-
图像字幕生成和视觉问答:在图像字幕生成任务中,OBELICS 数据集表现更好,而在视觉问答任务中,MINT-1T 数据集显著优于其他基线。
-
不同领域的表现:在多学科多模态理解和推理基准(MMMU)上的性能分析显示,MINT-1T 在科学和技术领域的表现显著优于 OBELICS 和 MINT-1T 的 HTML 子集。
5. 影响模型架构的性能
-
XGen-MM 和 Idefics2 实验:使用不同的模型架构(XGen-MM 和 Idefics2)进行实验,结果显示,Idefics2 架构下的 MINT-1T (HTML) 在图像字幕生成和视觉问答任务上表现优异。
总结
通过以上分析,可以看出 MINT-1T 数据集在多样性、质量和规模上都显著优于现有的开源数据集,尤其在科学和技术领域表现突出。基于 MINT-1T 训练的模型在多模态任务中的表现优越,为未来的多模态研究提供了坚实的基础和丰富的资源。